目录
前言
要想看懂instant-ngp的cuda代码,需要先对NeRF系列有足够深入的了解,原始的NeRF版本是基于tensorflow的,今天读的是MIT博士生Yen-Chen Lin实现的pytorch版本的代码。
代码链接:https://github.com/yenchenlin/nerf-pytorch
因为代码量比较大,所以我们先使用一个思维导图对项目逻辑进行梳理,然后逐个文件解析。为了保持思路连贯,我们会一次贴上整个函数的内容并逐行注释,然后贴相关的公式和示意图到代码段的下方。
run_nerf.py
一切都从这个文件开始,让我们先来看看有哪些参数需要设置。
config_parser()
先是一些基本参数
# 生成config.txt文件
parser.add_argument('--config', is_config_file=True,help='config file path')# 指定实验名称
parser.add_argument("--expname",type=str,help='experiment name')# 指定输出目录
parser.add_argument("--basedir",type=str, default='./logs/',help='where to store ckpts and logs')# 指定数据目录
parser.add_argument("--datadir",type=str, default='./data/llff/fern',help='input data directory')然后是一些训练相关的参数
# training options# 设置网络的深度,即网络的层数
parser.add_argument("--netdepth",type=int, default=8,help='layers in network')# 设置网络的宽度,即每一层神经元的个数
parser.add_argument("--netwidth",type=int, default=256,help='channels per layer')
parser.add_argument("--netdepth_fine",type=int, default=8,help='layers in fine network')
parser.add_argument("--netwidth_fine",type=int, default=256,help='channels per layer in fine network')# batch size,光束的数量
parser.add_argument("--N_rand",type=int, default=32*32*4,help='batch size (number of random rays per gradient step)')# 学习率
parser.add_argument("--lrate",type=float, default=5e-4,help='learning rate')# 指数学习率衰减
parser.add_argument("--lrate_decay",type=int, default=250,help='exponential learning rate decay (in 1000 steps)')# 并行处理的光线数量,如果溢出则减少
parser.add_argument("--chunk",type=int, default=1024*32,help='number of rays processed in parallel, decrease if running out of memory')# 并行发送的点数
parser.add_argument("--netchunk",type=int, default=1024*64,help='number of pts sent through network in parallel, decrease if running out of memory')# 一次只能从一张图片中获取随机光线
parser.add_argument("--no_batching", action='store_true',help='only take random rays from 1 image at a time')# 不要从保存的模型中加载权重
parser.add_argument("--no_reload", action='store_true',help='do not reload weights from saved ckpt')# 为粗网络重新加载特定权重
parser.add_argument("--ft_path",type=str, default=None,help='specific weights npy file to reload for coarse network')然后是一些渲染时的参数
# rendering options# 每条射线的粗样本数
parser.add_argument("--N_samples",type=int, default=64,help='number of coarse samples per ray')# 每条射线附加的细样本数
parser.add_argument("--N_importance",type=int, default=0,help='number of additional fine samples per ray')# 抖动
parser.add_argument("--perturb",type=float, default=1.,help='set to 0. for no jitter, 1. for jitter')
parser.add_argument("--use_viewdirs", action='store_true',help='use full 5D input instead of 3D')# 默认位置编码
parser.add_argument("--i_embed",type=int, default=0,help='set 0 for default positional encoding, -1 for none')# 多分辨率
parser.add_argument("--multires",type=int, default=10,help='log2 of max freq for positional encoding (3D location)')# 2D方向的多分辨率
parser.add_argument("--multires_views",type=int, default=4,help='log2 of max freq for positional encoding (2D direction)')# 噪音方差
parser.add_argument("--raw_noise_std",type=float, default=0.,help='std dev of noise added to regularize sigma_a output, 1e0 recommended')# 不要优化,重新加载权重和渲染render_poses路径
parser.add_argument("--render_only", action='store_true',help='do not optimize, reload weights and render out render_poses path')# 渲染测试集而不是render_poses路径
parser.add_argument("--render_test", action='store_true',help='render the test set instead of render_poses path')# 下采样因子以加快渲染速度,设置为 4 或 8 用于快速预览
parser.add_argument("--render_factor",type=int, default=0,help='downsampling factor to speed up rendering, set 4 or 8 for fast preview')还有一些参数
# training options
parser.add_argument("--precrop_iters",type=int, default=0,help='number of steps to train on central crops')
parser.add_argument("--precrop_frac",type=float,
default=.5,help='fraction of img taken for central crops')# dataset options
parser.add_argument("--dataset_type",type=str, default='llff',help='options: llff / blender / deepvoxels')# # 将从测试/验证集中加载 1/N 图像,这对于像 deepvoxels 这样的大型数据集很有用
parser.add_argument("--testskip",type=int, default=8,help='will load 1/N images from test/val sets, useful for large datasets like deepvoxels')## deepvoxels flags
parser.add_argument("--shape",type=str, default='greek',help='options : armchair / cube / greek / vase')## blender flags
parser.add_argument("--white_bkgd", action='store_true',help='set to render synthetic data on a white bkgd (always use for dvoxels)')
parser.add_argument("--half_res", action='store_true',help='load blender synthetic data at 400x400 instead of 800x800')## llff flags# LLFF下采样因子
parser.add_argument("--factor",type=int, default=8,help='downsample factor for LLFF images')
parser.add_argument("--no_ndc", action='store_true',help='do not use normalized device coordinates (set for non-forward facing scenes)')
parser.add_argument("--lindisp", action='store_true',help='sampling linearly in disparity rather than depth')
parser.add_argument("--spherify", action='store_true',help='set for spherical 360 scenes')
parser.add_argument("--llffhold",type=int, default=8,help='will take every 1/N images as LLFF test set, paper uses 8')# logging/saving options
parser.add_argument("--i_print",type=int, default=100,help='frequency of console printout and metric loggin')
parser.add_argument("--i_img",type=int, default=500,help='frequency of tensorboard image logging')
parser.add_argument("--i_weights",type=int, default=10000,help='frequency of weight ckpt saving')
parser.add_argument("--i_testset",type=int, default=50000,help='frequency of testset saving')
parser.add_argument("--i_video",type=int, default=50000,help='frequency of render_poses video saving')train()
训练过程的控制。开始训练,先把5D输入进行编码,然后交给MLP得到4D的数据(颜色和体素的密度),然后进行体渲染得到图片,再和真值计算L2 loss。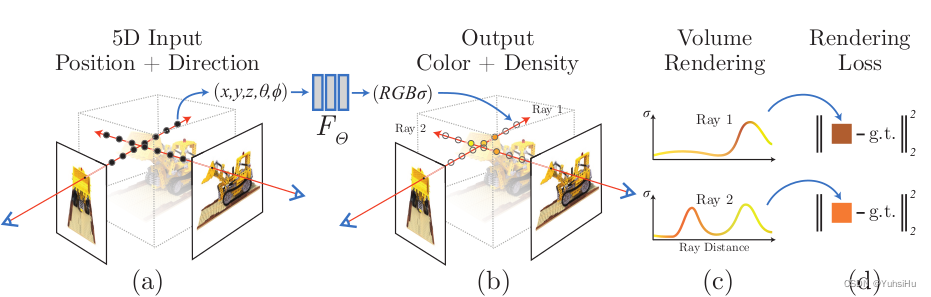
deftrain():
parser= config_parser()
args= parser.parse_args()# Load data
K=Noneif args.dataset_type=='llff':# shape: images[20,378,504,3] poses[20,3,5] render_poses[120,3,5]
images, poses, bds, render_poses, i_test= load_llff_data(args.datadir, args.factor,
recenter=True, bd_factor=.75,
spherify=args.spherify)# hwf=[378,504,focal] poses每个batch的每一行最后一个元素拿出来
hwf= poses[0,:3,-1]# shape: poses [20,3,4] hwf给出去之后把每一行的第5个元素删掉
poses= poses[:,:3,:4]print('Loaded llff', images.shape, render_poses.shape, hwf, args.datadir)ifnotisinstance(i_test,list):
i_test=[i_test]if args.llffhold>0:print('Auto LLFF holdout,', args.llffhold)
i_test= np.arange(images.shape[0])[::args.llffhold]# 验证集和测试集相同
i_val= i_test# 剩下的部分当作训练集
i_train= np.array([ifor iin np.arange(int(images.shape[0]))if(inotin i_testand inotin i_val)])print('DEFINING BOUNDS')# 定义边界值if args.no_ndc:
near= np.ndarray.min(bds)*.9
far= np.ndarray.max(bds)*1.else:# 没说就是0-1
near=0.
far=1.print('NEAR FAR', near, far)elif args.dataset_type=='blender':
images, poses, render_poses, hwf, i_split= load_blender_data(args.datadir, args.half_res, args.testskip)print('Loaded blender', images.shape, render_poses.shape, hwf, args.datadir)
i_train, i_val, i_test= i_split
near=2.
far=6.if args.white_bkgd:
images= images[...,:3]*images[...,-1:]+(1.-images[...,-1:])else:
images= images[...,:3]elif args.dataset_type=='LINEMOD':
images, poses, render_poses, hwf, K, i_split, near, far= load_LINEMOD_data(args.datadir, args.half_res, args.testskip)print(f'Loaded LINEMOD, images shape:{images.shape}, hwf:{hwf}, K:{K}')print(f'[CHECK HERE] near:{near}, far:{far}.')
i_train, i_val, i_test= i_splitif args.white_bkgd:
images= images[...,:3]*images[...,-1:]+(1.-images[...,-1:])else:
images= images[...,:3]elif args.dataset_type=='deepvoxels':
images, poses, render_poses, hwf, i_split= load_dv_data(scene=args.shape,
basedir=args.datadir,
testskip=args.testskip)print('Loaded deepvoxels', images.shape, render_poses.shape, hwf, args.datadir)
i_train, i_val, i_test= i_split
hemi_R= np.mean(np.linalg.norm(poses[:,:3,-1], axis=-1))
near= hemi_R-1.
far= hemi_R+1.else:print('Unknown dataset type', args.dataset_type,'exiting')return# Cast intrinsics to right types
H, W, focal= hwf
H, W=int(H),int(W)
hwf=[H, W, focal]if KisNone:
K= np.array([[focal,0,0.5*W],[0, focal,0.5*H],[0,0,1]])if args.render_test:
render_poses= np.array(poses[i_test])# Create log dir and copy the config file
basedir= args.basedir
expname= args.expname
os.makedirs(os.path.join(basedir, expname), exist_ok=True)
f= os.path.join(basedir, expname,'args.txt')withopen(f,'w')asfile:# 把参数统一放到./logs/expname/args.txtfor arginsorted(vars(args)):
attr=getattr(args, arg)file.write('{} = {}\n'.format(arg, attr))if args.configisnotNone:
f= os.path.join(basedir, expname,'config.txt')withopen(f,'w')asfile:file.write(open(args.config,'r').read())# Create nerf model# 创建模型
render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer= create_nerf(args)
global_step= start
bds_dict={'near': near,'far': far,}# 本来都是dict类型,都有9个元素,加了bds之后就是11个元素了
render_kwargs_train.update(bds_dict)
render_kwargs_test.update(bds_dict)# Move testing data to GPU
render_poses= torch.Tensor(render_poses).to(device)# Short circuit if only rendering out from trained model# 只渲染并生成视频if args.render_only:print('RENDER ONLY')with torch.no_grad():if args.render_test:# render_test switches to test poses
images= images[i_test]else:# Default is smoother render_poses path
images=None
testsavedir= os.path.join(basedir, expname,'renderonly_{}_{:06d}'.format('test'if args.render_testelse'path', start))
os.makedirs(testsavedir, exist_ok=True)print('test poses shape', render_poses.shape)
rgbs, _= render_path(render_poses, hwf, K, args