1.简介
当一个表数据量很大时候,很自然我们就会想到将表拆分成很多小表,在执行查询时候就到各个小表去查,最后汇总数据集返回给调用者加快查询速度。比如电商平台订单表,库存表,由于长年累月读写较多,积累数据都是异常庞大的,这时候,我们可以想到表分区这个做法,降低运维和维护成本,提高读写性能。比如将前半年订单放一个历史分区表,不活跃库存放一个历史分区表。截止到SQL Server 2016,一张表或一个索引最多可以有15000个分区。
2.表分区
2.1分区范围
分区范围是指在要分区的表中,根据业务选择表中的关键字段做为分区边界条件,分区后,数据所在的具体位置至关重要,这样才能在需要时只访问相应的分区。注意分区是指数据的逻辑分离,不是数据在磁盘上的物理位置,数据的位置由文件组来决定,所以一般建议一个分区对应一个文件组。
2.2分区键
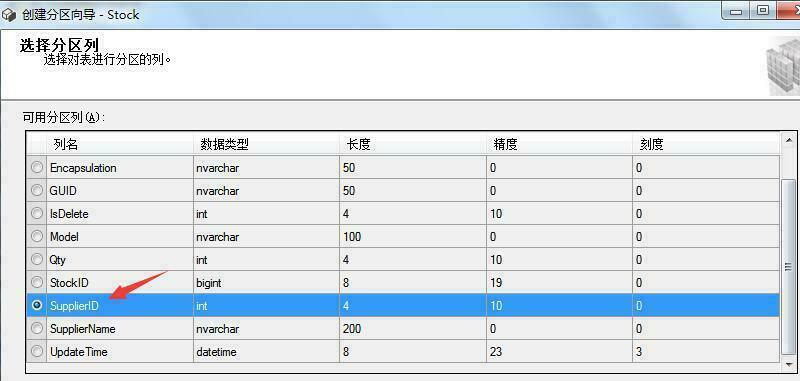
分区表中的字段可以作为分区键,比如库存表中供应商ID。对表和索引进行分区的第一步就是定义分区的关键数据。
2.3索引分区
除了对表的数据集进行分区之外,还可以对索引进行分区,使用相同的函数对表及其索引进行分区通常可以优化性能。
3.创建表分区
3.1创建文件组
在这里演示示例当中,我根据业务场景在TestDB数据库新增三个文件组,而三个文件组分别对应三个分区。而多个文件组好处是可以按照不同业务场景将数据放在对应文件组当中,优化性能同时好维护数据。文件组数量由硬件决定,最好是一个文件组对应一个分区,好维护。而通常文件组都处于不同磁盘上的,但是由于是演示,我只在一个磁盘中存放。
--创建四个文件组
ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup1
ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup2
ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup33.2指定文件组存放路径
在创建文件组之后,指定文件组存放磁盘位置,文件大小。
--创建四个ndf文件,对应到各文件组中,FILENAME文件存储路径
ALTER DATABASE [TestDB] ADD FILE(
NAME='SupIDGroupFile1',
FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile1.ndf',
SIZE=10MB,
FILEGROWTH=10MB)
TO FILEGROUP SupIDGroup1
ALTER DATABASE [TestDB] ADD FILE(
NAME='SupIDGroupFile2',
FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile2.ndf',
SIZE=10MB,
FILEGROWTH=10MB)
TO FILEGROUP SupIDGroup2
ALTER DATABASE [TestDB] ADD FILE(
NAME='SupIDGroupFile3',
FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile3.ndf',
SIZE=10MB,
FILEGROWTH=10MB)
TO FILEGROUP SupIDGroup3注(附上删除文件组T-SQL):
ALTER DATABASE [TestDB] REMOVE FILE SupIDGroupFile3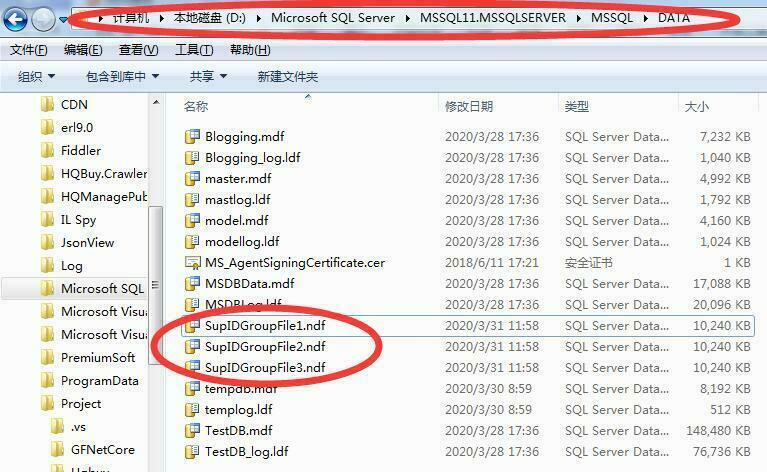
可以通过以下T-SQL语句查看文件组存放相关信息:
SELECT file_id,type,type_desc,data_space_id,name,physical_name,state_desc,size,growth
FROM sys.database_files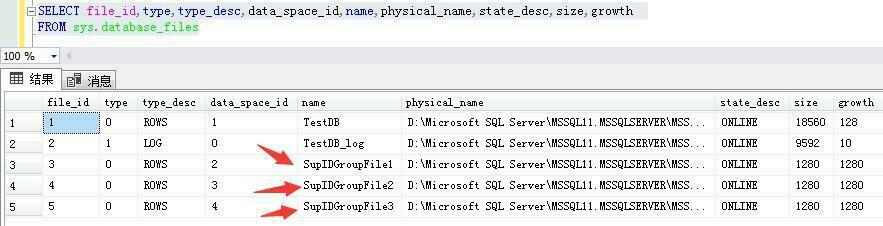
3.3创建分区函数
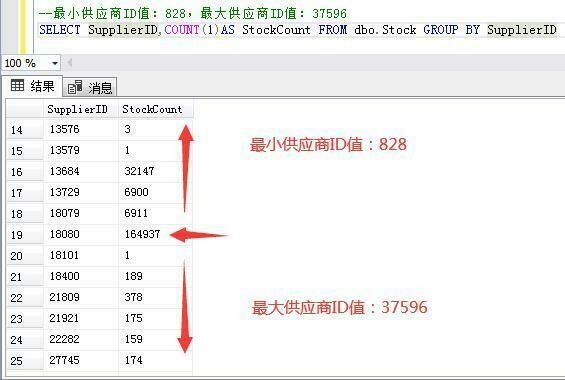
如何创建表分区边界值,我们肯定要根据业务场景来决定。比如我测试库库存表有36万左右数据,而有些供应商的库存数据远远比其他供应商大,那么我可以考虑使用供应商ID字段作为边界值分区。例如:根据T-SQL统计,18080供应商库存数据最大,那么我可以根据18080供应商上下分为三个区。
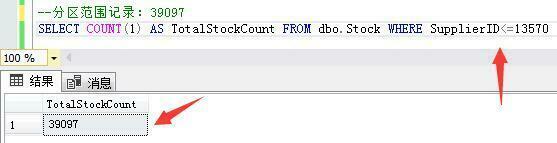
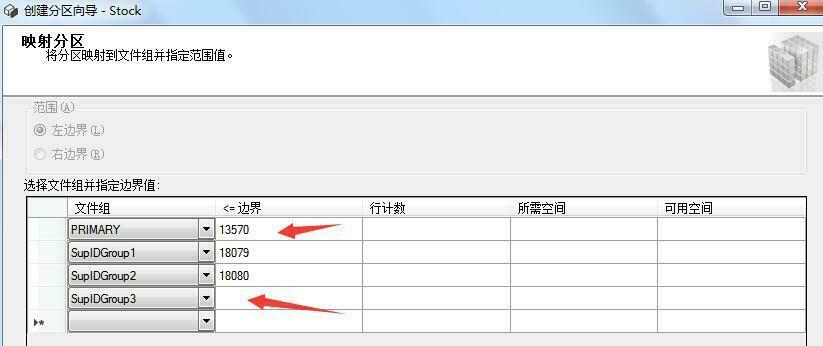
第一个分区范围记录:供应商ID小于等于13570的39097条库存数据。
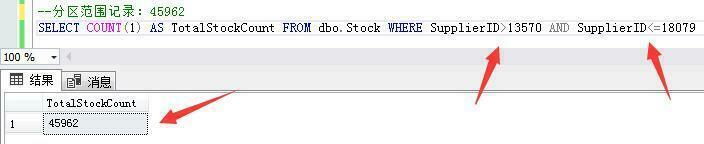
第二个分区范围记录:供应商ID大于13570和小于等于18079的45962条库存数据。
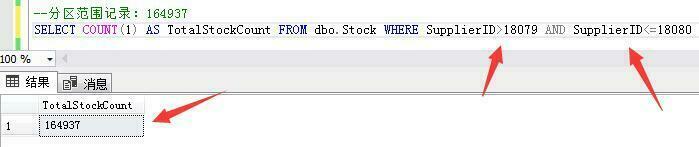
第三个分区范围记录:供应商ID大于18079小于等于18080的164937条库存数据。
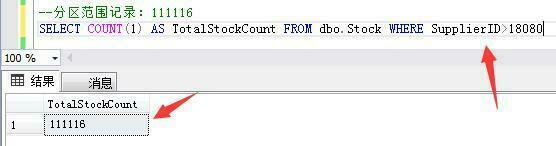
第四个分区范围记录:供应商ID大于18080的111116条库存数据。
根据上述分区范围记录,我们可以将供应商ID作为边界值设置,执行以下T-SQL语句设置边界值:
--设置边界值
CREATE PARTITION FUNCTION PF_SupplierID(int)
AS RANGE LEFT FOR VALUES (13570,18079,18080)执行完毕后如图所示:
3.4创建分区方案
执行以下T-SQL语句创建分区方案:
--创建分区方案
CREATE PARTITION SCHEME PS_SupplierID
AS PARTITION PF_SupplierID TO ([PRIMARY], [SupIDGroup1],[SupIDGroup2],[SupIDGroup3])执行完毕后如图所示:
3.5创建分区表
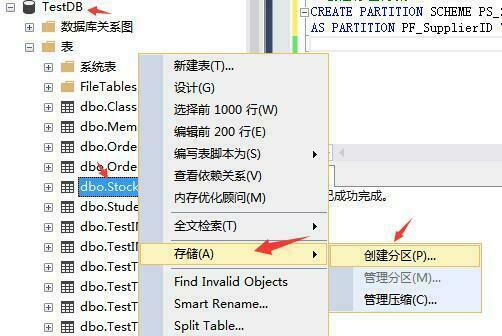
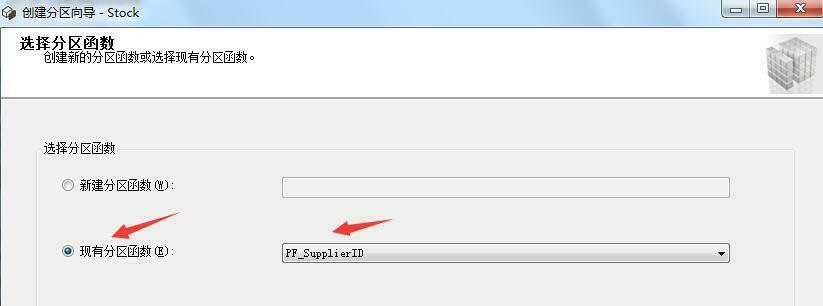
上面那些分区步骤都是为了接下来创建分区表这一步骤而准备的。废话不多说,现在我们来看看如何创建分区表。右键需要分区的表->储存->创建分区,具体步骤如下图所示:
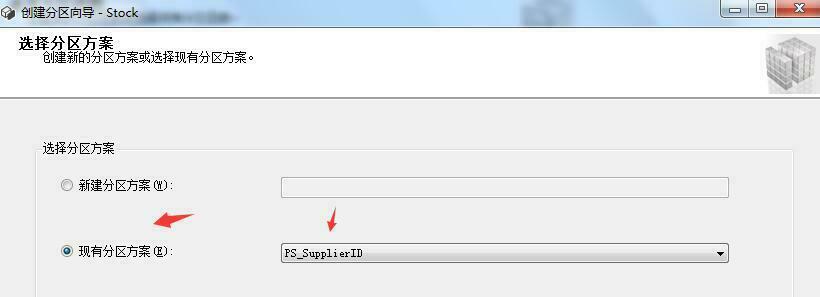
3.6创建分区索引
--创建分区索引
CREATE NONCLUSTERED INDEX [NCI_SupplierID] ON dbo.Stock
(
SupplierID ASC
)
INCLUDE ( [Model],[Brand],[Encapsulation]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO或者
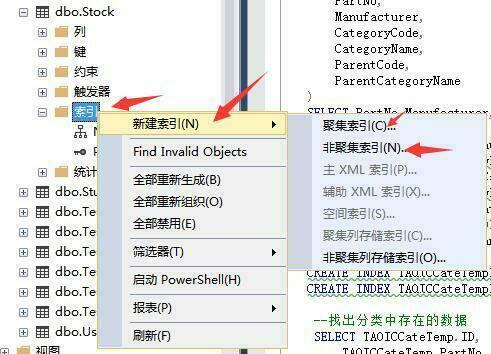
执行完毕后如图所示:
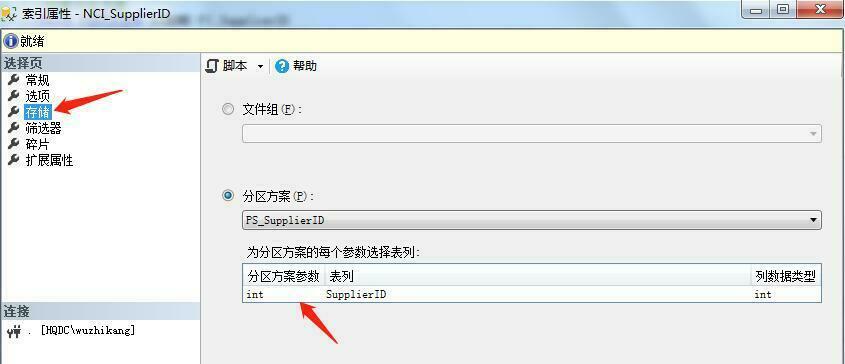
创建好索引之后,我们来看看分区情况:
--查看各分区有多少行数据
SELECT * FROM (
SELECT $PARTITION.PF_SupplierID([SupplierID]) AS Patition,COUNT(*) AS CountRows FROM dbo.Stock
GROUP BY $PARTITION.PF_SupplierID([SupplierID])
)TB ORDER BY Patition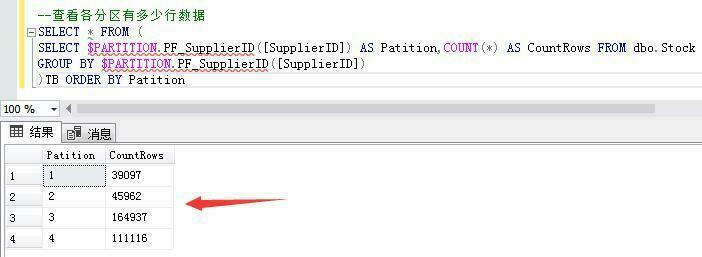
最后我们来看看加了索引之后表数据查询情况:
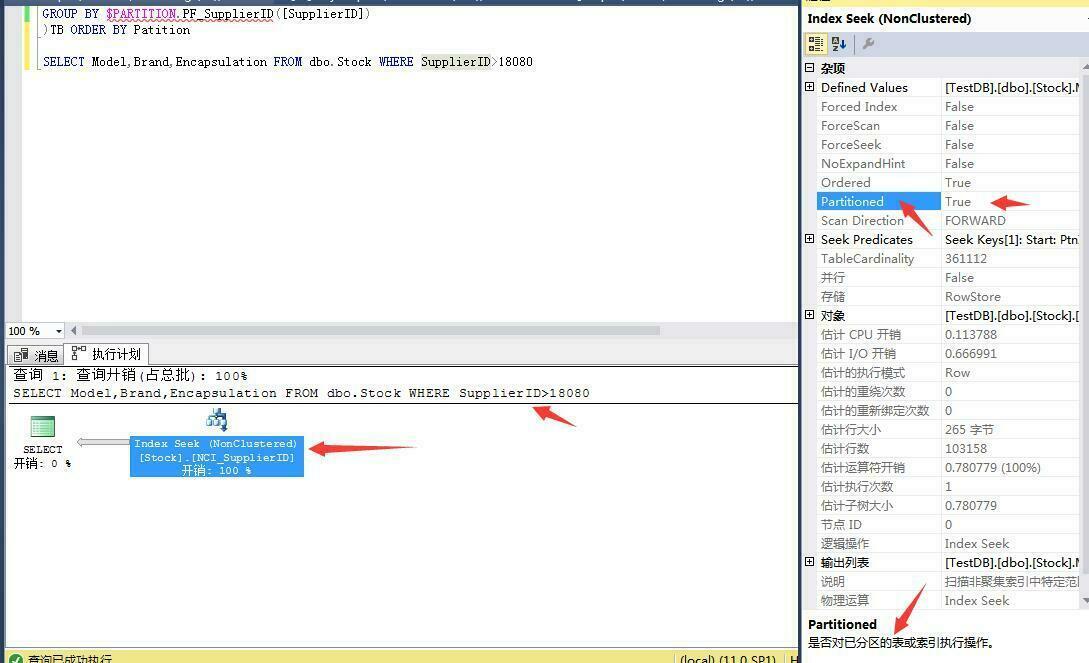
4.表分区的优缺点
优点:
- 改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
- 增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用。
- 维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可。
- 均衡I/O:可以把不同的分区映射到不同磁盘以平衡I/O,改善整个系统性能。
缺点:
分区表相关:已经存在的表没有方法可以直接转化为分区表。