主从模式
- 主从模式数据库分为两类:主数据库(master)、从数据库(slave)
* 主数据库可以进行读写操作,当读写操作导致数据变化时会自动将数据同步给从数据库
* 从数据库一般都是只读的,并且接收主数据库同步过来的数据
* 一个master可以拥有多个slave,但是一个slave只能对应一个master
* slave挂了不影响其他slave的读和master的读和写,重新启动后会将数据从master同步过来
* master挂了以后,不影响slave的读,但redis不再提供写服务,master重启后redis将重新对外提供写服务
* master挂了以后,不会在slave节点中重新选一个master- master在后台保存RDB快照(redis database)和保持这段事件快照的AOF(append only file),发送给slave确保主从数据一致性。master支持读写,slave只支持度操作。
# msater redis.confbind0.0.0.0#监听ip,多个ip用空格分隔
port6379
dbfilename dump.rdb
masterauth123456#slave连接master密码,master可省略
requirepass123456#设置master连接密码,slave可省略dir"/tmp"#数据库备份文件存放目录
appendonlyyes# 开去AOF,每次写操作都追加到appendonly.aof
protected-mode no# 保护模式
daemonize no# 守护进程
loglevel debug
logfile"/usr/local/redis/redis.log"# slave redis.conf与master redis.conf配置一样,只需添加replicaof master_ip master_port
replicaof192.168.30.1286379Sentinel
对于一组主从节点,sentinel只是在其外部额外添加的一组用于监控作用的redis实例。
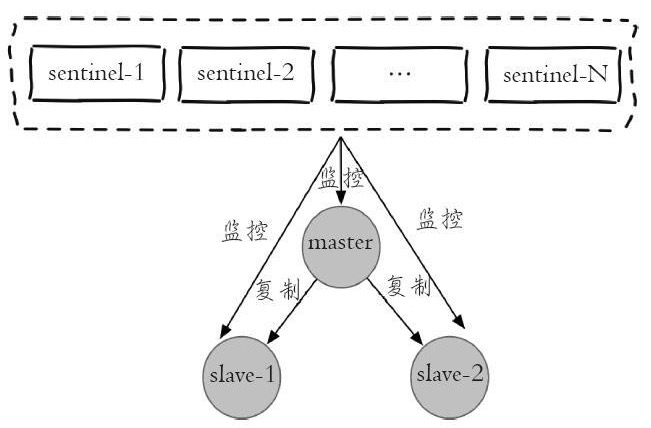
- Sentinel是一个分布式系统,当多个Sentinel同意一个master不再可用的时候,就执行故障检测。
* sentinel模式是建立在主从模式的基础上,如果只有一个Redis节点,sentinel就没有任何意义
* 当master挂了以后,sentinel会在slave中选择一个做为master,并修改它们的配置文件,其他slave的配置文件也会被修改,比如slaveof属性会指向新的master
* 当master重新启动后,它将不再是master而是做为slave接收新的master的同步数据
* sentinel因为也是一个进程有挂掉的可能,所以sentinel也会启动多个形成一个sentinel集群
* 多sentinel配置的时候,sentinel之间也会自动监控
* 当主从模式配置密码时,sentinel也会同步将配置信息修改到配置文件中,不需要担心
* 一个sentinel或sentinel集群可以管理多个主从Redis,多个sentinel也可以监控同一个redis
* sentinel最好不要和Redis部署在同一台机器,不然Redis的服务器挂了以后,sentinel也挂了- 工作机制:
* 每个sentinel以每秒钟一次的频率向它所知的master,slave以及其他sentinel实例发送一个 PING 命令
* 如果一个实例距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被sentinel标记为主观下线。
* 如果一个master被标记为主观下线,则正在监视这个master的所有sentinel要以每秒一次的频率确认master的确进入了主观下线状态
* 当有足够数量的sentinel(大于等于配置文件指定的值)在指定的时间范围内确认master的确进入了主观下线状态, 则master会被标记为客观下线
* 在一般情况下, 每个sentinel会以每10 秒一次的频率向它已知的所有master,slave发送 INFO 命令
* 当master被sentinel标记为客观下线时,sentinel向下线的master的所有slave发送 INFO 命令的频率会从10 秒一次改为1 秒一次
* 若没有足够数量的sentinel同意master已经下线,master的客观下线状态就会被移除;
若master重新向sentinel的 PING 命令返回有效回复,master的主观下线状态就会被移除- 配置文件:
# redis sentinel.conf
daemonizeyes
logfile"/usr/local/redis/sentinel.log"dir"/usr/local/redis/sentinel"#sentinel工作目录
sentinel monitor mymaster192.168.30.12863792#判断master失效至少需要2个sentinel同意,建议设置为n/2+1,n为sentinel个数
sentinel auth-pass mymaster123456
sentinel down-after-milliseconds mymaster30000#判断master主观下线时间,默认30s- Sentinel模式下的几个事件:
· +reset-master :主服务器已被重置。
· +slave :一个新的从服务器已经被 Sentinel 识别并关联。
· +failover-state-reconf-slaves :故障转移状态切换到了 reconf-slaves 状态。
· +failover-detected :另一个 Sentinel 开始了一次故障转移操作,或者一个从服务器转换成了主服务器。
· +slave-reconf-sent :领头(leader)的 Sentinel 向实例发送了[SLAVEOF](/commands/slaveof.html) 命令,为实例设置新的主服务器。
· +slave-reconf-inprog :实例正在将自己设置为指定主服务器的从服务器,但相应的同步过程仍未完成。
· +slave-reconf-done :从服务器已经成功完成对新主服务器的同步。
· -dup-sentinel :对给定主服务器进行监视的一个或多个 Sentinel 已经因为重复出现而被移除 —— 当 Sentinel 实例重启的时候,就会出现这种情况。
· +sentinel :一个监视给定主服务器的新 Sentinel 已经被识别并添加。
· +sdown :给定的实例现在处于主观下线状态。
· -sdown :给定的实例已经不再处于主观下线状态。
· +odown :给定的实例现在处于客观下线状态。
· -odown :给定的实例已经不再处于客观下线状态。
· +new-epoch :当前的纪元(epoch)已经被更新。
· +try-failover :一个新的故障迁移操作正在执行中,等待被大多数 Sentinel 选中(waiting to be elected by the majority)。
· +elected-leader :赢得指定纪元的选举,可以进行故障迁移操作了。
· +failover-state-select-slave :故障转移操作现在处于 select-slave 状态 —— Sentinel 正在寻找可以升级为主服务器的从服务器。
· no-good-slave :Sentinel 操作未能找到适合进行升级的从服务器。Sentinel 会在一段时间之后再次尝试寻找合适的从服务器来进行升级,又或者直接放弃执行故障转移操作。
· selected-slave :Sentinel 顺利找到适合进行升级的从服务器。
· failover-state-send-slaveof-noone :Sentinel 正在将指定的从服务器升级为主服务器,等待升级功能完成。
· failover-end-for-timeout :故障转移因为超时而中止,不过最终所有从服务器都会开始复制新的主服务器(slaves will eventually be configured to replicate with the new master anyway)。
· failover-end :故障转移操作顺利完成。所有从服务器都开始复制新的主服务器了。
· +switch-master :配置变更,主服务器的 IP 和地址已经改变。 这是绝大多数外部用户都关心的信息。
· +tilt :进入 tilt 模式。
· -tilt :退出 tilt 模式。Cluster
- cluster用以解决当数据两过大一台服务器存放不下的情况。
* 多个redis节点网络互联,数据共享
* 所有的节点都是一主一从(也可以是一主多从),其中从不提供服务,仅作为备用
* 不支持同时处理多个key(如MSET/MGET),因为redis需要把key均匀分布在各个节点上,
并发量很高的情况下同时创建key-value会降低性能并导致不可预测的行为
* 支持在线增加、删除节点
* 客户端可以连接任何一个主节点进行读写- 配置信息:
# redis cluster.confbind192.168.30.128
port6379
daemonizeyes
pidfile"/var/run/redis.pid"
logfile"/usr/local/redis/cluster/redis.log"dir"/data/redis/cluster/redis"#replicaof 192.168.30.129 6379
masterauth123456
requirepass123456
appendonlyyes
cluster-enabledyes
cluster-config-file nodes.conf
cluster-node-timeout15000- port :节点端口;
- requirepass :添加访问认证;
- masterauth :如果主节点开启了访问认证,从节点访问主节点需要认证;
- protected-mode :保护模式,默认值 yes,即开启。开启保护模式以后,需配置 bind ip 或者
- 设置访问密码;关闭保护模式,外部网络可以直接访问;
- daemonize :是否以守护线程的方式启动(后台启动),默认 no;
- appendonly :是否开启 AOF 持久化模式,默认 no;
- cluster-enabled :是否开启集群模式,默认 no;
- cluster-config-file :集群节点信息文件;
- cluster-node-timeout :集群节点连接超时时间;
- cluster-announce-ip :集群节点 IP,填写宿主机的 IP;
- cluster-announce-port :集群节点映射端口;
- cluster-announce-bus-port :集群节点总线端口。
// 集群中增加节点(新增的节点都是以master身份加入集群的)
CLUSTER MEET192.168.1.16379
// 切换节点身份
redis-cli -c -h192.168.1.1 -p6379 -a123456 replicate node_id
// 登入节点修改身份
CLUSTER REPLICATE node_id每个 Redis 集群节点都需要打开两个 TCP 连接。一个用于为客户端提供服务的正常 Redis TCP 端口,例如6379。还有一个基于6379 端口加10000 的端口,比如16379。
第二个端口用于集群总线,这是一个使用二进制协议的节点到节点通信通道。节点使用集群总线进行故障检测、配置更新、故障转移授权等等。客户端永远不要尝试与集群总线端口通信,与正常的 Redis 命令端口通信即可,但是请确保防火墙中的这两个端口都已经打开,否则 Redis集群节点将无法通信。命令
# 查看配置
info replication> sentinel master mymaster> sentinel slaves mymaster> sentinel sentinels mymaster等等。客户端永远不要尝试与集群总线端口通信,与正常的 Redis 命令端口通信即可,但是请确保防火墙中的这两个端口都已经打开,否则 Redis集群节点将无法通信。
### 命令
```shell
# 查看配置
info replication
> sentinel master mymaster
> sentinel slaves mymaster
> sentinel sentinels mymasterceadasdsad