Java8环境下使用restTemplate单/多线程下载大文件和小文件
0. 准备工作
下面使用的restTemplate, 都是使用整合了HttpClient连接池的restTemplate,关于整合可以看我的上一篇文章 ,当然直接使用原生的也是可以的
我这里还使用了VisualVm Launcher的idea插件,来查看运行时的内存够和线程
1. 简单的下载文件
这里使用的是restTemplate调用getForEntity, 获取到字节数组, 再将字节数组通过java8的Files工具类的write方法, 直接写到目标文件.
这里需要注意的点是:
- 会将文件的字节数组全部放入内存中, 及其消耗资源
- 注意目标文件夹不存在,需要手动创建文件夹的问题, 注意生成目标路径的时候,斜杠
\的处理问题
代码如下:
import lombok.extern.slf4j.Slf4j;import org.springframework.http.HttpMethod;import org.springframework.http.MediaType;import org.springframework.http.ResponseEntity;import org.springframework.stereotype.Component;import org.springframework.util.CollectionUtils;import org.springframework.web.client.RequestCallback;import org.springframework.web.client.ResponseExtractor;import org.springframework.web.client.RestTemplate;import org.springframework.web.util.UriComponentsBuilder;import javax.annotation.Resource;import java.io.IOException;import java.nio.file.Files;import java.nio.file.Paths;import java.time.Instant;import java.time.temporal.ChronoUnit;import java.util.Arrays;import java.util.Map;import java.util.Objects;/**
* @Author: zgd
* @Date: 2019/3/29 10:49
* @Description:
*/@Component@Slf4jpublicclassWebFileUtils{/**
* 使用自定义的httpclient的restTemplate
*/@Resource(name="httpClientTemplate")private RestTemplate httpClientTemplate;/**
* 下载小文件,采用字节数组的方式,直接将所有返回都放入内存中,容易引发内存溢出
*
* @param url
* @param targetDir
*/publicvoiddownloadLittleFileToPath(String url, String targetDir){downloadLittleFileToPath(url, targetDir, null);}/**
* 下载小文件,直接将所有返回都放入内存中,容易引发内存溢出
*
* @param url
* @param targetDir
*/publicvoiddownloadLittleFileToPath(String url, String targetDir, Map<String, String> params){
Instant now= Instant.now();
String completeUrl=addGetQueryParam(url, params);
ResponseEntity<byte[]> rsp= httpClientTemplate.getForEntity(completeUrl,byte[].class);
log.info("[下载文件] [状态码] code:{}", rsp.getStatusCode());try{
String path=getAndCreateDownloadDir(url, targetDir);
Files.write(Paths.get(path), Objects.requireNonNull(rsp.getBody(),"未获取到下载文件"));}catch(IOException e){
log.error("[下载文件] 写入失败:", e);}
log.info("[下载文件] 完成,耗时:{}", ChronoUnit.MILLIS.between(now, Instant.now()));}/**
* 拼接get请求参数
*
* @param url
* @param params
* @return
*/private StringaddGetQueryParam(String url, Map<String, String> params){
UriComponentsBuilder uriComponentsBuilder= UriComponentsBuilder.fromHttpUrl(url);if(!CollectionUtils.isEmpty(params)){for(Map.Entry<String,?> varEntry: params.entrySet()){
uriComponentsBuilder.queryParam(varEntry.getKey(), varEntry.getValue());}}return uriComponentsBuilder.build().encode().toString();}/**
* 创建或获取下载文件夹的路径
*
* @param url
* @param targetDir
* @return
*/public StringgetAndCreateDownloadDir(String url, String targetDir)throws IOException{
String filename= url.substring(url.lastIndexOf("/")+1);int i=0;if((i= url.indexOf("?"))!=-1){
filename= filename.substring(0, i);}if(!Files.exists(Paths.get(targetDir))){
Files.createDirectories(Paths.get(targetDir));}return targetDir.endsWith("/")? targetDir+ filename: targetDir+"/"+ filename;}}这里找到一个搜狗浏览器的下载地址, 运行代码,并启动.
package com.zgd.springboot.demo.http.test;import com.alibaba.fastjson.JSON;import com.google.common.collect.Maps;import com.google.common.util.concurrent.ThreadFactoryBuilder;import com.zgd.springboot.demo.http.HttpApplication;import com.zgd.springboot.demo.http.IO.utils.DownloadTool;import com.zgd.springboot.demo.http.IO.utils.QiniuUtil;import com.zgd.springboot.demo.http.IO.utils.WebFileUtils;import com.zgd.springboot.demo.http.service.IHttpService;import lombok.extern.slf4j.Slf4j;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.stereotype.Component;import org.springframework.test.context.TestPropertySource;import org.springframework.test.context.junit4.SpringRunner;import javax.annotation.Resource;import java.time.Instant;import java.time.temporal.ChronoUnit;import java.util.HashMap;import java.util.concurrent.*;/**
* @Author: zgd
* @Date: 2019/3/25 15:56
* @Description:
*/@Component@RunWith(SpringRunner.class)@SpringBootTest(classes= HttpApplication.class)@TestPropertySource("classpath:application.yml")@Slf4jpublicclassSpringTest{@Resourceprivate WebFileUtils webFileUtils;@TestpublicvoidtestDownloadQiniu(){
String path="D:/down/file/";
String url="http://cdn4.mydown.com/5c9df131/6dcdc2f2ff1aba454f90d8581eab1820/newsoft/sogou_explorer_fast_8.5.7.29587_7685.exe";
webFileUtils.downloadLittleFileToPath(url,path);}}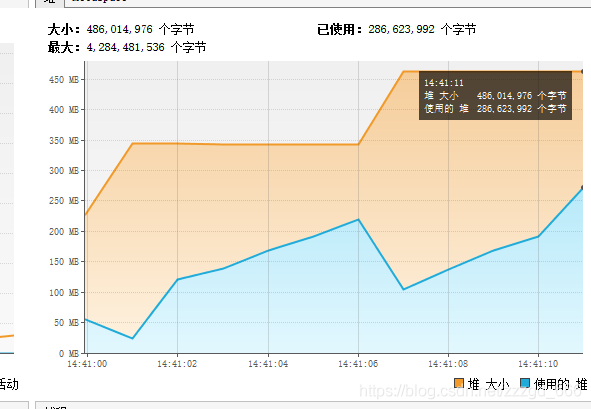
可以看到使用内存从一开始的100多M,后面飙升到300多M. 总耗时是8533ms.
为了更好的展示这个方法对内存的占用,下载一个500M左右的Idea看看
String url="https://download.jetbrains.8686c.com/idea/ideaIU-2019.1.exe";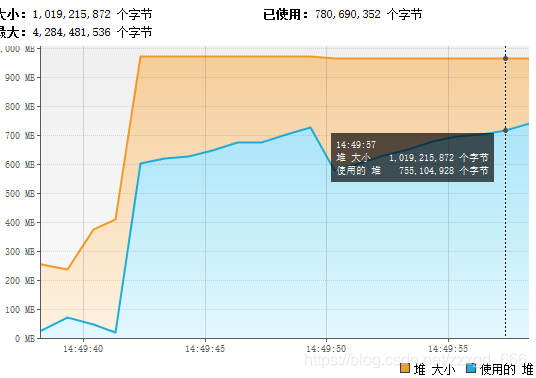
可以看到占用内存一度达到900多M, 这才下载500M的软件,如果我们需要服务器下载几G的文件,内存肯定是不够用的.
至于下载时间,速度是300k/s左右,实在没耐心等500M的下载了
2. 单线程大文件下载
既然上面的方法只能下载小文件,那么大文件怎么办呢? 我们使用流的方式来解决. 在上面的类里加l两个方法. 这次使用Files的copy方法来处理流.
/**
* 下载大文件,使用流接收
*
* @param url
* @param targetDir
*/publicvoiddownloadBigFileToPath(String url, String targetDir){downloadBigFileToPath(url,targetDir,null);}/**
* 下载大文件,使用流接收
*
* @param url
* @param targetDir
*/publicvoiddownloadBigFileToPath(String url, String targetDir, Map<String, String> params){
Instant now= Instant.now();
String completeUrl=addGetQueryParam(url, params);try{
String path=getPathAndCreateDownloadDir(url, targetDir);//定义请求头的接收类型
RequestCallback requestCallback= request-> request.getHeaders().setAccept(Arrays.asList(MediaType.APPLICATION_OCTET_STREAM, MediaType.ALL));// getForObject会将所有返回直接放到内存中,使用流来替代这个操作
ResponseExtractor<Void> responseExtractor= response->{// Here I write the response to a file but do what you like
Files.copy(response.getBody(), Paths.get(path));// downloadByByteBuffer(path, response);return null;};
httpClientTemplate.execute(completeUrl, HttpMethod.GET, requestCallback, responseExtractor);}catch(IOException e){
log.error("[下载文件] 写入失败:", e);}
log.info("[下载文件] 完成,耗时:{}", ChronoUnit.MILLIS.between(now, Instant.now()));}先试试那个50M的搜狗浏览器:
看到内存基本保持在100M左右,总耗时:5514ms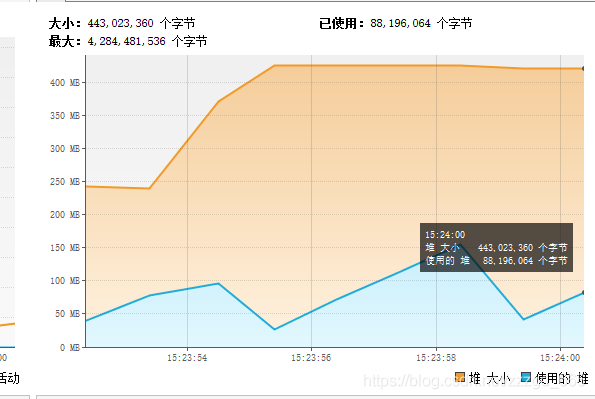

再试试那个500M的Idea:内存基本稳定在150M以内,下载速度也是300kb/s左右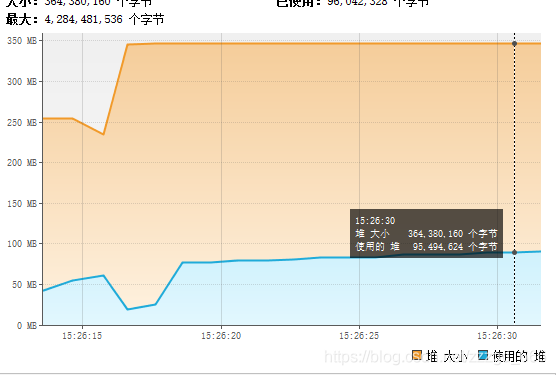
可以看得出, 使用流的方式还是可以很好的保证内存资源不会崩掉的
3. 多线程下载
上面虽然把大文件的问题解决了 ,但是下载速度300k/s实在是太慢了.虽然小文件还是可以达到5s左右下载完50M,但是大文件还是需要更快的下载速度(下载速度也取决于当前的运营商网速和资源)
主要就是先调用一次HEAD方法去获取到文件大小, 我这里默认开启了10个线程,然后每个线程分配好下载的数据量,在请求头中设置Range属性,分别去下载属于它那一部分的数据,然后最后合并成一个文件
直接上代码吧:
package com.zgd.springboot.demo.http.IO.utils;import com.google.common.collect.Lists;import com.google.common.util.concurrent.ThreadFactoryBuilder;import lombok.extern.slf4j.Slf4j;import org.springframework.http.*;import org.springframework.stereotype.Component;import org.springframework.util.Assert;import org.springframework.web.client.RequestCallback;import org.springframework.web.client.ResponseExtractor;import org.springframework.web.client.RestTemplate;import javax.annotation.Resource;import java.io.File;import java.io.IOException;import java.io.RandomAccessFile;import java.nio.file.Files;import java.nio.file.Paths;import java.util.ArrayList;import java.util.Arrays;import java.util.Collections;import java.util.Objects;import java.util.concurrent.*;/**
* Created by yangzheng03 on 2018/1/16. https://www.dubby.cn/
*/@Component@Slf4jpublicclassDownloadTool{/**
* 使用自定义的httpclient的restTemplate
*/@Resource(name="httpClientTemplate")private RestTemplate httpClientTemplate;@Resourceprivate WebFileUtils webFileUtils;/**
* 线程最小值
*/privatestaticfinalint MIN_POOL_SIZE=10;/**
* 线程最大值
*/privatestaticfinalint MAX_POOL_SIZE=100;/**
* 等待队列大小
*/privatestaticfinalint WAIT_QUEUE_SIZE=1000;/**
* 线程池
*/privatestatic ExecutorService threadPool;privatestaticfinalint ONE_KB_SIZE=1024;/**
* 大于20M的文件视为大文件,采用流下载
*/privatestaticfinalint BIG_FILE_SIZE=20*1024*1024;privatestatic String prefix= String.valueOf(System.currentTimeMillis());publicvoiddownloadByMultiThread(String url, String targetPath, Integer threadNum){long startTimestamp= System.currentTimeMillis();//开启线程
threadNum= threadNum== null? MIN_POOL_SIZE: threadNum;
Assert.isTrue(threadNum>0,"线程数不能为负数");
ThreadFactory factory=newThreadFactoryBuilder().setNameFormat("http-down-%d").build();
threadPool=newThreadPoolExecutor(
threadNum, MAX_POOL_SIZE,0, TimeUnit.MINUTES,newLinkedBlockingDeque<>(WAIT_QUEUE_SIZE), factory);boolean isBigFile;//调用head方法,只获取头信息,拿到文件大小long contentLength= httpClientTemplate.headForHeaders(url).getContentLength();
Assert.isTrue(contentLength>0,"获取文件大小异常");
isBigFile= contentLength>= BIG_FILE_SIZE;if(contentLength>1024* ONE_KB_SIZE){
log.info("[多线程下载] Content-Length\t{} ({})", contentLength,(contentLength/1024/1024)+"MB");}elseif(contentLength> ONE_KB_SIZE){
log.info("[多线程下载] Content-Length\t{} ({})", contentLength,(contentLength/1024)+"KB");}else{
log.info("[多线程下载] Content-Length\t"+(contentLength)+"B");}
ArrayList<CompletableFuture<DownloadTemp>> futures= Lists.newArrayListWithCapacity(threadNum);
String fileFullPath;
RandomAccessFile resultFile;try{
fileFullPath= webFileUtils.getPathAndCreateDownloadDir(url, targetPath);//创建目标文件
resultFile=newRandomAccessFile(fileFullPath,"rw");
log.info("[多线程下载] Download started, url:{}\tfileFullPath:{}", url, fileFullPath);//每个线程下载的大小long tempLength=(contentLength-1)/ threadNum+1;long start, end;int totalSize=0;for(int i=0; i< threadNum&& totalSize< contentLength;++i){//累加
start= i* tempLength;
end= start+ tempLength-1;
totalSize+= tempLength;
log.info("[多线程下载] start:{}\tend:{}", start, end);
DownloadThread thread=newDownloadThread(httpClientTemplate, i, start, end, url, fileFullPath, isBigFile);
CompletableFuture<DownloadTemp> future= CompletableFuture.supplyAsync(thread::call, threadPool);
futures.add(future);}}catch(Exception e){
log.error("[多线程下载] 下载出错", e);return;}finally{
threadPool.shutdown();}//合并文件
futures.forEach(f->{try{
f.thenAccept(o->{try{
log.info("[多线程下载] {} 开始合并,文件:{}", o.threadName, o.filename);
RandomAccessFile tempFile=newRandomAccessFile(o.filename,"rw");
tempFile.getChannel().transferTo(0, tempFile.length(), resultFile.getChannel());
tempFile.close();
File file=newFile(o.filename);boolean b= file.delete();
log.info("[多线程下载] {} 删除临时文件:{}\t结果:{}", o.threadName, o.filename, b);}catch(IOException e){
e.printStackTrace();
log.error("[多线程下载] {} 合并出错", o.threadName, e);}}).get();}catch(Exception e){
log.error