分析fastcache和freecache(一)
fastcache和freecache是两个比较简单的缓存实现,下面分析一下各自的实现,并学习一下其实现中比较好的方式。
fastcache
概述
fastcache是一个简单库,核心文件也就两个:fastcache.go和bigcache.go。其中后者是对前者场景的扩展,其实就是将大于64KB 的数据分段存储。参见下面Limitations的第二条。
Limitations
- Keys and values must be byte slices. Other types must be marshaled before storing them in the cache.
- Big entries with sizes exceeding 64KB must be stored via distinct API.
- There is no cache expiration. Entries are evicted from the cache only on cache size overflow. Entry deadline may be stored inside the value in order to implement cache expiration.
根据官方的性能测试报告,其读写性能比较均衡,远好于标准的Go map和sync.Map:
GOMAXPROCS=4 go test github.com/VictoriaMetrics/fastcache -bench='Set|Get' -benchtime=10s
goos: linux
goarch: amd64
pkg: github.com/VictoriaMetrics/fastcache
BenchmarkBigCacheSet-4 2000 10566656 ns/op 6.20 MB/s 4660369 B/op 6 allocs/op
BenchmarkBigCacheGet-4 2000 6902694 ns/op 9.49 MB/s 684169 B/op 131076 allocs/op
BenchmarkBigCacheSetGet-4 1000 17579118 ns/op 7.46 MB/s 5046744 B/op 131083 allocs/op
BenchmarkCacheSet-4 5000 3808874 ns/op 17.21 MB/s 1142 B/op 2 allocs/op
BenchmarkCacheGet-4 5000 3293849 ns/op 19.90 MB/s 1140 B/op 2 allocs/op
BenchmarkCacheSetGet-4 2000 8456061 ns/op 15.50 MB/s 2857 B/op 5 allocs/op
BenchmarkStdMapSet-4 2000 10559382 ns/op 6.21 MB/s 268413 B/op 65537 allocs/op
BenchmarkStdMapGet-4 5000 2687404 ns/op 24.39 MB/s 2558 B/op 13 allocs/op
BenchmarkStdMapSetGet-4 100 154641257 ns/op 0.85 MB/s 387405 B/op 65558 allocs/op
BenchmarkSyncMapSet-4 500 24703219 ns/op 2.65 MB/s 3426543 B/op 262411 allocs/op
BenchmarkSyncMapGet-4 5000 2265892 ns/op 28.92 MB/s 2545 B/op 79 allocs/op
BenchmarkSyncMapSetGet-4 1000 14595535 ns/op 8.98 MB/s 3417190 B/op 262277 allocs/op
fastcache.go分析
fastcache的数据结构相对比较简单,主要内容如下(省去了统计相关的结构体成员):
type Cache struct {
buckets [bucketsCount]bucket
...
}
type bucket struct {
mu sync.RWMutex
// chunks is a ring buffer with encoded (k, v) pairs.
// It consists of 64KB chunks.
chunks [][]byte
// m maps hash(k) to idx of (k, v) pair in chunks.
m map[uint64]uint64
// idx points to chunks for writing the next (k, v) pair.
idx uint64
// gen is the generation of chunks.
gen uint64
...
}
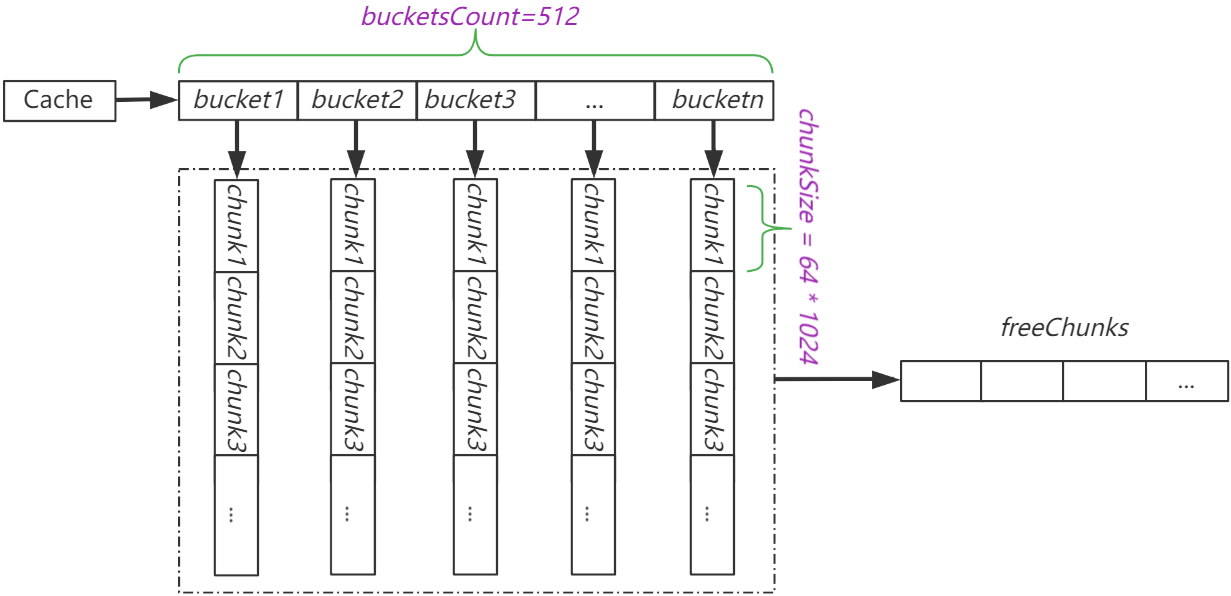
Cache结构体中包含长度为512的buckets,bucket中包含存储数据的chunks数组。fastcache没有缓存超时机制,chunks为ringbuffer,当chunks满数据之后,新来的数据会放到chunk1中,以此类推。从这方面看,fastcache并没有什么神奇之处,但cache说白了也就2件事:
- 快速检索数据,包括快速确定写入的内存以及快速查找所需的数据
- 高效利用内存,不产生过多的内存碎片
后面看下fastcache如何利用bucket.m、bucket.idx和bucket.gen这三个参数来实现快速检索数据,以及如何使用freeChunks来减少内存预分配。
Cache的初始化
Cache中的buckets的长度以及bucket中单个chunk的大小是固定的,入参的maxBytes仅会影响bucket.chunks的长度,即bucket中的chunk数目。从Cache结构体中可以看到其buckets的长度为bucketsCount,即512个。
func New(maxBytes int) *Cache {
if maxBytes <= 0 {
panic(fmt.Errorf("maxBytes must be greater than 0; got %d", maxBytes))
}
var c Cache
maxBucketBytes := uint64((maxBytes + bucketsCount - 1) / bucketsCount)
for i := range c.buckets[:] {
c.buckets[i].Init(maxBucketBytes)
}
return &c
}
下面是bucket的初始化方法,需要注意的是其仅仅初始化了b.chunks的大小,并没有初始化单个chunk的内存空间(即chunkSize字节)。chunk的初始化是在实际使用时从freeChunks申请的,这样可以避免预先分配冗余内存。这种方式有点类似底层的虚拟内存的概念,只有在真正使用的时候才会分配内存。后面会看到freeChunks是如何申请内存的。
func (b *bucket) Init(maxBytes uint64) {
if maxBytes == 0 {
panic(fmt.Errorf("maxBytes cannot be zero"))
}
if maxBytes >= maxBucketSize {
panic(fmt.Errorf("too big maxBytes=%d; should be smaller than %d", maxBytes, maxBucketSize))
}
maxChunks := (maxBytes + chunkSize - 1) / chunkSize
b.chunks = make([][]byte, maxChunks)
b.m = make(map[uint64]uint64)
b.Reset()
}
chunk内存的申请和释放
上面说了在Cache初始化时并没有为chunk申请内存,在实际使用chunk的时候(Set)才会申请内存。下面是chunk的内存初始化方式。可以看到fastcache中使用unix.Mmap来为chunk申请内存,这样作可以避免GC的影响(当前缺点是需要手动维护内存)。当需要为chunk申请内存时,会调用unix.Mmap来一次性申请chunksPerAlloc(即1024)个chunk,将其附加到freeChunks中,并从freeChunks中返回最后一个元素作为初始化后的chunk。当然unix.Mmap需要在unix系统下才能生效。
freeChunks是个全局chunk数组,便于为不同的chunk提供存储。
func getChunk() []byte {
freeChunksLock.Lock()
if len(freeChunks) == 0 {
// Allocate offheap memory, so GOGC won't take into account cache size.
// This should reduce free memory waste.
data, err := unix.Mmap(-1, 0, chunkSize*chunksPerAlloc, unix.PROT_READ|unix.PROT_WRITE, unix.MAP_ANON|unix.MAP_PRIVATE)
if err != nil {
panic(fmt.Errorf("cannot allocate %d bytes via mmap: %s", chunkSize*chunksPerAlloc, err))
}
for len(data) > 0 {
p := (*[chunkSize]byte)(unsafe.Pointer(&data[0]))
freeChunks = append(freeChunks, p)
data = data[chunkSize:]
}
}
n := len(freeChunks) - 1
p := freeChunks[n]
freeChunks[n] = nil
freeChunks = freeChunks[:n]
freeChunksLock.Unlock()
return p[:]
}
下面是trunk的回收方式,比较简单,即将需要回收的trunk附加到freeChunks即可。
func putChunk(chunk []byte) {
if chunk == nil {
return
}
chunk = chunk[:chunkSize]
p := (*[chunkSize]byte)(unsafe.Pointer(&chunk[0]))
freeChunksLock.Lock()
freeChunks = append(freeChunks, p)
freeChunksLock.Unlock()
}
添加kv数据
fastcache使用Set来添加数据,但数据需要是[]byte类型。它首先会对k进行哈希,统一k的长度。并通过哈希的结果找出存放该数据的bucket索引。
func (c *Cache) Set(k, v []byte) {
h := xxhash.Sum64(k)
idx := h % bucketsCount
c.buckets[idx].Set(k, v, h)
}
通过索引找到对应的bucket之后,下一步就是将数据存储到bucket中的chunk中。
该函数是fastcache的核心函数,
-
有效性校验,确保k、v的长度不超过16bit,即2个字节,在第2步中会保存k、v的长度信息,因此此处是强制限制。
-
chunk中保存的单个数据的格式如下,使用这种方式主要是为了方便快速检索k、v。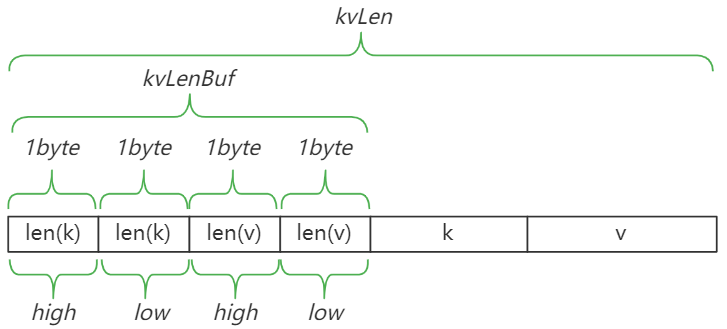
-
获取该bucket中的
chunks,注意一开始使用的时候chunks中的chunk是没有初始化的 -
b.idx表示当前chunks中的总数据偏移(但并不等于有效数据,如果某个chunk无法容纳下一个数据,则会产生一定的碎片)。chunkIdx为当前chunk的索引,idxNew为添加新数据之后的总数据偏移,chunkIdxNew为添加新数据之后的chunk索引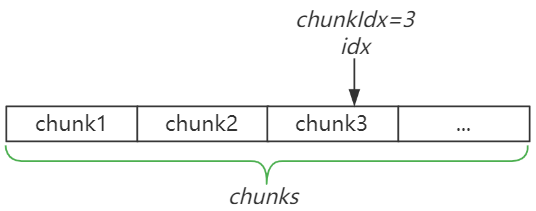
-
如果
chunkIdxNew > chunkIdx说明当前chunk的剩余空间无法保存新数据,此时需要一个新的chunk来保存新数据(此时索引为chunkIdx的chunk中会产生内存碎片)。 -
如果该
bucket中的所有chunk都已经被占满,此时没有空余的chunk来保存新数据,此时会采用ringbuffer的方式,将新数据放到第一个chunk中6.1 更新数据偏移量,此时在第一个
chunk中,因此偏移量为0。bucket有一个b.gen成员,保存了当前bucket中chunks的循环使用次数,即第gen代数据。由于chunks是ringbuf,存储空间会被循环利用,因此在查询数据时需要对比数据存储时的gen(存储在b.m中)和当前gen,如果不相同,则说明老的数据已经被后来的数据覆盖了。6.2
b.gen会保存到b.m的高24位,如果此时b.gen&((1<<genSizeBits)-1) == 0,则说明b.gen发生了溢出,此时需要将b.gen置0,重新计数。6.3 当重新使用
chunks时,需要清理b.m中无效的数据 -
如果
chunks中有空余的chunk,则更新chunk索引和总数据偏移量。 -
清空
chunk中的数据 -
获取存储数据的
chunk,如果该chunk没有初始化,则调用getChunk初始化chunk内存。 -
在
chunk中添加该数据,包括数据头(kvLenBuf)和k、v -
b.m中保存了该元素(索引为k的哈希值)的相关信息,高24位保存了该数据所处的gen,低40位保存了该数据的起始位置(即保存该数据时的总数据偏移量,受限于chunkSize的大小,最多只会占用16bit)。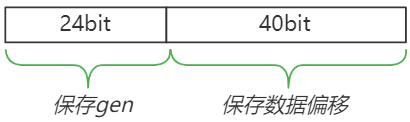
-
更新bucket中的总数据偏移量
-
cleanLocked会清理b.m中的无效数据。那么如何判断哪些数据是无效的呢?有效数据有如下两种情况:- 如果数据的偏移量(
idx)大于当前bucket的偏移量(bIdx),则说明该数据是上一代数据,则数据的gen和bucket的gen(bGen)有如下两种关系:gen+1 == bGen- gen == maxGen && bGen == 1
- 如果数据的偏移量(
idx)小于当前bucket的偏移量(bIdx),,则说明该数据是本代数据,则要满足gen == bGen
不满足上述两种场景的数据都是无效数据,需要清理。
func (b *bucket) cleanLocked() { bGen := b.gen & ((1 << genSizeBits) - 1) bIdx := b.idx bm := b.m for k, v := range bm { gen := v >> bucketSizeBits idx := v & ((1 << bucketSizeBits) - 1) if (gen+1 == bGen || gen == maxGen && bGen == 1) && idx >= bIdx || gen == bGen && idx < bIdx { continue } delete(bm, k) } } - 如果数据的偏移量(
func (b *bucket) Set(k, v []byte, h uint64) {
atomic.AddUint64(&b.setCalls, 1)
if len(k) >= (1<<16) || len(v) >= (1<<16) { //<1>
return
}
var kvLenBuf [4]byte // <2>
kvLenBuf[0] = byte(uint16(len(k)) >> 8)
kvLenBuf[1] = byte(len(k))
kvLenBuf[2] = byte(uint16(len(v)) >> 8)
kvLenBuf[3] = byte(len(v))
kvLen := uint64(len(kvLenBuf) + len(k) + len(v))
if kvLen >= chunkSize {
return
}
chunks := b.chunks // <3>
needClean := false
b.mu.Lock()
idx := b.idx // <4>
idxNew := idx + kvLen
chunkIdx := idx / chunkSize
chunkIdxNew := idxNew / chunkSize
if chunkIdxNew > chunkIdx { // <5>
if chunkIdxNew >= uint64(len(chunks)) { // <6>
idx = 0 // <6.1>
idxNew = kvLen
chunkIdx = 0
b.gen++
if b.gen&((1<<genSizeBits)-1) == 0 { // <6.2>
b.gen++
}
needClean = true // <6.3>
} else {
idx = chunkIdxNew * chunkSize // <7>
idxNew = idx + kvLen
chunkIdx = chunkIdxNew
}
chunks[chunkIdx] = chunks[chunkIdx][:0] // <8>
}
chunk := chunks[chunkIdx] // <9>
if chunk == nil {
chunk = getChunk()
chunk = chunk[:0]
}
chunk = append(chunk, kvLenBuf[:]...) // <10>
chunk = append(chunk, k...)
chunk = append(chunk, v...)
chunks[chunkIdx] = chunk
b.m[h] = idx | (b.gen << bucketSizeBits) // <11>
b.idx = idxNew //12
if needClean { // <13>
b.cleanLocked()
}
b.mu.Unlock()
}
获取kv数据
有了Set的基础,Get就相对简单很多。
- 首先从
b.m中获取该k对应的元数据 - 校验该数据是否合法,逻辑跟
cleanLocked一样 - 如果合法,则通过偏移量找到对应的
chunk - 获取数据在其所在的
chunk中的偏移量 - 找到
kvLenBuf中保存的k、v长度 - 校验数据中的k是不是跟所需要的k一样,这么做的目的是防止哈希冲突的情况下获取到异常数值。如果合法则返回对应的v即可
func (b *bucket) Get(dst, k []byte, h uint64, returnDst bool) ([]byte, bool) {
atomic.AddUint64(&b.getCalls, 1)
found := false
chunks := b.chunks
b.mu.RLock()
v := b.m[h] // <1>
bGen := b.gen & ((1 << genSizeBits) - 1)
if v > 0 {
gen := v >> bucketSizeBits
idx := v & ((1 << bucketSizeBits) - 1)
if gen == bGen && idx < b.idx || gen+1 == bGen && idx >= b.idx || gen == maxGen && bGen == 1 && idx >= b.idx { // <2>
chunkIdx := idx / chunkSize // <3>
if chunkIdx >= uint64(len(chunks)) {
// Corrupted data during the load from file. Just skip it.
atomic.AddUint64(&b.corruptions, 1)
goto end
}
chunk := chunks[chunkIdx]
idx %= chunkSize // <4>
if idx+4 >= chunkSize {
// Corrupted data during the load from file. Just skip it.
atomic.AddUint64(&b.corruptions, 1)
goto end
}
kvLenBuf := chunk[idx : idx+4] // <4>
keyLen := (uint64(kvLenBuf[0]) << 8) | uint64(kvLenBuf[1])
valLen := (uint64(kvLenBuf[2]) << 8) | uint64(kvLenBuf[3])
idx += 4
if idx+keyLen+valLen >= chunkSize {
// Corrupted data during the load from file. Just skip it.
atomic.AddUint64(&b.corruptions, 1)
goto end
}
if string(k) == string(chunk[idx:idx+keyLen]) { // <5>
idx += keyLen
if returnDst {
dst = append(dst, chunk[idx:idx+valLen]...)
}
found = true
} else {
atomic.AddUint64(&b.collisions, 1)
}
}
}
end:
b.mu.RUnlock()
if !found {
atomic.AddUint64(&b.misses, 1)
}
return dst, found
}
总结
- fastcache的chunk内存分配方式比较好,它没有预先分配大量内存,而是动态申请的方式。其次内存申请使用了手动申请的方式(
mmap),以此避免GC的影响。 - fastcache的数据存储时包含了一个元数据头,元数据里面保存了该数据的数据偏移量以及k、v长度等数据,通过这种方式可以快速定位数据所在的位置。像大部分存储的WAL存储方式也是采用的这种TLV或LV方式。
- fastcache的缓存采用的是ringbuffer的方式,并没有超时机制。数据的存储和查找都是通过哈希的方式进行的,因此检索速度很快。
- fastcache的代码比较少,可以直接移植