kafka是消息队列的一种,记得在web开发中会用类似于rabbitMQ之类的消息中间件以提高交互效率,同时可以在访问高峰期起到缓冲的作用,还有其他各种好处在此就不再展开了。
先来看看消息队列的数据传输模式
推送(消息队列主导):push
可以及时将最新的数据推送到数据下游,但可能导致下游来不及消费的而导致数据积压延迟问题。进而可能导致数据丢失。
拉取(订阅者主导):pull
可以很好的解决数据速率不一致,但会面临订阅者轮询问题,从而导致不必要的资源浪费。
kafka采用拉取的方式对数据进行消费以及follower向leader的数据同步。
一、kafka基本架构
Topic (主题):
简单理解为面向不同业务数据设置的标识符,内部会维持类似于队列的结构,生产者和消费者都是面向主题进行数据传送。
Broker(kafka所在的服务器节点):
一个集群由多个broker组成,一个broker可以维护多个topic(或说更具体点是partition)。
Producer(消息生产者):
向kafka broker推送消息的客户端,可以对接数据上游,按批次发送数据。
Consumer(消息消费者):
向kafka broker拉取消息的客户端,可以对接数据下游,按分区消费数据。
Partition(分区):
从拓展性、负载均衡、消息传送效率考虑。将一个topic划分为多个partition并将其分布到不同的broker上。
Consumer Group(消费者组):
逻辑上的topic订阅者,对于一个topic,为了提高消费效率,一个组下面会设有多个consumer负责消费不同partition上的数据(消息)。为避免重复消费,一个partition同时只能由同一消费者组下面的一个consumer消费;消费者组之间独立消费互不干扰。
Replica(partiton数据副本):
可以根据业务需求对topic下的partition设置副本以提高kafka集群数据的可用性。多个副本间又划分为leader(唯一)和follower(可以有多个),数据请求面向的是leader角色的partiton。
leader(副本老大):
多个partition副本下负责对外服务的副本称为leader;也就是生产者发送数据、消费者消费数据的请求对象。
follower(副本小弟):
负责实时从leader中同步数据,leader发生故障时,在ISR队列中的某个follower会竞选成为新的leader。关于ISR、OSR、AR请见后文。
二、kafka数据存储机制
在实际的存储中,topic作为一个逻辑上的消息分类标识,实际物理存储的是partiton。partiton在broker中以分区方式存在;其在文件结构上表现为一个分区的一个segment作为一个存储目录,再此目录下主要存放.index、.log文件,详细见下图(topicName:mytp):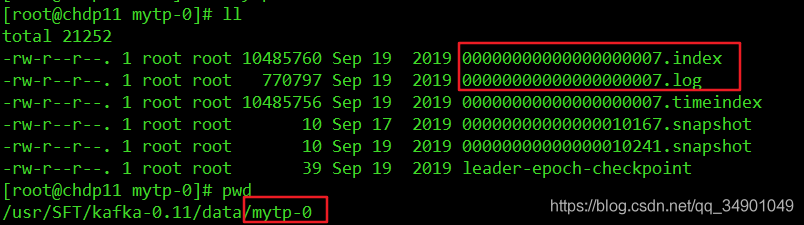
关于这里涉及到kafka的实时数据传输问题,有的小伙伴可能会问:kafka都将数据存储到磁盘了,那还怎么维持他的实时数据传送呢?奥妙就在上面的两个文件中。
首先就是索引机制
producer生产发送的数据会不断的追加写到.log文件下,同时也会在.index文件中保存当前存放在.log文件下数据的偏移量。以便在查询时直接在index文件中取得偏移量进而直接在log文件中快速读取实际的数据。在index文件中存放的是类似于kv(offset,offsetLog)对结构的数据,其中offset是消费者中保存的消费偏移量(为了记录消费位置(offset),避免重复消费或少消费,进而避免数据重复或丢失),offsetLog是在log文件中的文件偏移量(方便快速定位实际数据)。
在某个broker下的partiton数据量比较大时会对其进行分片(segment),以上述为例,也就是会在mytp-0的基础上生成mytp-1的目录结构,以进一步进行索引的横向扩展。(思考:这里会将mytp-0的部分数据平衡切分到mytp-1上吗?为什么呢?kafka采用的是哪种策略?)
三、其他零零总总:
1、关于offset的存储问题
0.9之前的数据保存在zk集群中,一定程度上增加了zk集群负担
0.9版本及之后默认将consumer offset保存在Kafka的一个内置topic(__consumer_offsets)中。
通过java api编程实践发现:
consumer自动开启ENABLE_AUTO_COMMIT_CONFIG(=true)public static final String ENABLE_AUTO_COMMIT_CONFIG = “enable.auto.commit”;在设置为不自动提交offset的情况下,consumer会重复消费上一次以消费过的数据,此时需要手动提交以避免这种情况,offset又分为异步提交以及同步提交。具体见:kafka生产者消费者及拦截器的Java简单示例
2、分区策略:(同一个消费者组里面有消费者数量变化的时候将会启用重新分区,消费者端有两种分配策略:RoundRobin、Range。)
a、方便在集群中扩展、基于分区的多消费者(来自不同消费者组的消费者)同时消费同一topic数据可以提高数据并发量。
b、生产者端可以指定partition、若未指定partition而指定了key的情况下将会以key的hash值对partitionNumber取模得到数据将要发往的分区号。
c、在未指定partition、key的情况下将会在第一次调用该方法时生成一个随机数对partitionnumber取模得到partition,而后在基于这个随机数的基础上进行递增取模,如此就演变成了轮询(round-robin);可以很好的解决负载均衡问题,但要求消费者组里面的消费者订阅的主题要一致,否则容易出问题
d 、range:按主题直接划分范围,可以很好地解决同一消费组内消费者的数据分发错误问题,但会引起数据倾斜问题
e、若消费者的数量(同一个组里)大于分区数量将会导致新增的consumer空转,也就是无法获取到数据,range分区器会发出警告(默认是range)
3、数据可靠性(主要矛盾发生在数据提交与offset保存时间的原子性上)
a、为保证数据发送的准确性(不丢失、不重传),每次producer向下游发送数据后都需要ack反馈才能确定这个数据是发送成功的(就像计算机网络的tcp可靠性传输机制一样),若在发出数据后未在指定等待时间内收到对应的ack将会进行超时重传。
b、同步策略:一个partition往往有一个leader和多个follower,为了保持高可用,发送的数据需要在这些节点间保持同步。副本同步策略有两种;半数机制、全同步
(a)kafka采用的是全同步,只不过这里的全同步并不是指全部follower的同步;leader会维持一组与自己通信状况良好的ISR(In-Sync Replicas),新版本(0.10以后)以通信时延(该时间阈值由replica.lag.time.max.ms参数设定,默认10s)为参考决定follower是否能够留存在ISR中,一个partition有多个副本,每个副本会均匀分布到broker上,未在ISR集合内的副本broker我们称之为OSR(Outof-Sync Replicas),follower的全体称之为AR(Assigned Repllicas)。leader在确认ISR内的所有broker数据同步完成后(默认leader接收到ISR内所有follower的ack),即向producer发送ack确认本批次数据已接收完成,producer在收到对应sck后才可以继续发送数据(同步确认方式下)。
(b)ack发送时机:
0:异步方式,producer发送数据后立即发送下一个数据,不会等待broker响应;
1:半同步,producer发送数据后需要等待leader数据接收存储完毕后才会继续发送;
-1:全同步(kafka默认),producer发送数据后等待leader、ISR所有broker数据接收存储完毕才会继续生产发送数据;
4、kafka高速读写
(1)分布式、分区消费、segnement 索引
(2)文件顺序写磁盘
(3)零拷贝:(采用了cache/buffer ,在OS层面进行了数据传送而不需要拷贝到kafka运用层)
5、zk在kafka中的作用及相关注意点
(1)controller的选举:controller负责集群节点的上下线监控,时刻关注leader是否down机,负责leader的选举,选举备胎为ISR队列
(2)若想重装zk,直接删除dataDir下的version-*文件夹即可
(3)先关闭kafka以保证在zk中的临时id节点自动删除,否则因为id唯一性而导致错误:若发生此错误可以删除zk对应数据节点或修改brokerid解决常用zookeeper命令
(4)offset的存储(kafka0.9之前)
(5)保存broker节点信息
6、kafka事务相关
(1)为保证数据与offset的一致性一般会开启事务将他们保存在mysql或其他事务型数据库中。
(3)注意在exactly once保证的是在生产者端单会话情况下的精准一次性,并无法保证跨分区跨回话的精准一次性。
(4)pid (producer id) ,tid(事务id,若想开启事务需要由用户给定,以保证在需要执行的事务id模块broker之间一致且全局唯一)
7、kafka与flume
kafka适用于下游消费者较多的情况,其动态拓展性较强。并且在先增加下游消费者时不需要像flume那样增加memory channel而致使数据冗余。一般将这两种组合使用,即flume拉取数据交给kafka,由kafka交给下游各消费者。如(数据流向):日志文件-》flume-》kafka -》下游业务逻辑
8、日志分类采集
(1)利用flume的拦截器、channel selecttor
(2)利用flume的kafka-sink:(注意key必须为topic)
9、数据一致性:LEO与HW
为了维持副本间数据一致性,kafka引入了LEO(log end offset,每个副本中最大的offset),HW(high watermark,所有副本最小的offset)。对于消费者来说不能消费HW之后的数据。
(1)follower故障
follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
(2)leader故障
leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
10 Kafka机器数量计算
Kafka机器数量(经验公式)=2*(峰值生产速度*副本数/100)+1
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。
比如我们的峰值生产速度是50M/s。副本数为2。
Kafka机器数量=2*(50*2/100)+ 1=3台