在实验室参与开发了一个评测平台。在使用的时候有部分攻击算法会出现显存溢出的情况。同时随着样本数增加,这种显存占用比会同比增加。而不是和预先设定的一样,仅和设置的batch_size相关。如此一来,对于一些占用显存本身就较大的算法,当样本数增加时,Docker虚环境肯定会崩溃。下面将给出我的整个搜索+解决问题的过程。
写在最前面的话
这个问题目前已经解决,最终发现报错的原因是,开发那边没有正确的把batch_size传入攻击算法中,导致出现了可能只有1张图像,但是开了一个65倍图像尺寸的空间(实际上3就够了),然后这个空间作为输入传入模型,导致占用显存过多。
在排查问题的过程中,马佬告诉我,其实Pytorch之类的都会有自动回收机制,需要保证的其实是
for循环中的变量,如果是显存上的,尽量不要让他离开for循环范围!
按照GC的原理,是引用计数的,当某个局部变量不存在引用的时候,会自动回收。因此如果for循环内部/外部有引用,都会导致某些中间变量一直被持有。
举个例子:
losses=[]for iinrange(233):
x= Variable(input).to(device) 此时x在GPU上
output= self.model(x) 此时output也在GPU上
losses.append(output) 这句话将可能导致存储了output梯度,并由于持有output对象导致他不会在每次for循环后释放
y= x+... 这句话在for循环外,等于for循环结束的时候,x仍存在未来的引用可能,此时的x不会被回收可以修改的方式有很多,比如在for循环内部losses.append一句中,可以把output转成cpu上资源。以及将y = 这一句考虑能不能删去。
下面是正文:首先列举全部搜索到的问题,直接跳到最后有几个定位bug小方法。
问题一 记录累计信息时直接使用了输出的Variable
这个问题的发现,是参考了这篇知乎回答《pytorch的坑—loss没写好,显存爆炸》
原贴就问题的描述:
算是动态图的一个坑吧。记录loss信息的时候直接使用了输出的Variable。
for data, labelin trainloader: out= model(data) loss= criterion(out, label) loss_sum+= loss# <--- 这里运行着就发现显存炸了。观察了一下发现随着每个batch显存消耗在不断增大…
参考了别人的代码发现那句loss一般是这样写:loss_sum+= loss.data[0]这是因为输出的loss的数据类型是Variable。而PyTorch的动态图机制就是通过Variable来构建图。主要是使用Variable计算的时候,会记录下新产生的Variable的运算符号,在反向传播求导的时候进行使用。
如果这里直接将loss加起来,系统会认为这里也是计算图的一部分,也就是说网络会一直延伸变大,那么消耗的显存也就越来越大
总之使用Variable的数据时候要非常小心。不是必要的话尽量使用Tensor来进行计算…
问题二 for循环过程中的迭代变量
参考讨论帖《Tensor to Variable and memory freeing best practices》
在这篇帖子中有提到,Variable和Tensor实际上共用的是一块内存空间。所以在使用了Variable之后,del掉相应的Variable。不会带来明显的内存释放。唯一可能带来一定效果的,是在for循环过程中,如
for i,(x, y)inenumerate(train_loader):
x= Variable(x)
y= Variable(y)# compute model and updatedel x, y, outputx和y本身作为train_loader中内容,会占用一块内存,而循环时,会产生一块临时内存。帖子中回复认为,此处可以节省一点点。需要注意的是,还需要额外删去引用到x和y的变量,否则仍然存在占用。
问题三 多次训练,GPU未释放
参考自讨论帖《How can we release GPU memory cache?》
这个帖子中描述的解决办法为,当GPU计算完毕后,把相应的变量和结果转成CPU,然后调用GC,调用torch.cuda.empty_cache()
defwipe_memory(self):# DOES WORK
self._optimizer_to(torch.device('cpu'))del self.optimizer
gc.collect()
torch.cuda.empty_cache()def_optimizer_to(self, device):for paramin self.optimizer.state.values():# Not sure there are any global tensors in the state dictifisinstance(param, torch.Tensor):
param.data= param.data.to(device)if param._gradisnotNone:
param._grad.data= param._grad.data.to(device)elifisinstance(param,dict):for subparamin param.values():ifisinstance(subparam, torch.Tensor):
subparam.data= subparam.data.to(device)if subparam._gradisnotNone:
subparam._grad.data= subparam._grad.data.to(device)问题四 torch.load的坑
参考自知乎回答《PyTorch 有哪些坑/bug? - 知乎用户的回答》
该回答中描述,当你使用:
checkpoint= torch.load("checkpoint.pth")
model.load_state_dict(checkpoint["state_dict"])这样load一个 pretrained model 的时候,torch.load() 会默认把load进来的数据放到0卡上,这样每个进程全部会在0卡占用一部分显存。解决的方法也很简单,就是把load进来的数据map到cpu上:
checkpoint= torch.load("checkpoint.pth", map_location=torch.device('cpu'))
model.load_state_dict(checkpoint["state_dict"])按照马佬的建议,此处如果不想用到cpu的话,也可以map_location=rank。具体的写法参考了《pytorch源码》以及《pytorch 分布式训练 distributed parallel 笔记》
# 获取GPU的rank号
gpu= torch.distributed.get_rank(group=group)# group是可选参数,返回int,执行该脚本的进程的rank# 获取了进程号后
rank='cuda:{}'.format(gpu)
checkpoint= torch.load(args.resume, map_location=rank)问题五 pretrain weights问题
参考自之乎回答《PyTorch 有哪些坑/bug? - 鲲China的回答》
在做交叉验证的时候,每折初始化模型,由于用到了pretrained weights,这时候显存不会被释放,几折过后显存就爆炸了~,这时候用三行代码就可以解决这个问题
del model
gc.collect()
torch.cuda.empty_cache()问题六 不做backward,中间变量会保存
参考自《PyTorch 有哪些坑/bug? - hjy666的回答》

但是上述方法是0.4中的解决方法。pytorch0.4到pytrch1.0跨度有点大,variable跟tensor合并成tensor了,不能设置volatile 参数,所以在做evaluation时很容易出现out of memory的问题。所以你需要在最后的loss和predict输出设置
.cpu().detach()比如说:
total_loss.append(loss.cpu().detach().numpy())
total_finish_loss.append(finish_loss.cpu().detach().numpy())尝试解决问题
方法一:全局查找字符串
全局查找累计过程,由于主要是+=的问题,所以grep +=试试:
$grep -rn"+=" ./得到结果
zaozhe@ /d/LABOR/SUIBUAA_AIEP(dev_aiep)
$grep -rn"+=" ./
Binaryfile ./Datasets/ImageNet/images/ILSVRC2012_val_00000005.JPEG matches
Binaryfile ./Datasets/ImageNet/images/ILSVRC2012_val_00000006.JPEG matches
Binaryfile ./Datasets/ImageNet/images/ILSVRC2012_val_00000007.JPEG matches
Binaryfile ./Datasets/ImageNet/images/ILSVRC2012_val_00000008.JPEG matches
./EvalBox/Defense/anp.py:100: total += inputs.shape[0]
./EvalBox/Defense/anp.py:101: correct +=(preds== labels).sum().item()
./EvalBox/Defense/eat.py:223: total += inputs.shape[0]
./EvalBox/Defense/eat.py:224: correct +=(preds== labels).sum().item()...但是搜索结果中存在很多的Binary file文件,把所有搜索结果拷贝到sublime中,ctrl + F搜索全部包含"Binary file"字样的搜索行,使用ctrl + shift + K一键删除所有匹配行。
$grep -rn"+=" ./
./EvalBox/Analysis/grad-cam.py:36: outputs +=[x]
./EvalBox/Analysis/grad-cam.py:134: cam += w * target[i, :, :]
./EvalBox/Analysis/grand_CAM.py:32: outputs +=[x]
./EvalBox/Analysis/grand_CAM.py:109: cam += w * target[i, :, :]
./EvalBox/Analysis/Rebust_Defense.py:66: total += inputs.shape[0]
./EvalBox/Analysis/Rebust_Defense.py:67: correct +=(preds== labels).sum().item()
./EvalBox/Attack/AdvAttack/deepfool.py:105: loop_i += 1
./EvalBox/Attack/AdvAttack/deepfool.py:137: loop_i += 1
./EvalBox/Attack/AdvAttack/ead.py:208: cnt += 1...然后再手动筛选掉与该问题无关的行,如上方示例中deepfool中的+=1,这里并不会产生问题一中,无用梯度不释放问题。然后这里我很快就定位到了具体的py文件中,有这么一行
output= model(xs)方法二:确定输入输出尺寸
这一步很简单,就是在你觉得不妥的变量上,输出一下他的尺寸看看
print("in line xxx, the var xs 's shape = ", xs.shape)加一些提示语,然后看看会不会是传入的图像太大了。
我遇到的实际问题就是因为,攻击算法执行过程中,用于做扰动处理的预空间维度太高。按照马佬的测试,1张3 * 244 * 244的ImageNet图像,在VGG模型上执行预测,约占用显存1.6G。而我传入的是80 * 3 * 375 * 500的输入,所以显存爆炸。改为3 * 3 * 375 * 500之后,显存就可以正常供给了。
方法三:如何查看实时的GPU使用率
这个也是debug过程中很苦恼的东西,想知道是不是在某一步的时候,传到显存上的东西太多了,但是又不方便单步调试。
使用指令nvidia-smi可以看到当前的GPU使用率,大致如图: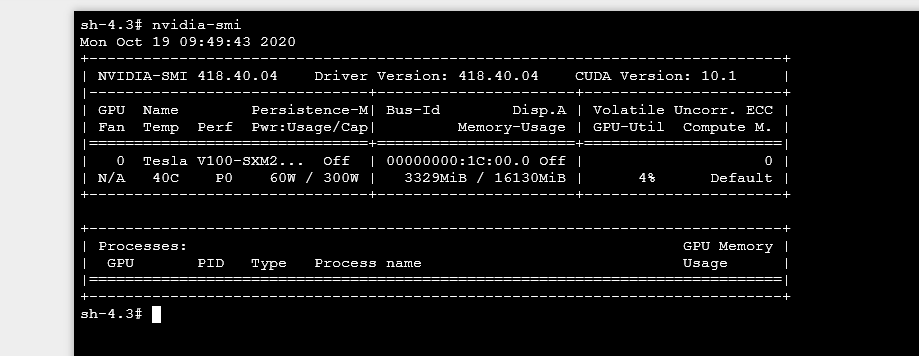
但是我想要的是在执行过程中,执行的同时,获取具体的GPU使用情况。这里我参考了这篇博客《使用python中的GPUtil库从NVIDA GPU获取GPU状态》
这里面用到了一个第三方库叫GPUtil,执行pip install gputil即可完成下载。然后我封装了一个函数:
defget_gpu_info(self, text=""):print("当前行为为:", text)
GPUtil.showUtilization()defpredict(self, xs, model):
var_xs= Variable(xs.to(device))
self.get_gpu_info("将xs传入GPU")for iinrange(100):for jinrange(200):
output= model(var_xs)
self.get_gpu_info("执行一次预测过程")
some work there...
self.get_gpu_info("内层循环迭代完毕,查看是否正确释放显存")而这个的输出类似于下图。最好还是添加一个输出提示,因为他如果没有提示做分割的话,其实不是很方便看到底执行到哪里了。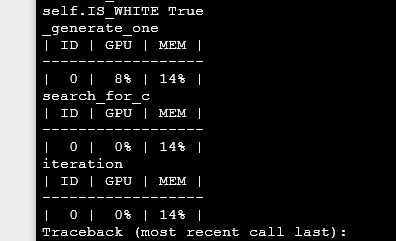
在这篇参考博客中,我看到有这么一段代码
import GPUtilimport timewhileTrue:
Gpus= GPUtil.getGPUs()for gpuin Gpus:print('GPU总量', gpu.memoryTotal)print('GPU使用量', gpu.memortUsed)
time.sleep(5)他这里的意思是不停的输出GPU的总量和使用量。但是我实际使用过程中发现,好像并不是非常的好用,具体情况见下图。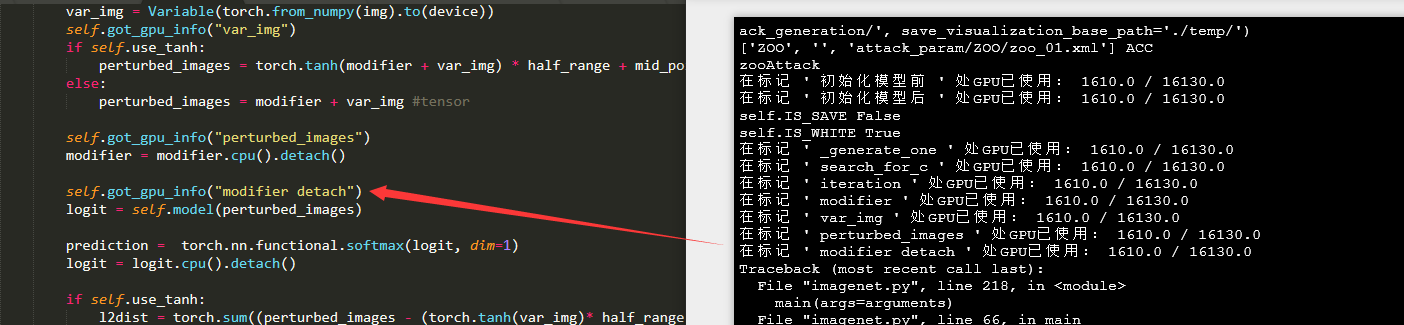
可以看到右边是我的一个实测结果,虽然我中间改变了GPU的使用情况,但是输出的值基本没变。不知道是更新不够快还是如何。我一开始以为是更新不够快,但是我发现哪怕程序一开始,他都可能会显示已经占用了部分的显存资源。所以我就改用了上面的那个GPUtil.showUtilization()
方法四:找大腿问问
如果debug实在是太难了,也不要一门心思去找自己的问题,找个小伙伴问问。描述给他人的同时你也会更了解问题所在,而且有可能对方一语道破!