1、概念
- Requests是python爬虫十分常用的库,其基于urllib编写,采用Apache2 Licensed开源协议的HTTP库。与urllib和urllib3相比,Requests更加方便,可以节约我们大量的工作,因此建议爬虫新手从使用Requests库开始。
- Requests库获取网页数据主要有post()方法与get()方法。
- post()一般用于向网站传递特定参数,以获取特定结果。此参数指的是网站必须接受的参数,根据这些参数返回不同的结果。如百度翻译,传入不同的内容,返回不同的翻译。
- get()方法一般不需网站设置的特定参数,其可传入url、headers、proxies等一般参数(主要用于伪装成浏览器、反爬等,注意与上述特定参数进行区别)。url为网站链接;headers为网站请求头,也可通过浏览器检查功能获取;proxies为代理,将在后续教程进行讲解。
2、安装
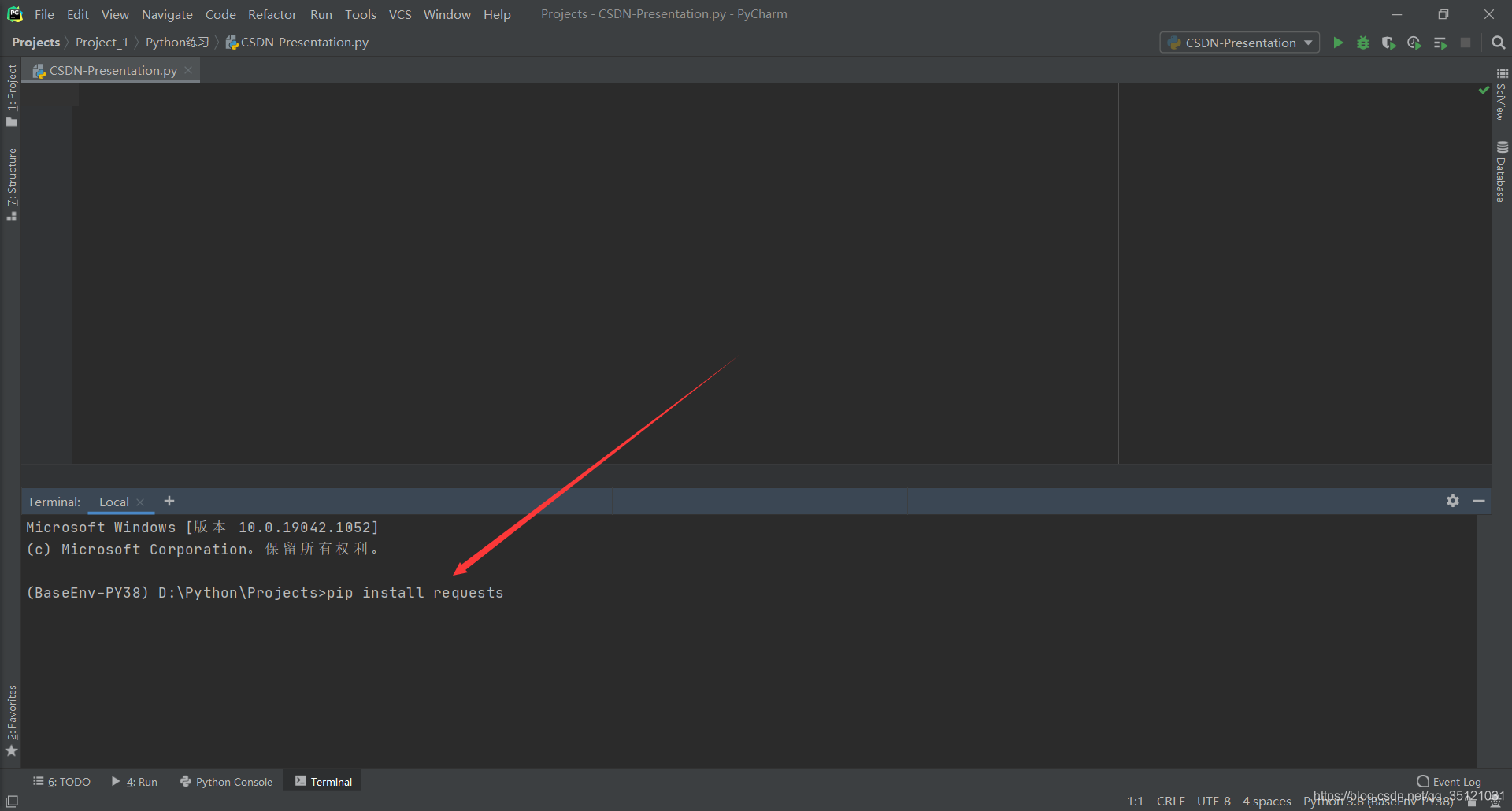
- 打开Pycharm,点击下方Terminal,键入 pip install requests,回车,开始自动安装。
3、代码
新建一个Python文件,import语句导入Requests库。
以豆瓣Top250电影网站为例(豆瓣Top250电影),定义一个Url变量存储此链接。
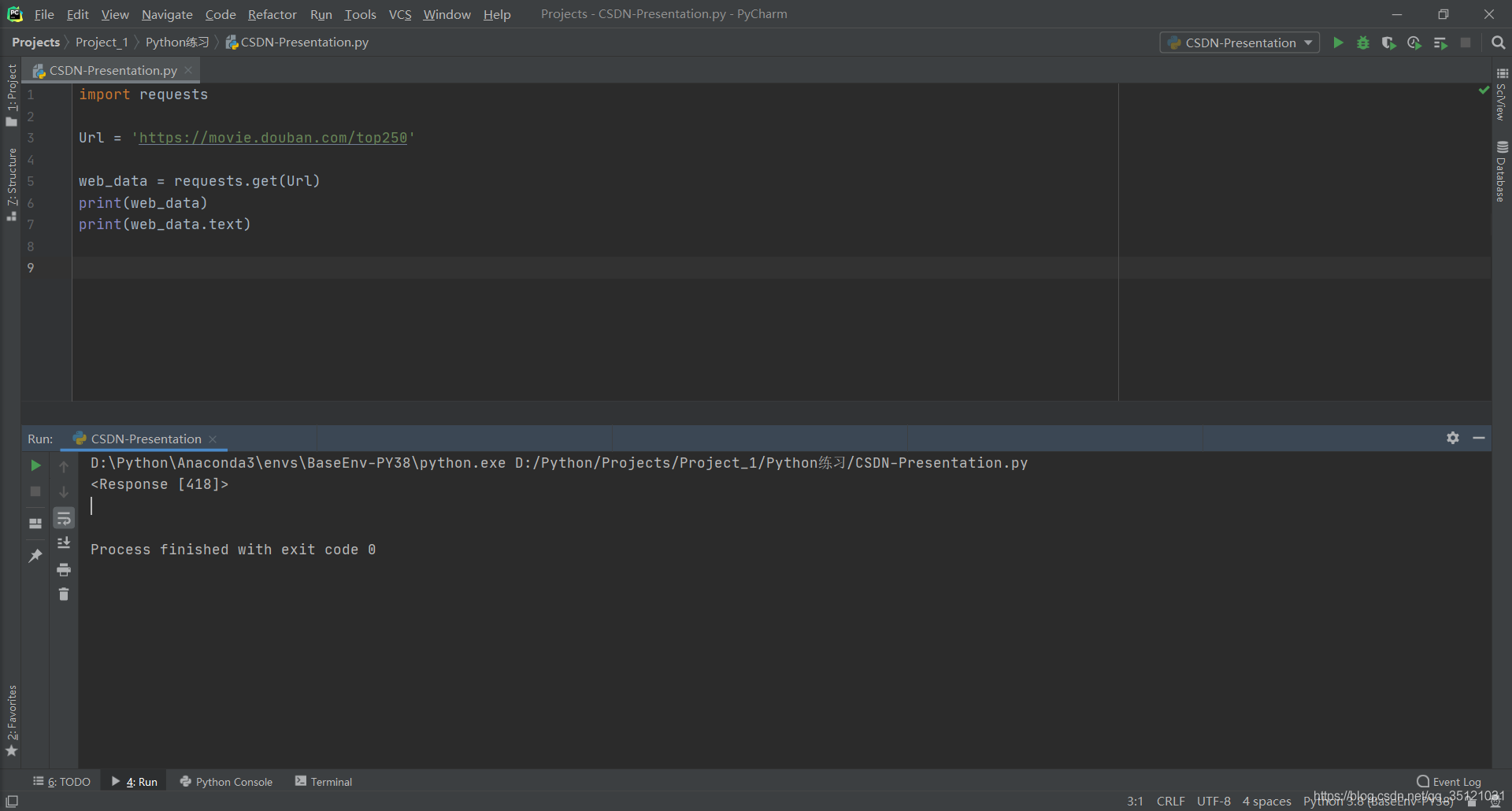
由于豆瓣Top250电影网站并不需要我们传入特定参数,即可查看电影列表,故使用get()进行网页请求,以获取网页数据。
使用get()方法,传入Url,向网站发起请求,将返回内容存到web_data变量中,并打印结果。可以看到下图中打印出来的结果是<Response [418]>,<>表示这是一个对象,也就是我们这里获取的是一个Response的对象,418表示状态码。一般状态码为200即成功访问,418表明我们访问失败,使用.test查看返回内容,打印出来也为空。
这时就需要加上headers,进入豆瓣Top250电影网站,按下F12打开检查功能,点击Network,再按F5刷新网页,可以看到出现了许多请求,找到第一个名为“ top250 ”的请求,点击,右方出现详细内容,包括General、Response Headers、Requests Headers。拉到Requests Headers最下方,会发现User-Agent属性,这个属性记录了浏览器信息,便于豆瓣服务器识别发起请求的为浏览器。
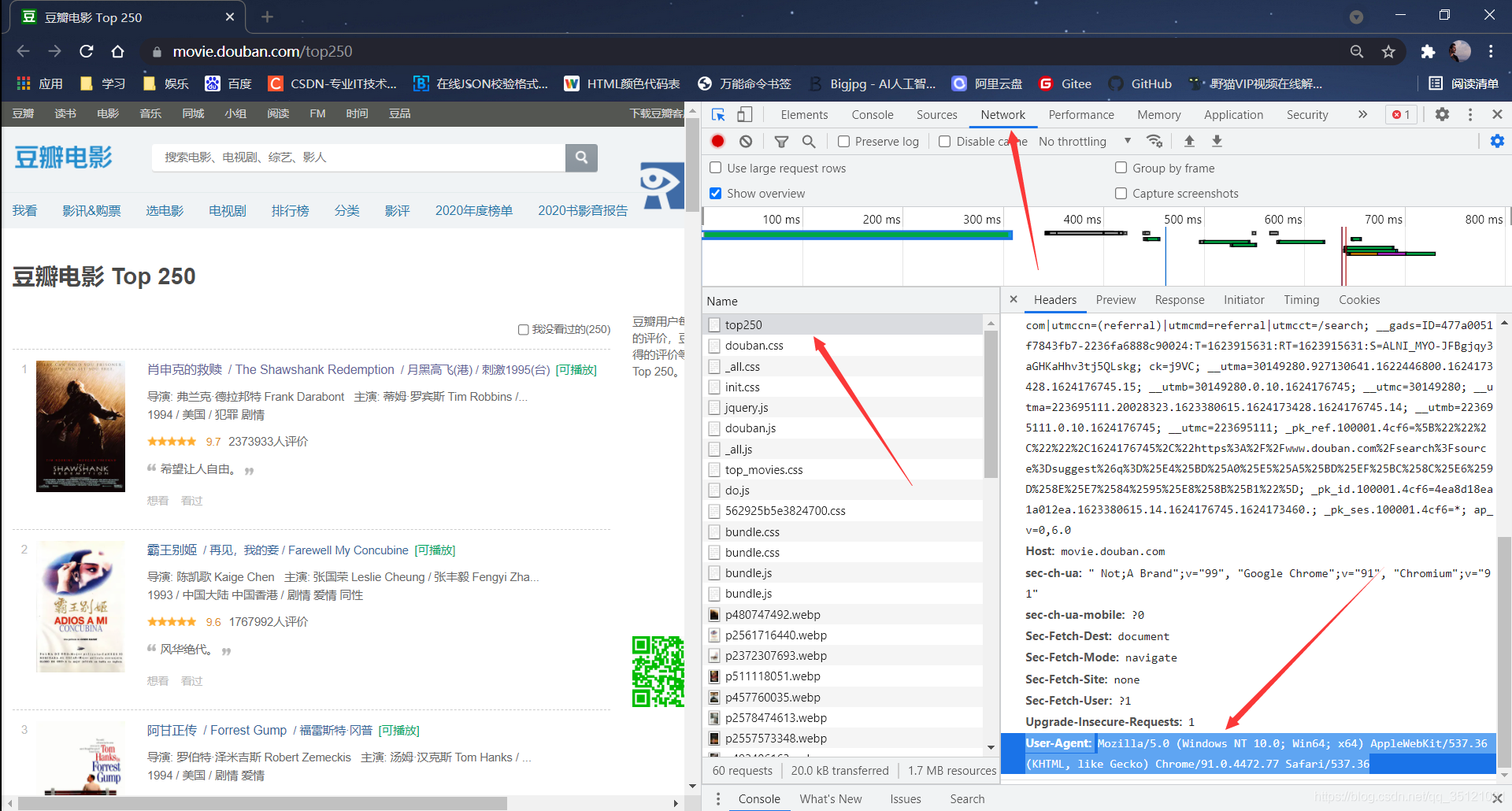
复制User-Agent及冒号后面的内容,创建名为Headers的字典,将User-Agent内容粘贴进去。在get()方法中,指定headers参数为Headers字典。
再次运行,可见输出结果第一行状态码为200,访问成功;第二行及后续内容就是网页源代码。至此,Requests库的使命就完成了,它为我们获取了网页源代码,为后续操作打下基础。
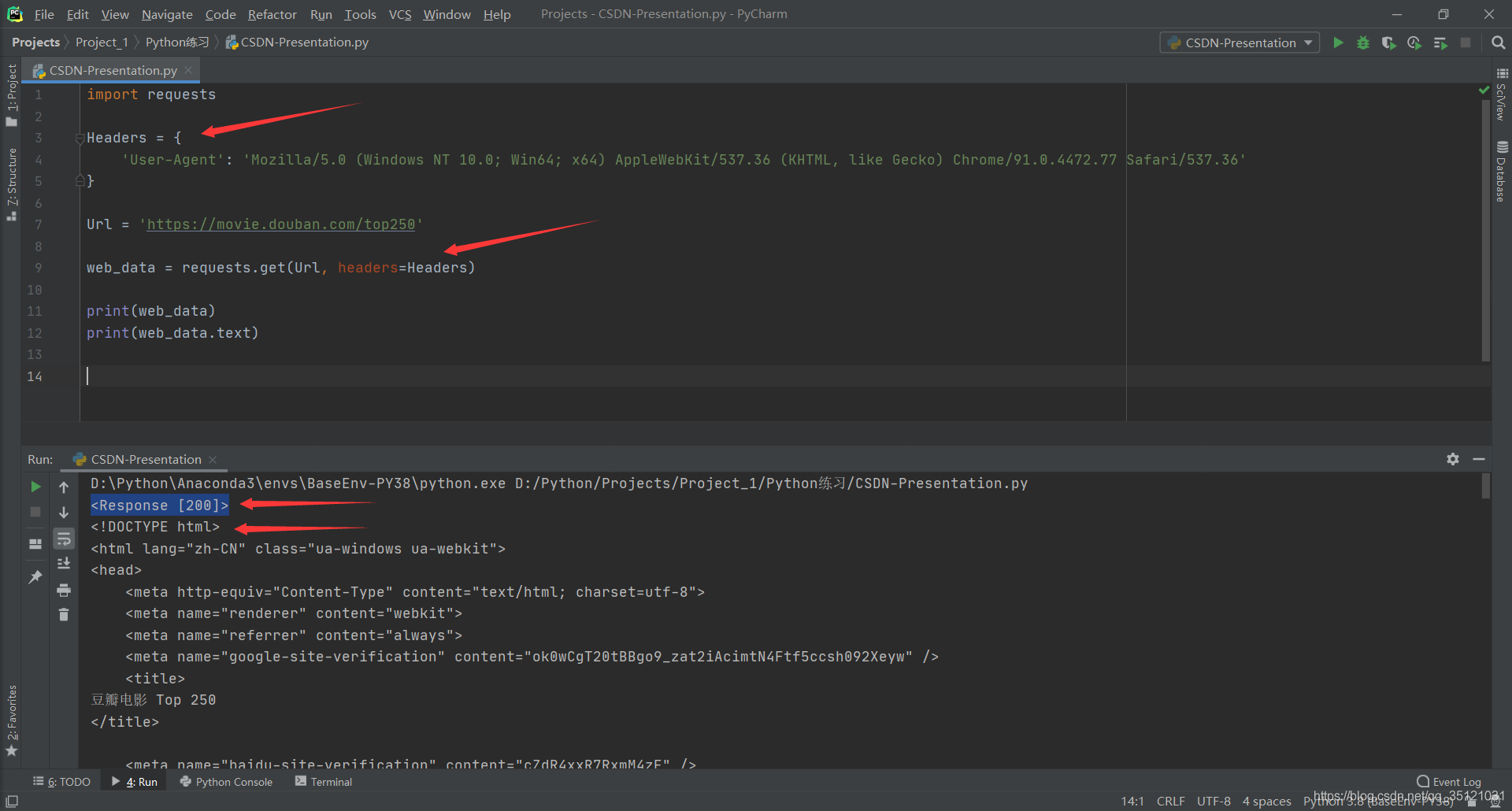
完整代码如下:
import requests
Headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'}
Url='https://movie.douban.com/top250'
web_data= requests.get(Url, headers=Headers)print(web_data)print(web_data.text)4、总结
- Requests库的主要作用是获取网页源代码。由于豆瓣Top250网站并没有设置强反爬措施,我们只需要将浏览器信息放在headers中一并传参即可获取返回数据。在以后可能会遇到需要登录、验证等操作后才能获取数据的网站,如电商平台评论爬取,这就需要更高阶的“ 反 反爬 ”方法,会在后续教程中详解。
- 学如逆水行舟,不进则退!
- (ง •̀-•́)ง