数据库
数据库 DB: 内存,CPU,磁盘,带宽 这几个方面影响性能。那优化点在哪?
不要上来就说 不要使用 select* 要选择性的添加索引之类的
- 可以先说一下监控SQL 看它的执行时间 (SQL Server Profiler)
- 查看数据库连接怎么查
- 数据库设计之初,索引怎么选择
- SQL语句的优化
- 设置MySQL的参数
- 分布式集群如何设计
主从复制
一个数据库不是很好么,为什么会涉及到主从复制
- 如果一台数据库达到性能的瓶颈,那就要考虑,把请求做一个负载(代理层)所有请求转发到代理层,由代理层来分发,到底用哪个DB去查,那么这么多DB是否要保持数据一致呢?(根据业务)
如果要做读写分离:那就有一台专门是写 其余负责读。数据要保持一致,要想数据一致,那就要主从复制。
如何实现主从复制
- master将DML1操作语句记录在binlog日志中
- slave开启两个线程 一个IO thread 一个 SQL thread,其中IO 线程负责读取master的binlog内容,写到中继日志relay log里;SQL线程读取relay log的内容,并更新到slave的数据库中。这样就保证了主从数据一致了
- MySQL复制至少需要两个MySQL的服务,MySQL服务也可以分布在不同的服务器上。也可以在一台
通俗点说:
第一台db叫master 第二台叫slave。主从复制时,操作对象都是master,会有DML1操作(客户端发送sql语句时),在DML操作时一定会保留日志(就是binlog),有个线程IO Thread
,传给slave(要不要持久化存储?要 通过中继日志 relay log), slave和master保持一致,需要将relay log进行重放执行操作(sql thread),根据日志进行恢复
网上有一个很清晰的流程图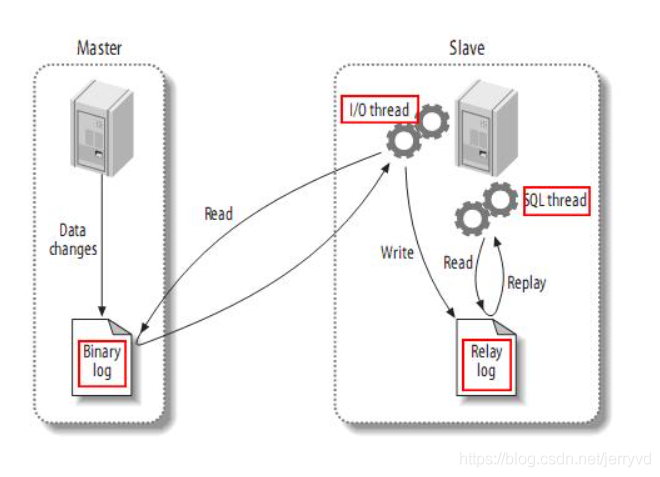
主从延迟怎么产生的?
1.备库的性能比主库差
2.备库充当读库,如果查询压力大,消耗了大量的CPU资源,也会影响同步的速度
3.大事务(执行时间很长的事务)执行,主库事务执行了很长时间,那么binlog的写入需要等待事务完成。那么延迟就从开始就产生了
4.从库SQL thread写数据的时候是随机操作
5.从库同步数据时,可能跟某个查询的线程发生锁抢占,此时也会延时
6.主库的TPS2并发非常高时,产生的DDL3数量超过了一个线程所承受的范围的时候,产生延迟
7.binlog日志传输,网路带宽不好,也可能有延迟
DML写入binlog里是顺序写的,append都是顺序的。
IO thread进行数据读取也是顺序的,然后将sql写入Relay log 也是顺序的
SQL thread 从Relay log 读也是顺序的,但是当SQL thread写入Slave时是随机的。
update语句如果两条语句不在一个磁盘块,意味着要寻址,不是sql语句的顺序
最初IO thread 只有一个线程 和 一个SQL thread
会有MTS问题(multi-thread slave 多个线程并行执行),并行执行,又会有锁冲突,如果是同一条数据,被多个线程抢到,执行的先后顺序是啥,那就需要定规则
mysql版本 5.6,5.7,8
5.6就有并行复制了。但是有限制,5.6只支持以库为单位,并行复制。
粒度 库 表 行
5.7之后才有以行为单位
show variables like ‘%parallel%’
slave_parallel_type DATABASE 5.6的特性
随机读取和顺序读取
随机读取有一个寻址的过程,寻址是比较浪费时间的
主从延迟怎么处理
- relay log 到写数据中间增加一个分发环节,coordinator负责读取日志信息及分发食事务,真正的日志执行交给worker线程
分发规则:
1.更新同一行的多个事务,必须分发到同一个worker中执行
2.同一个事务不能拆开,必须放到同一个worker下执行
库-> workers上加标识->db
表->worker->库名表名
行->worker->库名表名唯一键的值
GTID (global transaction identifiers) 全局事务id 即使不指定也会有匿名的gtid
服务器的唯一标识 + 递增的事务id
5.7采用什么样的并行复制策略?
mysql在写binlog时同时在写redo log
binlog日志->如何写入binlog日志->二阶段提交()
数据更新过程
获取数据
数据是否在内存中 否 磁盘数据读入内存
是
返回数据
更改数据
写入新的数据
新数据更新到内存
写入redo,出入prepare阶段
写binlog 写入redo和写入binlog两个整体提交叫二阶段提交 为了保证crash safe 服务异常,保证数据能够完整恢复
提交事务处于commit状态
为啥需要一起提交
1.先写redo log后写binlog 假设在redo log写完,binlog还没写完,MySQL进程异常重启,binlog里面没有这个记录,在之后备份日志时,存就会少了一次更新,恢复出来的值和原库值不同
2.先写binlog后写redo log 如果再binlog写完之后crash,由于redo log没有写完,崩溃恢复以后这个事务无效,值没变,但是binlog里面有将该值修改的语句。在之后恢复的时候多了一个事务出来,恢复出来的值与原库不符
为什么一起两阶段提交之后 没有这个问题了?
在进行数据的崩溃恢复的时候,是两个日志结合起来看的,
比如在写完redo,处于prepare阶段之后崩溃的,在数据回滚时候,判断redo 处于准备中,但是binlog没有这个对应的记录,那这个事务就是失败。做一个回滚操作,
如果在binlog写完崩溃,binlog有对应记录,但是redo log出入prepare。把处于prepare的数据提交,保持数据一致性。
组提交是啥?
是mysql处理日志的一种优化方式,主要是为了解决写日志拼房刷磁盘的问题。组提交思想是,将多个事务redo log的刷盘动作合并,减少磁盘的顺序写。
所有的日志数据在写的时候,要经历几个阶段,
当前进程的内存空间 ->
当前系统的内存空间 write ->
fsync 刷写磁盘 -> 尽可能多的一次性写更多的数据
write 指的就是把日志写入文件系统的page cache,并没有把数据持久化到磁盘,所以速度快
fsync 才是将数据持久化到磁盘的操作。一般情况下 fsync才占用磁盘的IOPS 而write和fsync的事迹就是由参数sync_binlog来控制
1.当sync_binlog = 0的时候,表示每次提交事务都用write,不fsync
2.当sync_binlog = 1的时候,表示每次提交事务都执行fsync
3.当sync_binlog = N的时候,表示每次提交事务都write,但积累N个事务后才fsync
在公司大部分应用场景中,建议将此参数的值设置为1,因为这样
能够保证数据的安全性,但是如果出现主从复制的延迟问题,可以考虑将此值设置为100~1000中的某个数值,非常不建议将此值设置为0.
因为设置为0的时候,没有办法控制丢失日志的数据量,但是如果是对安全性要求比较高的业务系统,这个参数的意义就不那么大了。
2直接禁用salve的binlog,当从库的数据在做同步的时候,有可能从库的binlog也会进行记录,此时的话肯定也会消耗io的资源,但如果搭建的集群是级联模式的话,此时binlog也会发送到另外一台从库方便进行数据同步,这个配置项也不会起太大的作用
3设置innodb_flush_log_at_trx_commit属性(用来表示每一次的事务提交是否需要把日志都写入磁盘,这是很浪费时间的,一共三个属性值,0每次写到服务器缓存,一秒钟刷写一次,1每次事务提交都刷写一次磁盘2每次写到os缓存,一秒钟刷写一次),一般情况下,推荐设置为2,这样就算mysql服务宕机,写在os缓存中的数据也会进行持久化
查询时,优先查的是磁盘还是内存?
组提交是一起提交。
最早是只有redo log 有组提交
mysql双1操作是什么?
innodb_flush_log_at_trx_commit和sync_binlog两个参数设置,
这两个是控制MySQL磁盘写入策略一级数据安全性的关键参数。
执行过程
1.执行器先从引擎中找到数据,如果再内存这种直接返回,如果不在内存中,查询后返回
2.执行器拿到数据之后会先修改数据,然后调用引擎接口重新写入数据
3.引擎将数据更新到内存,同时写数据到redo中,此时出入prepare阶段,并通知执行器执行完成,随时可操作
4.执行器生成这个操作的binlog
5.执行器调用引擎的事务提交接口,引擎把刚刚写完的redo改成commit状态,更新完成
数据库持久化的两种实现方式
- 快照
- 日志
MySQL持久化方式
- MySQL快照 : MySQL的dump工具,可以将数据导出为.sql文件,通过这个sql文件,可以作数据恢复。
- Mysql的binlog
Redis持久化方式
- RDB持久化 :将Redis在内存中的数据库记录定时dump到磁盘上的RDB持久化
- AOF(append only file)持久化 :将Redis的操作日志以追加的方式写入文件
线程和进程区别
- 进程-资源分配的最小单位
- 线程-程序执行的最小单位
mysql存在几种日志
- binlog 二进制日志文件,需要手动开启,归属于mysql服务 用于记录用户对数据库操作的SQL语句 除了数据查询语句
- undo log,归属于innodb存储引擎的
- redo log,归属于innodb存储引擎的
还有慢查询日志,错误日志,mysql执行日志,不管是mysam或者innodb共用的都是binlog
缓存命中率
查询缓存的工作原理,基本上可以概括为: 缓存SELECT操作或预处理查询(注释:5.1.17开始支持)的结果集和SQL语句; 新的SELECT语句或预处理查询语句,先去查询缓存,判断是否存在可用的记录集,判断标准:与缓存的SQL语句,是否完全一样,区分大小写;
MTS 解决的问题是什么?
减少整体过程中的并行写的过程,如果能遵循并行写的过程
mysq 5.7的并行复制策略
mysql 5.7版本的时候,根据marlaDB的并行复制策略,做了相应的调整,可以通过参数slave-paralle-type来控制并行复制的策略
1.当配置的值为DATABASE的时候,表示使用5.6版本的按库并行策略
2当配置值的值为IOGICAL_CLOCK的时候,表是跟mariaDB相同的策略
同时处于执行状态的所有事务是否可以并行? 不行。因为多个执行中的事务是有可能出现锁冲突的,锁冲突之后就会产生锁等待的问题。
所有处于commit状态的事务是可以并行的,因为如果能commit的话,就说明已经没有锁的问题了
1redo log prepare write ->3
2binlog:write ->4
3.redo log prepare fsync
4.binlog : fsync
5redo log commit write
mysql 5.7的并行复制策略的思想是
1.同时处于prepare状态的事务,在备库执行是可以并行的
2.出入prepare状态的事务,与处于commit状态的事务之间,在备库上执行也是可以并行的,基于这样的处理机制,可以将大部分的日志处于prepate状态,因此可以设置 1.binlog_group_commit_sync_delay参数表示延迟多少微秒后才调用fsync
2.binlog_group_commit_sync_no_delay_count参数,表示积累多少次以后才调用fsync
怎么来看是否有慢查询
show slave status;
Seconds_Behind_Master:NULL
一般情况等于0 值变大 就说明延迟大
5.7的版本
更改配置就能搞定
查看并行的slave的线程的个数,默认是0,表示单线程
1.show global variables like ‘slave_parallel_workers’;
根据实际情况保证开启多少线程
2.set global slave_parallel_workers=4;
设置并发复制的方式,默认是一个线程处理一个库,值为database;
show global variables like ‘%slave_parallel_type%’
停止slave;
stop slave;
设置属性值
set global slave_parallel_type=‘logical_check’;
开启slave
start slave
查看线程数
show full processlist;
worker 8 到 16 和cpu核数对应
要多看官网查看