文章目录
1.机器学习
1.什么是机器学习
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
它是人工智能的核心,是使计算机具有智能的根本途径。
2.机器学习基础所用到的库
1.Numpy库
NumPy系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比 Python 自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。
一个用python实现的科学计算,包括:
1、一个强大的N维数组对象Array;
2、比较成熟的(广播)函数库;
3、用于整合C/C++和Fortran代码的工具包;
4、实用的线性代数、傅里叶变换和随机数生成函数。numpy和稀疏
矩阵运算包scipy配合使用更加方便。
NumPy(Numeric Python)提供了许多高级的数值编程工具,如:矩阵数据类型、矢量处理,以及精密的运算库。专为进行严格的数字处理而产生。多为很多大型金融公司使用,以及核心的科学计算组织如:Lawrence Livermore,
NASA用其处理一些本来使用C++,Fortran或Matlab等所做的任务。
2.Pandas库
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
Pandas是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
3.Matplotlib库
Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形
通过 Matplotlib,开发者可以仅需要几行代码,便可以生成绘图,直方图,功率谱,条形图,错误图,散点图等。
Matplotlib基础知识:
1.Matplotlib基本图表
2.hold属性(默认为True,允许一个图中绘制多个曲线)
3.网格线(使用grid方法为图添加网格线,设置grid参数)
4.axis方法
5.xlim方法和ylim方法
6.legend方法
4.scikit-learn库(主要机器学习库)
Scikit learn 也简称 sklearn, 是机器学习领域当中最知名的 python 模块之一
Sklearn 包含了很多种机器学习的方式:
Classification 分类
Regression 回归
Clustering 非监督分类
Dimensionality reduction 数据降维
Model Selection 模型选择
Preprocessing 数据预处理
3.机器学习算法概述
机器学习分为两种学习算法:
1.监督学习(人为让计算机学习)示例:
a.回归问题
b.分类问题
2.非监督学习(让计算机自己学习)示例:
a.聚类算法(例:谷歌新闻分类和推荐)
b.鸡尾酒会算法(例:鸡尾酒会麦克风问题,市场细分问题)
4.KNN算法
1.算法介绍
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。Cover和Hart在1968年提出了最初的邻近算法。KNN是一种分类(classification)算法,它输入基于实例的学习(instance-based learning),属于懒惰学习(lazy learning)即KNN没有显式的学习过程,也就是说没有训练阶段,数据集事先已有了分类和特征值,待收到新样本后直接进行处理。与急切学习(eager learning)相对应。
KNN是通过测量不同特征值之间的距离进行分类。
思路是:如果一个样本在特征空间中的k个最邻近的样本中的大多数属于某一个类别,则该样本也划分为这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
提到KNN,网上最常见的就是下面这个图,可以帮助大家理解。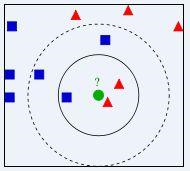
我们要确定绿点属于哪个颜色(红色或者蓝色),要做的就是选出距离目标点距离最近的k个点,看这k个点的大多数颜色是什么颜色。当k取3的时候,我们可以看出距离最近的三个,分别是红色、红色、蓝色,因此得到目标点为红色。
2.底层实现
#打开文件
import numpy as np
from numpy import loadtxt
with open(r"E:\火狐下载\wine.csv","rt",encoding='UTF-8') as raw_data:
data=loadtxt(raw_data,delimiter=',')
#文件打开
print(data)这里引用文件位置时用的是绝对位置
所用葡萄酒数据集可在CSDN上下载
#数据载入
X1 = data[:,1:]
y1 = data[:,:1]
#读取文件数据
y = []
for i in y1:
y.append(int(i))
#将酒的种类统一进一个数组
#np.random.seed(666)
all_indexes = np.random.permutation(len(X1))
#生成随机数作为数据索引并确定随机数
print(all_indexes)
test_ratio = 0.3
test_size = int(len(X1) * test_ratio)
test_size
#确定测试比例
#print(X1)
#print(y)#数据归一化
def shujuguiyi(a,b,M):
j = 0
guiyi = np.empty([a,b]) #empty函数
for j in range(b):
guiyi[:,j] = (M[:,j] - np.mean(M[:,j])) / np.std(M[:,j]) #数据归一化标准差法
return guiyi
#定义数据归一函数
X = shujuguiyi(178,13,X1)
#X
#用数据归一函数将所有特征数据对结果计算的影响维持在一定范围内#底层实现
test_indexes = all_indexes[:test_size]
train_indexes = all_indexes[test_size:]
#确定测试数据索引和训练数据索引
X_train = np.array(X)[train_indexes]
y_train = np.array(y)[train_indexes]
X_test = np.array(X)[test_indexes]
y_test = np.array(y)[test_indexes]
#确定训练集与测试集
#print(X_train)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
from math import sqrt
from collections import Counter #collections库里引用Counter函数
#定义KNN函数以预测一个测试数据的种类
def KNN_1(k,X_train,y_train,x):
distances = []
for x_train in X_train:
d = sqrt(np.sum((x_train - x)**2))
distances.append(d)
#distances
#计算欧拉距离
np.argsort(distances)
nearest = np.argsort(distances)
#print(nearest)
#对距离进行升序排序并取其对应的索引
topk_y = [y_train[i] for i in nearest[:k]]
#print(topk_y)
Counter(topk_y)
#统计该测试数据周边的点对应的种类
votes = Counter(topk_y)
votes.most_common(1)[0][0]
return votes.most_common(1)[0][0] #。.most_common用法
#找出出现最多的点并取其为预测值#计算预测准确率
y_predict = [KNN_1(6,X_train,y_train,x) for x in X_test]
np.array(y_predict)
print(y_predict)
#对所有测试数据进行预测并统计为一个array数组
print(y_test)
#取出所有测试的数据对应的真实种类
print(np.sum(y_predict == y_test)/len(y_test))
#对两者进行比较并计算出正确率3.sklearn算法实现
#对所有的数据进行随机取测试集与训练集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=666)#取预测函数并确定k
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=6)#对训练集执行knn
knn_clf.fit(X_train,y_train) #显示函数参数#运用predict函数预测结果
y_predict = knn_clf.predict(X_test)#比较预测结果与实际结果
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_predict)#调参:K
best = 0.0
best_k = -1
for k in range(1,125):
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train,y_train)
y_predict = knn_clf.predict(X_test)
score = accuracy_score(y_test,y_predict)
if best < score:
best = score
best_k = k
print(best)
print(best_k)