一.引言
Parquet 是一种列式存储格式,常用于表结构数据存储,也是 sparkSql 的默认存储格式。spark 读取 parquet 文件时,偶发读取时间过长,正常 parquet 时间在 1-5 s,异常期间最长可达 10 min +,于是开始踩坑之旅。下面是读取日志,正常情况只需 1s 以内,异常时却需要很久。

二.Parquet 读取问题定位与解决
1.代码变化 && 数据变化
1s 左右的加载时间和出现异常导致 10min + 的加载时间前后代码没有发生过变化,唯一的改变就是读取的 parquet 数量增加了一倍,总大小未改变。因此问题应该出在和 parquet 相关的代码上,这里执行的是官方的 api :
spark.read.parquet(path)所以解决问题就需要看下读取 parquet 的具体逻辑了。
2.Schema Infer And Merge
spark 读取 read parquet 时有一个参数 .schema 用于指定 parquet 的列名与列属性,如果直接调用 .read.parquet() 时,sparkSession 需要自己 infer parquet 的 schema , schema 可以理解为 parquet 每列数据的属性,包含 name,type 等等:
override def inferSchema(
sparkSession: SparkSession,
parameters: Map[String, String],
files: Seq[FileStatus]): Option[StructType] = {
val parquetOptions = new ParquetOptions(parameters, sparkSession.sessionState.conf)
// Should we merge schemas from all Parquet part-files?
val shouldMergeSchemas = parquetOptions.mergeSchema
...
ParquetFileFormat.mergeSchemasInParallel(filesToTouch, sparkSession)
}这里截距了一部分代码,其中 parquetOptions.mergeSchema 参数代表是否合并 schema,默认为 true,在 spark 中配置该参数:
conf spark.sql.parquet.mergeSchema=true \这段代码还有一段解释含义大致如下 :
如果用户指定mergeSchema = false 参数,程序会首先尝试摘要文件,如果没有摘要文件,则返回某个随机的部分文件,所以当该参数为 false 时,infer 会随机选取 parquet 文件进行推断,如果 所有 parquet 文件格式一致则不受影响,如果不一致则会 infer 出错。
如果用户指定mergeSchema = true 参数, 则程序认为所有的部分文件都是相同的,此时如果出现 parquet 不匹配,例如名称匹配,类型不匹配时 infer 会报错。但是当文件过多时,如果串行执行效率会很低,所以这里采取并行处理的方式进行 schema 推断,也就是上面 infer 函数的最后一行 mergeSchemaInParallel :
def mergeSchemasInParallel(
filesToTouch: Seq[FileStatus],
sparkSession: SparkSession): Option[StructType] = {
val assumeBinaryIsString = sparkSession.sessionState.conf.isParquetBinaryAsString
val assumeInt96IsTimestamp = sparkSession.sessionState.conf.isParquetINT96AsTimestamp
val serializedConf = new SerializableConfiguration(sparkSession.sessionState.newHadoopConf())
val numParallelism = Math.min(Math.max(partialFileStatusInfo.size, 1),
sparkSession.sparkContext.defaultParallelism)
val ignoreCorruptFiles = sparkSession.sessionState.conf.ignoreCorruptFiles
// Issues a Spark job to read Parquet schema in parallel.
val partiallyMergedSchemas =
sparkSession
.sparkContext
.parallelize(partialFileStatusInfo, numParallelism)
.mapPartitions { iterator =>
// Resembles fake `FileStatus`es with serialized path and length information.
...
}.collect()
if (partiallyMergedSchemas.isEmpty) {
None
} else {
var finalSchema = partiallyMergedSchemas.head
partiallyMergedSchemas.tail.foreach { schema =>
try {
finalSchema = finalSchema.merge(schema)
} catch { case cause: SparkException =>
throw new SparkException(
s"Failed merging schema:\n${schema.treeString}", cause)
}
}
Some(finalSchema)
}
}这里给出部分代码,如果想要查看完整的 infer,mergeSchemaInParallel 代码可以查看 :
org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat上述代码通过 parallelize + mapPartitions 实现 schema 的并行推断,这里涉及到 fileStatus 信息与 Executor 的信息交互,最终合并得到 partiallyMergedSchemas[iterator],所有 parquet 得到的 scheme 构成了一个迭代器,然后通过可变变量 var finalSchema 进行遍历与合并,结果返回 Some(finalSchema),代表推断与merge的结果不可控。
3.原因分析
上面只是简单看了源码的实现逻辑,结合前面的代码、数据变化,在 mergeShema 参数为 true 时 读取 parquet 中涉及和 parquet 数量有关的操作有下述:
(1)parallel + mapPartitions:在 numParallelism 数量不变时,parquet 数量增加,则 mapPartitions 处理的 partition 数量增加,耗时增加
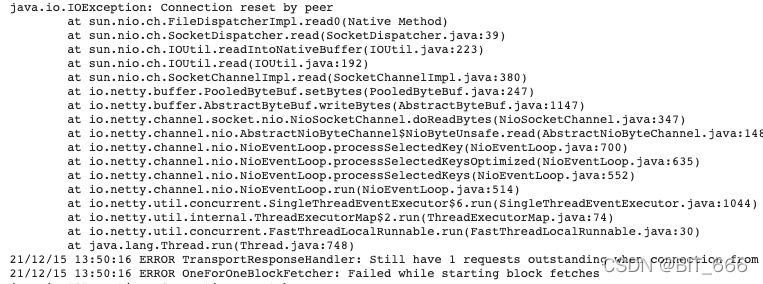
(2)fileStatus 与 Executor 的通信:parquet 数量增多时,FileStatus 增多,executor 通信量增大,耗时增加,查看运行异常日志发现任务所在机器已出现 IO 负载较大的情况:
(3)merge:处理数据量增多,iterator 数量增加,merge 操作增加,耗时增加
4.问题解决
基于上面耗时的分析,问题解决也很简单,减少 parquet 数量,避免 mergeSchema:
A. spark.sql.parquet.mergeSchema = false
最偷懒的办法,如果可以保证每个 parquet 数据的结构一致性,则可以取消该参数,只选用少量 parquet 文件进行 infer 推断,这样处理文件的数量变小,推断 schema 的速度也会相应增加。
B. spark.sql.parquet.mergeSchema = true & 不指定 schema
该参数默认为 true,在不手动指定的情况下,可以人为缩减 parquet 数量,这样并行执行的效率会得到提升
C.指定 schema
spark.read.parquet 方法支持直接传入 schema :
spark.read.schema(TABLE_SCHEME).parquet(path)该方法会指定 Schema 从而避免后续复杂的 infer 阶段,从而跳过 parquet 阶段,直接进入下一个 action 算子。
def schema(schema: StructType): DataFrameReader = {
this.userSpecifiedSchema = Option(schema)
this
}三.Read parquet 指定 Schema
1.配置 schema
parquet 采用列式存储,相关的存储类型上一篇文章Spark Sql:RDD - DF 互转 中已经提到过,
第一个参数代表列名,第二个参数代表列属性 :
final val TABLE_SCHEME = StructType(Array(
StructField("A", StringType),
StructField("B", StringType),
StructField("C", StringType),
StructField("D", StringType),
StructField("E", StringType),
StructField("F", StringType),
StructField("G", StringType),
StructField("H", StringType)
))
val conf = new SparkConf().setMaster("local[*]")
val spark = SparkSession
.builder
.config(conf)
.getOrCreate()
spark.read.schema(TABLE_SCHEME).parquet(path).rdd.take(10).foreach(row => {
println(row)
})2.读取数据为空
看似任务已经搞定了,但是还有坑,设置 schema 时读取数据为 null,不设置 schema 时读取正常
设置 schema:

不设置 schema :

于是查找了设定 schema 的规则,当我们指定了 schema 时,相当于指定了每个对应位置字段的名称和类型,读取内容时参照如下规则:
指定的 schema 中的字段在 parquet 中默认的 schema 中不存在则返回 null :
null,null,null,null,null,null,null,null,null,null,null,null指定的 schema 中字段在 parquet 中默认的 schema 中存在但类型不匹配,返回 false :
null,null,null,null,null,null,null,null,null,null,null,false3.原因分析
添加 schema 后显示为 null,根据上述规则可以判定是设定的 schema 的列名在原始 parquet 的 schema 中不存在,相当于 map.getOrElse("col", null) 触发了 else 逻辑,通过原始 df 的 schema 方法可以获得原始 parquet 的 schema :
spark.read.parquet(path).schema.map(x => {
println(x.name, x.dataType)
})(_c0,StringType)
(_c1,StringType)
(_c2,StringType)
(_c3,StringType)
(_c4,StringType)
(_c5,StringType)
...
(_c41,StringType)
(_c42,StringType)可以看到原始 schema 为 _1,_2 形式,而设置的 schema 为 A,B... 与之不匹配,所以得到的数据为 null,为什么不匹配,这个涉及到 parquet 的生成逻辑:
(1) 读取原始 hive 表,字段为 A,B,C... 生成 parquet 过程中未设置 schema ,从而存储的 parquet 采用了默认 schema 形式,即 _index 的形式
(2) 而读取 parquet 时认为 parquet 的 schema 为原始 hive 结构,所以设置了错误的 schema,从而导致 schema 规则不匹配,从而得到全 null 的数据
4.问题解决
A.存储 parquet
存储 parquet 时将 hive 表对应列名与属性的 schema 存入 parquet,这样读取时指定相同 schema 即可
B.读取 schema
数据预处理时可以调用 .schema 方法打印数据的 name 和 dataType,指定相同的 name 和 dataType,例如本例中将 A,B,C ... 替换为 _c0,_c1,_c2... 即可正常显示数据
四.总结
spark 加载 parquet 文件时最好可以手动指定 schema ,这样可以避免前期不必要的 merge 操作,优化代码执行速度,非常的好用 👍