Pytorch教程目录
Torch and Numpy
变量 (Variable)
激励函数
关系拟合(回归)
区分类型 (分类)
快速搭建法
批训练
加速神经网络训练
Optimizer优化器
卷积神经网络 CNN
卷积神经网络(RNN、LSTM)
RNN 循环神经网络 (分类)
RNN 循环神经网络 (回归)
自编码 (Autoencoder)
DQN 强化学习
生成对抗网络 (GAN)
为什么 Torch 是动态的
GPU 加速运算
过拟合 (Overfitting)
批标准化 (Batch Normalization)
什么是过拟合 (Overfitting)
过于自负
在细说之前, 我们先用实际生活中的一个例子来比喻一下过拟合现象. 说白了, 就是机器学习模型于自信. 已经到了自负的阶段了. 那自负的坏处, 大家也知道, 就是在自己的小圈子里表现非凡, 不过在现实的大圈子里却往往处处碰壁. 所以在这个简介里, 我们把自负和过拟合画上等号.
回归分类的过拟合

机器学习模型的自负又表现在哪些方面呢. 这里是一些数据. 如果要你画一条线来描述这些数据, 大多数人都会按照蓝线这么画. 对, 这条线也是我们希望机器也能学出来的一条用来总结这些数据的线. 这时蓝线与数据的总误差可能是10.
可是有时候, 机器过于纠结这误差值, 他想把误差减到更小, 来完成他对这一批数据的学习使命. 所以, 他学到的可能会变成这样 . 它几乎经过了每一个数据点, 这样, 误差值会更小 . 可是误差越小就真的好吗? 看来我们的模型还是太天真了. 当我拿这个模型运用在现实中的时候, 他的自负就体现出来. 小二, 来一打现实数据 . 这时, 之前误差大的蓝线误差基本保持不变 .误差小的 红线误差值突然飙高 , 自负的红线再也骄傲不起来, 因为他不能成功的表达除了训练数据以外的其他数据. 这就叫做过拟合. Overfitting.
那么在分类问题当中. 过拟合的分割线可能是这样, 小二, 再上一打数据 . 我们明显看出, 有两个黄色的数据并没有被很好的分隔开来. 这也是过拟合在作怪.好了, 既然我们时不时会遇到过拟合问题, 那解决的方法有那些呢.
解决方法
方法一: 增加数据量, 大部分过拟合产生的原因是因为数据量太少了. 如果我们有成千上万的数据, 红线也会慢慢被拉直, 变得没那么扭曲 .

方法二: 运用
正规化.L1,L2 regularization等等, 这些方法适用于大多数的机器学习, 包括神经网络. 他们的做法大同小异, 我们简化机器学习的关键公式为y=Wx.W为机器需要学习到的各种参数. 在过拟合中,W的值往往变化得特别大或特别小. 为了不让W变化太大, 我们在计算误差上做些手脚.
原始的cost 误差是这样计算,cost = 预测值-真实值的平方. 如果W变得太大, 我们就让cost也跟着变大, 变成一种惩罚机制. 所以我们把W自己考虑进来. 这里 abs 是绝对值. 这一种形式的 正规化, 叫做L1 正规化.L2 正规化和 l1 类似, 只是绝对值换成了平方. 其他的l3, l4 也都是换成了立方和4次方等等. 形式类似.
用这些方法,我们就能保证让学出来的线条不会过于扭曲.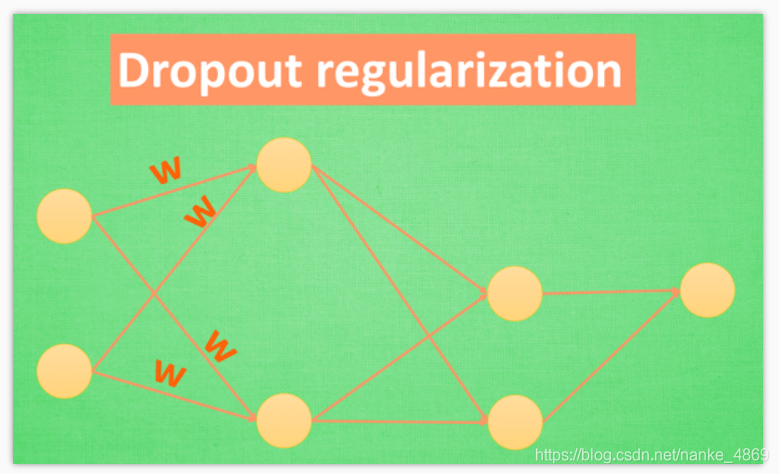
方法三:还有一种专门用在神经网络的正规化的方法, 叫作
dropout. 在训练的时候, 我们随机忽略掉一些神经元和神经联结 , 是这个神经网络变得”不完整”. 用一个不完整的神经网络训练一次.
到第二次再随机忽略另一些, 变成另一个不完整的神经网络. 有了这些随机 drop 掉的规则, 我们可以想象其实每次训练的时候, 我们都让每一次预测结果都不会依赖于其中某部分特定的神经元. 像l1, l2正规化一样, 过度依赖的 W , 也就是训练参数的数值会很大, l1, l2会惩罚这些大的 参数.Dropout 的做法是从根本上让神经网络没机会过度依赖.
Dropout 缓解过拟合
做点数据
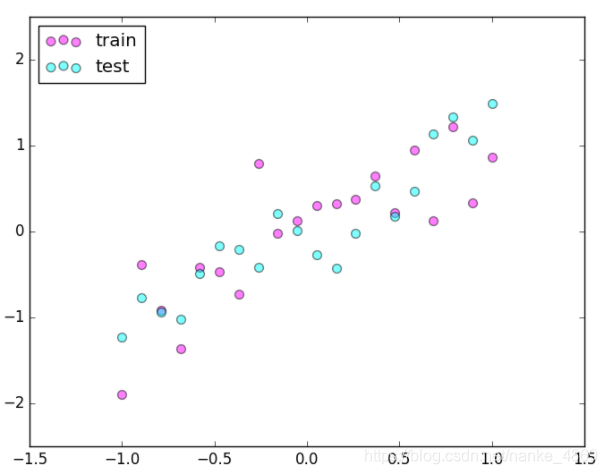
自己做一些伪数据, 用来模拟真实情况. 数据少, 才能凸显过拟合问题, 所以我们就做10个数据点.
import torchimport matplotlib.pyplotas plt
torch.manual_seed(1)# reproducible
N_SAMPLES=20
N_HIDDEN=300# training data
x= torch.unsqueeze(torch.linspace(-1,1, N_SAMPLES),1)
y= x+0.3*torch.normal(torch.zeros(N_SAMPLES,1), torch.ones(N_SAMPLES,1))# test data
test_x= torch.unsqueeze(torch.linspace(-1,1, N_SAMPLES),1)
test_y= test_x+0.3*torch.normal(torch.zeros(N_SAMPLES,1), torch.ones(N_SAMPLES,1))# show data
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test')
plt.legend(loc='upper left')
plt.ylim((-2.5,2.5))
plt.show()搭建神经网络
我们在这里搭建两个神经网络, 一个没有dropout, 一个有dropout. 没有dropout 的容易出现 过拟合, 那我们就命名为net_overfitting, 另一个就是net_dropped.torch.nn.Dropout(0.5) 这里的0.5 指的是随机有50% 的神经元会被关闭/丢弃.
net_overfitting= torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN,1),)
net_dropped= torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.Dropout(0.5),# drop 50% of the neuron
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.Dropout(0.5),# drop 50% of the neuron
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN,1),)训练
训练的时候, 这两个神经网络分开训练. 训练的环境都一样.
optimizer_ofit = torch.optim.Adam(net_overfitting.parameters(), lr=0.01)
optimizer_drop = torch.optim.Adam(net_dropped.parameters(), lr=0.01)
loss_func = torch.nn.MSELoss()
for t in range(500):
pred_ofit = net_overfitting(x)
pred_drop = net_dropped(x)
loss_ofit = loss_func(pred_ofit, y)
loss_drop = loss_func(pred_drop, y)
optimizer_ofit.zero_grad()
optimizer_drop.zero_grad()
loss_ofit.backward()
loss_drop.backward()
optimizer_ofit.step()
optimizer_drop.step()对比测试结果
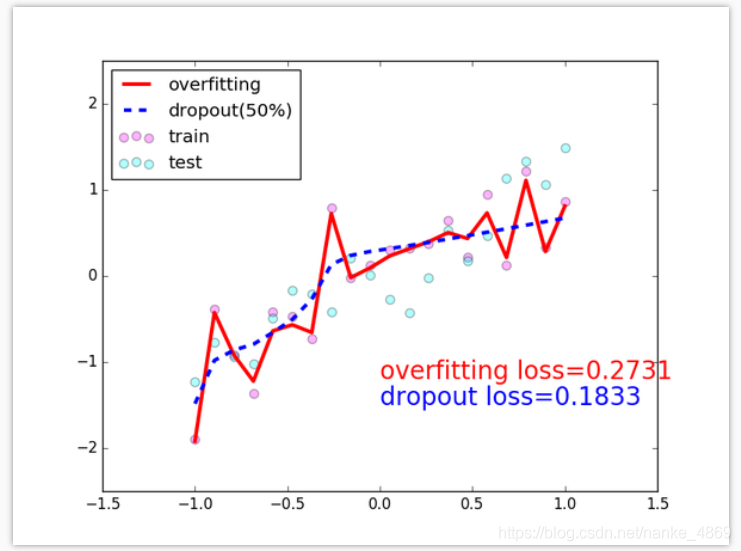
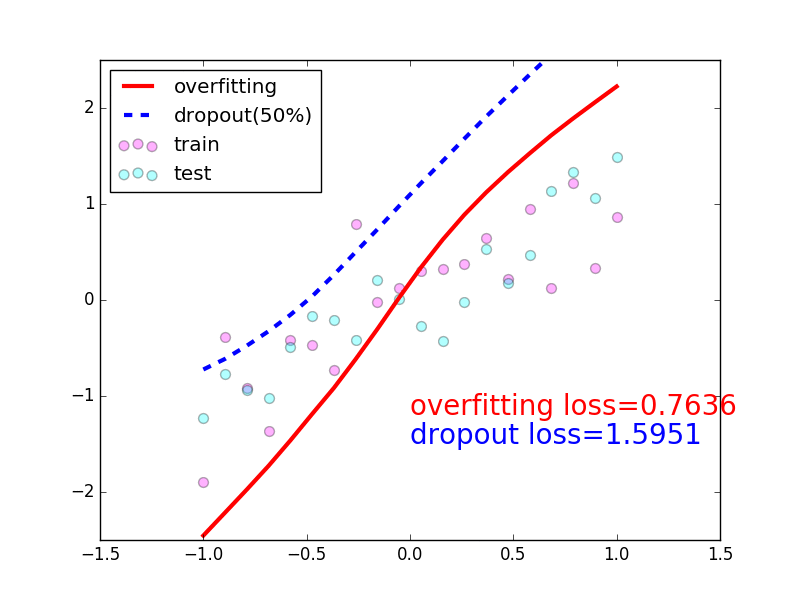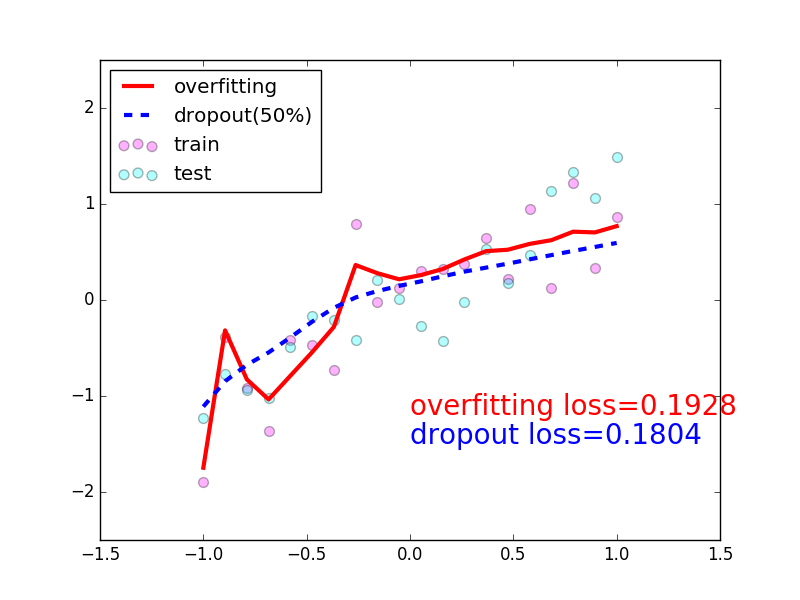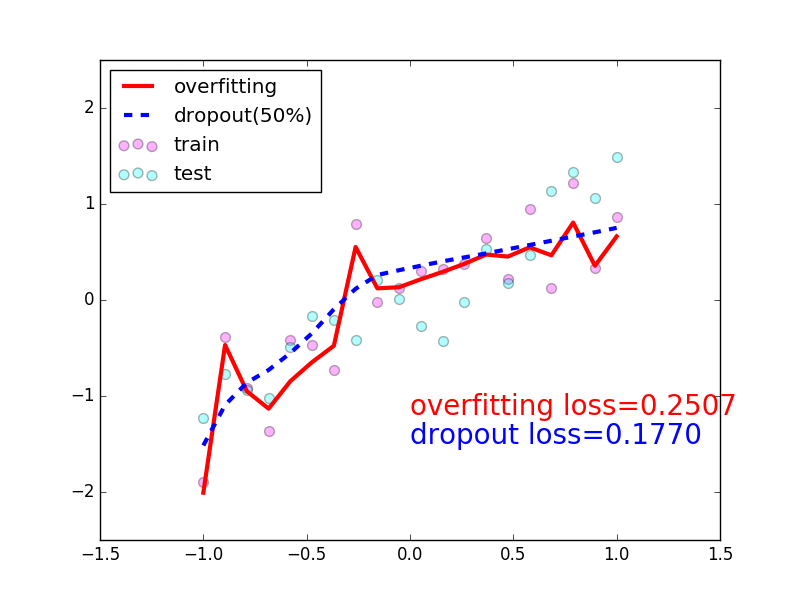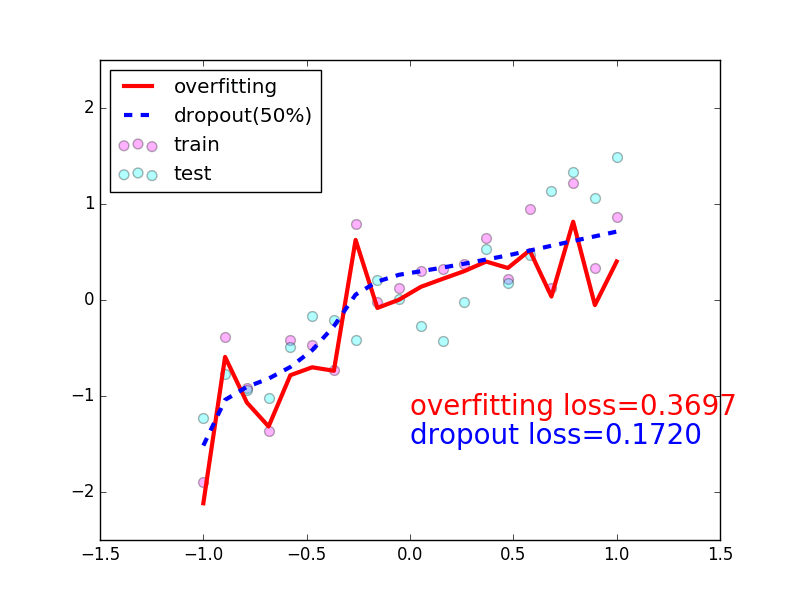
在这个for 循环里, 我们加上画测试图的部分. 注意在测试时, 要将网络改成eval()形式, 特别是net_dropped,net_overfitting 改不改其实无所谓. 画好图再改回train() 模式.
plt.ion()# something about plotting...
optimizer_ofit.step()
optimizer_drop.step()# 接着上面来if t%10==0:# 每 10 步画一次图# 将神经网络转换成测试形式, 画好图之后改回 训练形式
net_overfitting.eval()
net_dropped.eval()# 因为 drop 网络在 train 的时候和 test 的时候参数不一样.# plotting
plt.cla()
test_pred_ofit= net_overfitting(test_x)
test_pred_drop= net_dropped(test_x)
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.3, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.3, label='test')
plt.plot(test_x.data.numpy(), test_pred_ofit.data.numpy(),'r-', lw=3, label='overfitting')
plt.plot(test_x.data.numpy(), test_pred_drop.data.numpy(),'b--', lw=3, label='dropout(50%)')
plt.text(0,-1.2,'overfitting loss=%.4f'% loss_func(test_pred_ofit, test_y).data.numpy(), fontdict={'size':20,'color':'red'})
plt.text(0,-1.5,'dropout loss=%.4f'% loss_func(test_pred_drop, test_y).data.numpy(), fontdict={'size':20,'color':'blue'})
plt.legend(loc='upper left'); plt.ylim((-2.5,2.5));plt.pause(0.1)# 将两个网络改回 训练形式
net_overfitting.train()
net_dropped.train()
plt.ioff()
plt.show()全部代码
import torchimport matplotlib.pyplotas plt# torch.manual_seed(1) # reproducible
N_SAMPLES=20
N_HIDDEN=300# training data
x= torch.unsqueeze(torch.linspace(-1,1, N_SAMPLES),1)
y= x+0.3*torch.normal(torch.zeros(N_SAMPLES,1), torch.ones(N_SAMPLES,1))# test data
test_x= torch.unsqueeze(torch.linspace(-1,1, N_SAMPLES),1)
test_y= test_x+0.3*torch.normal(torch.zeros(N_SAMPLES,1), torch.ones(N_SAMPLES,1))# show data
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test')
plt.legend(loc='upper left')
plt.ylim((-2.5,2.5))
plt.show()
net_overfitting= torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN,1),)
net_dropped= torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.Dropout(0.5),# drop 50% of the neuron
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.Dropout(0.5),# drop 50% of the neuron
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN,1),)print(net_overfitting)# net architectureprint(net_dropped)
optimizer_ofit= torch.optim.Adam(net_overfitting.parameters(), lr=0.01)
optimizer_drop= torch.optim.Adam(net_dropped.parameters(), lr=0.01)
loss_func= torch.nn.MSELoss()
plt.ion()# something about plottingfor tinrange(500):
pred_ofit= net_overfitting(x)
pred_drop= net_dropped(x)
loss_ofit= loss_func(pred_ofit, y)
loss_drop= loss_func(pred_drop, y)
optimizer_ofit.zero_grad()
optimizer_drop.zero_grad()
loss_ofit.backward()
loss_drop.backward()
optimizer_ofit.step()
optimizer_drop.step()if t%10==0:# change to eval mode in order to fix drop out effect
net_overfitting.eval()
net_dropped.eval()# parameters for dropout differ from train mode# plotting
plt.cla()
test_pred_ofit= net_overfitting(test_x)
test_pred_drop= net_dropped(test_x)
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.3, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.3, label='test')
plt.plot(test_x.data.numpy(), test_pred_ofit.data.numpy(),'r-', lw=3, label='overfitting')
plt.plot(test_x.data.numpy(), test_pred_drop.data.numpy(),'b--', lw=3, label='dropout(50%)')
plt.text(0,-1.2,'overfitting loss=%.4f'% loss_func(test_pred_ofit, test_y).data.numpy(), fontdict={'size':20,'color':'red'})
plt.text(0,-1.5,'dropout loss=%.4f'% loss_func(test_pred_drop, test_y).data.numpy(), fontdict={'size':20,'color':'blue'})
plt.legend(loc='upper left'); plt.ylim((-2.5,2.5));plt.pause(0.1)# change back to train mode
net_overfitting.train()
net_dropped.train()
plt.ioff()
plt.show()