mybatis 源码
1.MyBatis 源码概述
1.1 源码架构分析
MyBatis 源码共 16 个模块,可以分成三层,如下图:
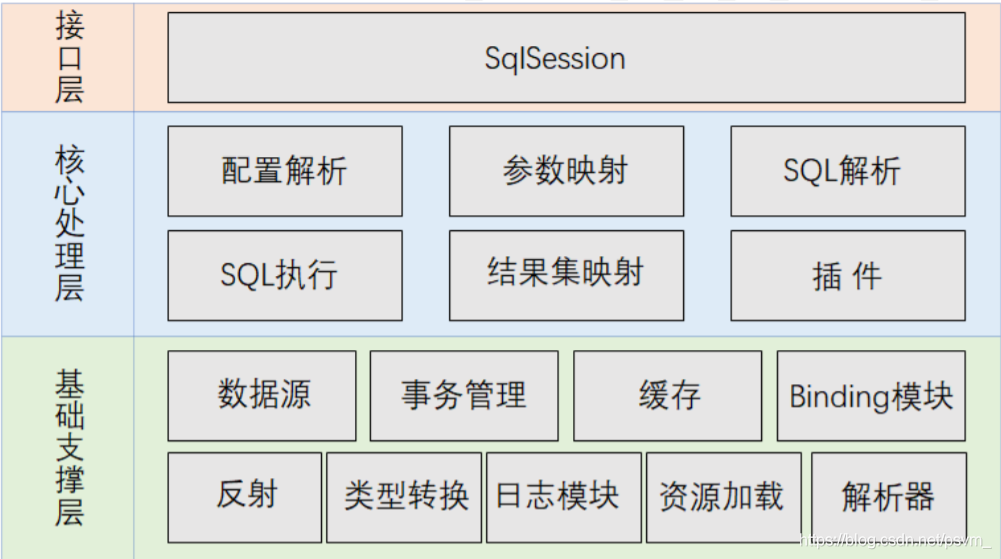
基础支撑层:技术组件专注于底层技术实现,通用性较强无业务含义;
核心处理层:业务组件专注 MyBatis 的业务流程实现,依赖于基础支撑层;
接口层:MyBatis 对外提供的访问接口,面向 SqlSession 编程;
思考题:系统为什么要分层?
- 代码和系统的可维护性更高。系统分层之后,每个层次都有自己的定位,每个层次内部 MyBatis源码结构.xmind 的组件都有自己的分工,系统就会变得很清晰,维护起来非常明确;
- 方便开发团队分工和开发效率的提升;举个例子,mybatis 这么大的一个源码框架不可 能是一个人开发的,他需要一个团队,团队之间肯定有分工,既然有了层次的划分,分 工也会变得容易,开发人员可以专注于某一层的某一个模块的实现,专注力提升了,开 发效率自然也会提升;
- 提高系统的伸缩性和性能。系统分层之后,我们只要把层次之间的调用接口明确了,那 我们就可以从逻辑上的分层变成物理上的分层。当系统并发量吞吐量上来了,怎么办? 为了提高系统伸缩性和性能,我们可以把不同的层部署在不同服务器集群上,不同的组 件放在不同的机器上,用多台机器去抗压力,这就提高了系统的性能。压力大的时候扩 展节点加机器,压力小的时候,压缩节点减机器,系统的伸缩性就是这么来的;
1.2 外观模式(门面模式)
从源码的架构分析,特别是接口层的设计,可以看出来MyBatis的整体架构符合门面模式的。 门面模式定义:提供了一个统一的接口,用来访问子系统中的一群接口。外观模式定义了一 个高层接口,让子系统更容易使用。类图如下:
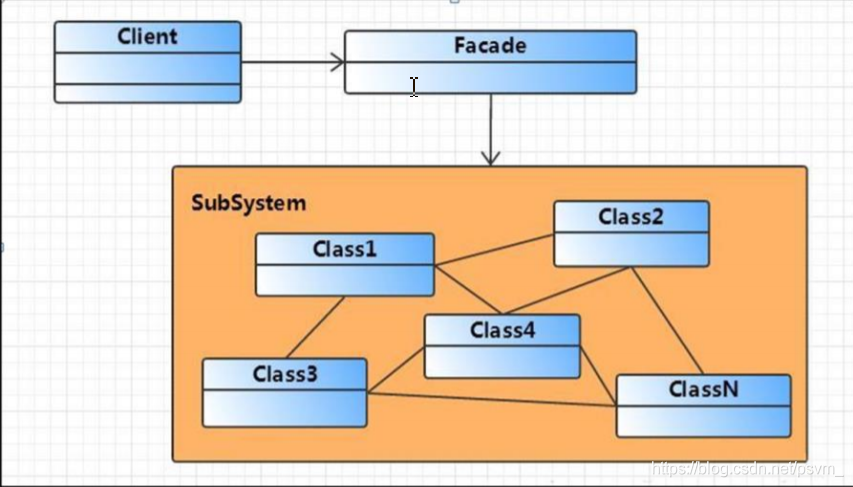
Facade 角色:提供一个外 观接口,对外,它提供一 个易于客户端访问的接 口,对内,它可以访问子 系统中的所有功能。
SubSystem(子系统)角 色:子系统在整个系统中 可以是一个或多个模块, 每个模块都有若干类组 成,这些类可能相互之间 有着比较复杂的关系。
门面模式优点:使复杂子系统的接口变的简单可用,减少了客户端对子系统的依赖,达到了 解耦的效果;遵循了 OO 原则中的迪米特法则,对内封装具体细节,对外只暴露必要的接口。
门面模式使用场景:
1.一个复杂的模块或子系统提供一个供外界访问的接口
2.子系统相对独立 ― 外界对子系统的访问只要黑箱操作即可
1.3 面向对象设计需要遵循的六大设计原则
学习源码的目的除了学习编程的技巧、经验之外,最重要的是学习源码的设计的思想以 及设计模式的灵活应用,因此在学习源码之前有必要对面向对象设计的几个原则先深入 的去了解,让自己具备良好的设计思想和理念;
- 单一职责原则:一个类或者一个接口只负责唯一项职责,尽量设计出功能单一的接 口;
- 依赖倒转原则:高层模块不应该依赖低层模块具体实现,解耦高层与低层。既面向 接口编程,当实现发生变化时,只需提供新的实现类,不需要修改高层模块代码;
- 开放-封闭原则:程序对外扩展开放,对修改关闭;换句话说,当需求发生变化时, 我们可以通过添加新模块来满足新需求,而不是通过修改原来的实现代码来满足新 需求;
- 迪米特法则:一个对象应该对其他对象保持最少的了解,尽量降低类与类之间的耦 合度;实现这个原则,要注意两个点,一方面在做类结构设计的时候尽量降低成员 的访问权限,能用 private 的尽量用 private;另外在类之间,如果没有必要直接调 用,就不要有依赖关系;这个法则强调的还是类之间的松耦合;
- 里氏代换原则:所有引用基类(父类)的地方必须能透明地使用其子类的对象;
- 接口隔离原则:客户端不应该依赖它不需要的接口,一个类对另一个类的依赖应该 建立在最小的接口上;
2. 日志模块分析
2.1 日志模块需求分析
- MyBatis 没有提供日志的实现类,需要接入第三方的日志组件,但第三方日志组件都有 各自的 Log 级别,且各不相同,而 MyBatis 统一提供了 trace、debug、warn、error 四个 级别;
- 自动扫描日志实现,并且第三方日志插件加载优先级如下:slf4J → commonsLoging → Log4J2 → Log4J → JdkLog;
- 日志的使用要优雅的嵌入到主体功能中;
2.2 适配器模式
日志模块的第一个需求是一个典型的使用适配器模式的场景,适配器模式(Adapter Pattern) 是作为两个不兼容的接口之间的桥梁,将一个类的接口转换成客户希望的另外一个接口。
适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作;类图如下: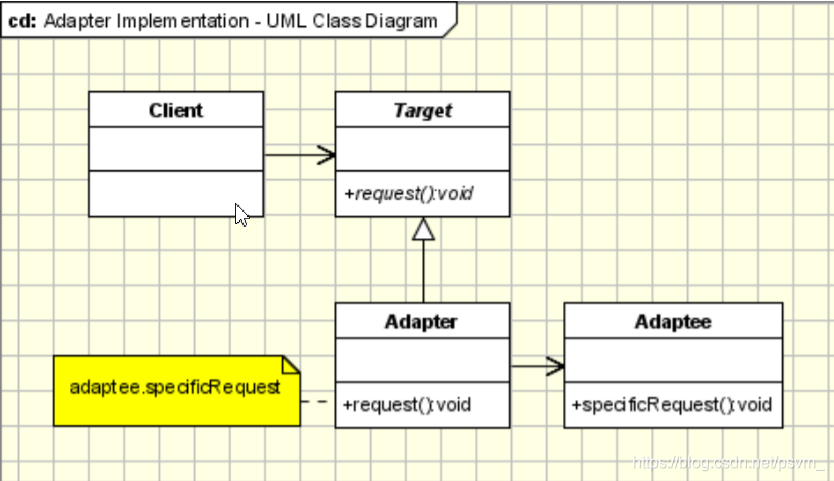
Target:目标角色,期待 得到的接口.
Adaptee:适配者角色, 被适配的接口.
Adapter:适配器角色, 将源接口转换成目标接口.
适用场景:
当调用双方都不太容易修改的时候,为了复用现有组件可以使用适配器模式;
在系统中接入第三方组件的时候经常被使用到;
**注意:**如果系统中存在过多的适配器,会增加 系统的复杂性,设计人员应考虑对系统进行重构;
MyBatis 日志模块是怎么使用适配器模式?实现如下:
Target:目标角色,期待得到的接口。org.apache.ibatis.logging.Log 接口,对内提供了统一 的日志接口;
Adaptee:适配者角色,被适配的接口。其他日志组件组件如 slf4J 、commonsLoging 、 Log4J2 等被包含在适配器中。
Adapter:适配器角色,将源接口转换成目标接口。针对每个日志组件都提供了适配器, 每 个 适 配 器 都 对 特 定 的 日 志 组 件 进 行 封 装 和 转 换 ; 如 Slf4jLoggerImpl 、JakartaCommonsLoggingImpl 等;
日志模块适配器结构类图: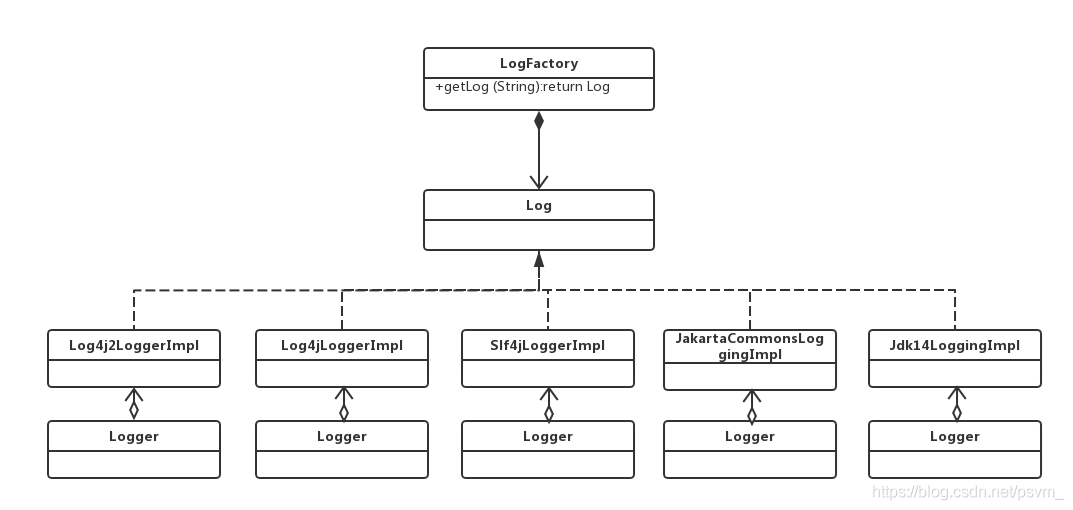
总结:
日志模块实现采用适配器模式,日志组件(Target)、适配器以及统一接口(Log 接口) 定义清晰明确符合单一职责原则;同时,客户端在使用日志时,面向 Log 接口编程,不需要 关心底层日志模块的实现,符合依赖倒转原则;最为重要的是,如果需要加入其他第三方日 志框架,只需要扩展新的模块满足新需求,而不需要修改原有代码,这又符合了开闭原则;
2.3 怎么实现优先加载日志组件?
见 org.apache.ibatis.logging.LogFactory 中的静态代码块,通过静态代码块确保第三方日志插 件加载优先级如下:slf4J → commonsLoging → Log4J2 → Log4J → JdkLog;
publicfinalclassLogFactory{publicstaticfinalString MARKER="MYBATIS";//被选定的第三方日志组件适配器的构造方法privatestaticConstructor<?extendsLog> logConstructor;//自动扫描日志实现,并且第三方日志插件加载优先级如下:slf4J → commonsLoging → Log4J2 → Log4J → JdkLogstatic{tryImplementation(LogFactory::useSlf4jLogging);tryImplementation(LogFactory::useCommonsLogging);tryImplementation(LogFactory::useLog4J2Logging);tryImplementation(LogFactory::useLog4JLogging);tryImplementation(LogFactory::useJdkLogging);tryImplementation(LogFactory::useNoLogging);}privateLogFactory(){// disable construction}2.4 代理模式和动态代理
**代理模式定义:**给目标对象提供一个代理对象,并由代理对象控制对目标对象的引用;
目的:
(1)通过引入代理对象的方式来间接访问目标对象,防止直接访问目标对象给系统带来的 不必要复杂性;
(2)通过代理对象对原有的业务增强;
代理模式类图: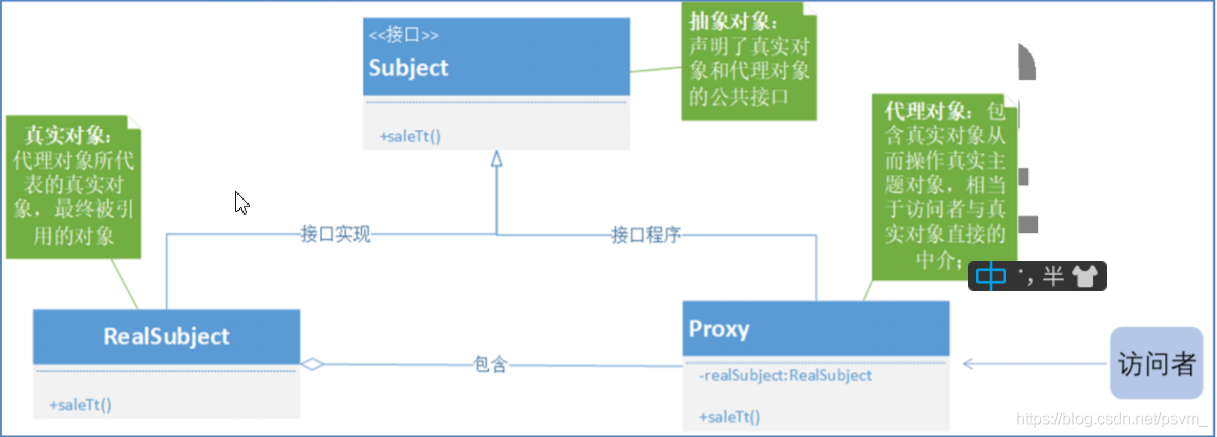
代理模式有静态代理和动态代理两种实现方式。
2.4.1 静态代理
这种代理方式需要代理对象和目标对象实现一样的接口。
**优点:**可以在不修改目标对象的前提下扩展目标对象的功能。
缺点:
冗余。由于代理对象要实现与目标对象一致的接口,会产生过多的代理类。
不易维护。一旦接口增加方法,目标对象与代理对象都要进行修改。
2.4.2 动态代理
动态代理利用了 JDK API,动态地在内存中构建代理对象,从而实现对目标对象的代理功能。
动态代理又被称为 JDK 代理或接口代理。静态代理与动态代理的区别主要在:
- 静态代理在编译时就已经实现,编译完成后代理类是一个实际的 class 文件
- 动态代理是在运行时动态生成的,即编译完成后没有实际的 class 文件,而是在运行时 动态生成类字节码,并加载到 JVM 中
**注意:**动态代理对象不需要实现接口,但是要求目标对象必须实现接口,否则不能使用动态 代理。
JDK 中生成代理对象主要涉及两个类,第一个类为 java.lang.reflect.Proxy,通过静态方法 newProxyInstance 生成代理对象,第二个为 java.lang.reflect.InvocationHandler 接口,通过 invoke 方法对业务进行增强;
2.5 优雅的增强日志功能
首先搞清楚那些地方需要打印日志?通过对日志的观察,如下几个位置需要打日志:
在创建 prepareStatement 时,打印执行的 SQL 语句;
访问数据库时,打印参数的类型和值
查询出结构后,打印结果数据条数 因此在日志模块中有 BaseJdbcLogger、ConnectionLogger、PreparedStatementLogger 和 ResultSetLogge 通过动态代理负责在不同的位置打印日志;
几个相关类的类图如下: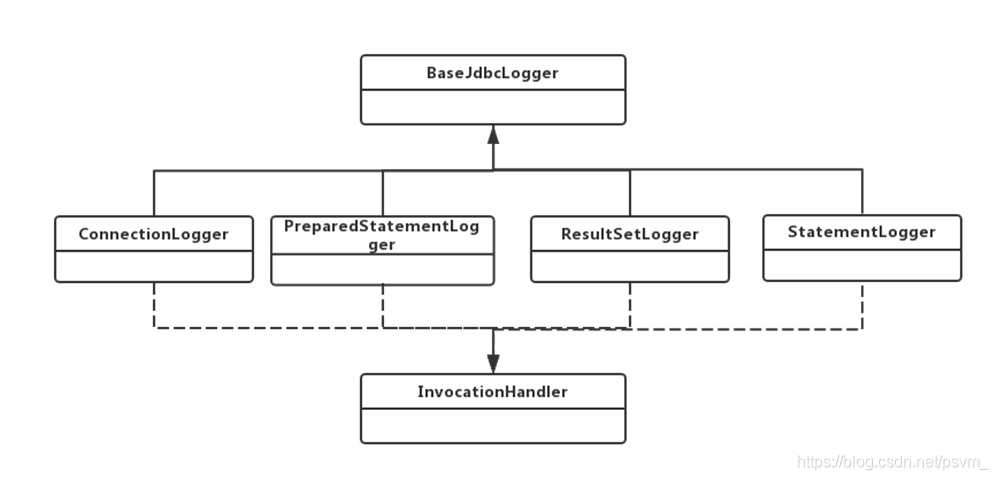
BaseJdbcLogger:所有日志增强的抽象基类,用于记录 JDBC 那些方法需要增强,保存运 行期间 sql 参数信息;
ConnectionLogger:负责打印连接信息和 SQL 语句。通过动态代理,对 connection 进行 增强,如果是调用 prepareStatement、prepareCall、createStatement 的方法,打印要执 行的 sql 语句并返回 prepareStatement 的代理对象(PreparedStatementLogger),让prepareStatement 也具备日志能力,打印参数;
PreparedStatementLogger:对 prepareStatement 对象增强,增强的点如下:
增强 PreparedStatement 的 setxxx 方法将参数设置到 columnMap、columnNames、 columnValues,为打印参数做好准备;
增强 PreparedStatement 的 execute 相关方法,当方法执行时,通过动态代理打印 参数,返回动态代理能力的 resultSet;
如果是查询,增强 PreparedStatement 的 getResultSet 方法,返回动态代理能力的 resultSet;如果是更新,直接打印影响的行数
ResultSetLogger:负责打印数据结果信息;
最后一个问题:
上面讲这么多,都是日志功能的实现,那日志功能是怎么加入主体功能的?
**答:**既然在 Mybatis 中 Executor 才是访问数据库的组件,日志功能是在 Executor 中被嵌入的, 具体代码在
org.apache.ibatis.executor.SimpleExecutor.prepareStatement(StatementHandler, Log)
方法中,如下所示:
//创建StatementprivateStatementprepareStatement(StatementHandler handler,Log statementLog)throwsSQLException{Statement stmt;//获取connection对象的动态代理,添加日志能力;Connection connection=getConnection(statementLog);//通过不同的StatementHandler,利用connection创建(prepare)Statement
stmt= handler.prepare(connection, transaction.getTimeout());//使用parameterHandler处理占位符
handler.parameterize(stmt);return stmt;}3. 数据源模块分析
数据源模块重点讲解数据源的创建和数据库连接池的源码分析;数据源创建比较负责,对于 复杂对象的创建,可以考虑使用工厂模式来优化,接下来介绍下简单工厂模式和工厂模式;
3.1 简单工厂模式
简单工厂属于类的创建型设计模式,通过专门定义一个类来负责创建其它类的实例,被创建的 实例通常都具有共同的父类。类图如下:
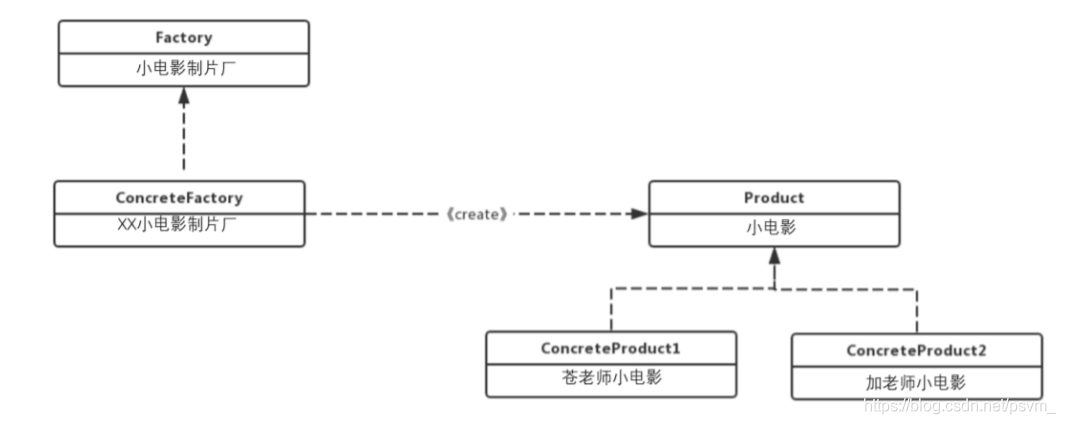
产品接口(Product):产品接口用于定义产品类的功能,具体工厂类产生的所有产品都必须实现这个接口。调用者与产品接口直接交互,这是调用者最关心的接口;
具体产品类(ConcreteProduct):实现产品接口的实现类,具体产品类中定义了具体的业务逻辑;
工厂接口(Factory):工厂接口是工厂方法模式的核心接口,调用者会直接和工厂接口交互用于获取具体的产品实现类;
具体工厂类(ConcreteFactory):是工厂接口的实现类,用于实例化产品对象,不同的具体工厂类会根据需求实例化不同的产品实现类;
为什么要使用工厂模式?
答:对象可以通过 new 关键字、反射、clone 等方式创建,也可以通过工厂模式创建。对于 复杂对象,使用 new 关键字、反射、clone 等方式创建存在如下缺点:
对象创建和对象使用的职责耦合在一起,违反单一原则;
当业务扩展时,必须修改代业务代码,违反了开闭原则; 而使用工厂模式将对象的创建和使用进行解耦,并屏蔽了创建对象可能的复杂过程,相对简 单工厂模式,又具备更好的扩展性和可维护性,优点具体如下:
把对象的创建和使用的过程分开,对象创建和对象使用使用的职责解耦; 如果创建对象的过程很复杂,创建过程统一到工厂里管理,既减少了重复代码,也方便 以后对创建过程的修改维护;
当业务扩展时,只需要增加工厂子类,符合开闭原则;
3.3 数据源的创建
数据源对象是比较复杂的对象,其创建过程相对比较复杂,对于 MyBatis 创建一个数据源, 具体来讲有如下难点:
- 常见的数据源组件都实现了 javax.sql.DataSource 接口;
- MyBatis 不但要能集成第三方的数据源组件,自身也提供了数据源的实现;
- 一般情况下,数据源的初始化过程参数较多,比较复杂; 综上所述,数据源的创建是一个典型使用工厂模式的场景,实现类图如下所示:
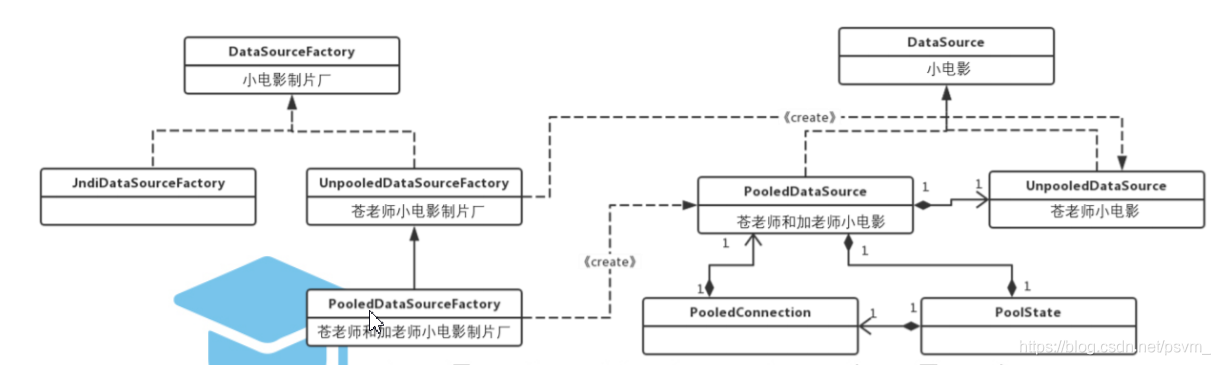
- DataSource:数据源接口,JDBC 标准规范之一,定义了获取获取 Connection 的方法;
- UnPooledDataSource:不带连接池的数据源,获取连接的方式和手动通过 JDBC 获取连 接的方式是一样的;
- PooledDataSource:带连接池的数据源,提高连接资源的复用性,避免频繁创建、关闭 连接资源带来的开销;
- DataSourceFactory:工厂接口,定义了创建 Datasource 的方法;
- UnpooledDataSourceFactory:工厂接口的实现类之一,用于创建 UnpooledDataSource(不 带连接池的数据源);
- PooledDataSourceFactory:工厂接口的实现类之一,用于创建 PooledDataSource(带连 接池的数据源);
3.4 数据库连接池技术解析
数据库连接池技术是提升数据库访问效率常用的手段,使用连接池可以提高连接资源的复用 性,避免频繁创建、关闭连接资源带来的开销,池化技术也是大厂高频面试题。
- MyBatis 内 部就带了一个连接池的实现,接下来重点解析连接池技术的数据结构和算法;先重点分析下 跟连接池相关的关键类:
- PooledDataSource:一个简单,同步的、线程安全的数据库连接池
- PooledConnection:使用动态代理封装了真正的数据库连接对象,在连接使用之前和关 闭时进行增强;
- PoolState:用于管理 PooledConnection 对象状态的组件,通过两个 list 分别管理空闲状 态的连接资源和活跃状态的连接资源,如下图,需要注意的是这两个 List 使用 ArrayList 实现,存在并发安全的问题,因此在使用时,注意加上同步控制;
重点解析获取资源和回收资源的流程,获取连接资源的过程如下图: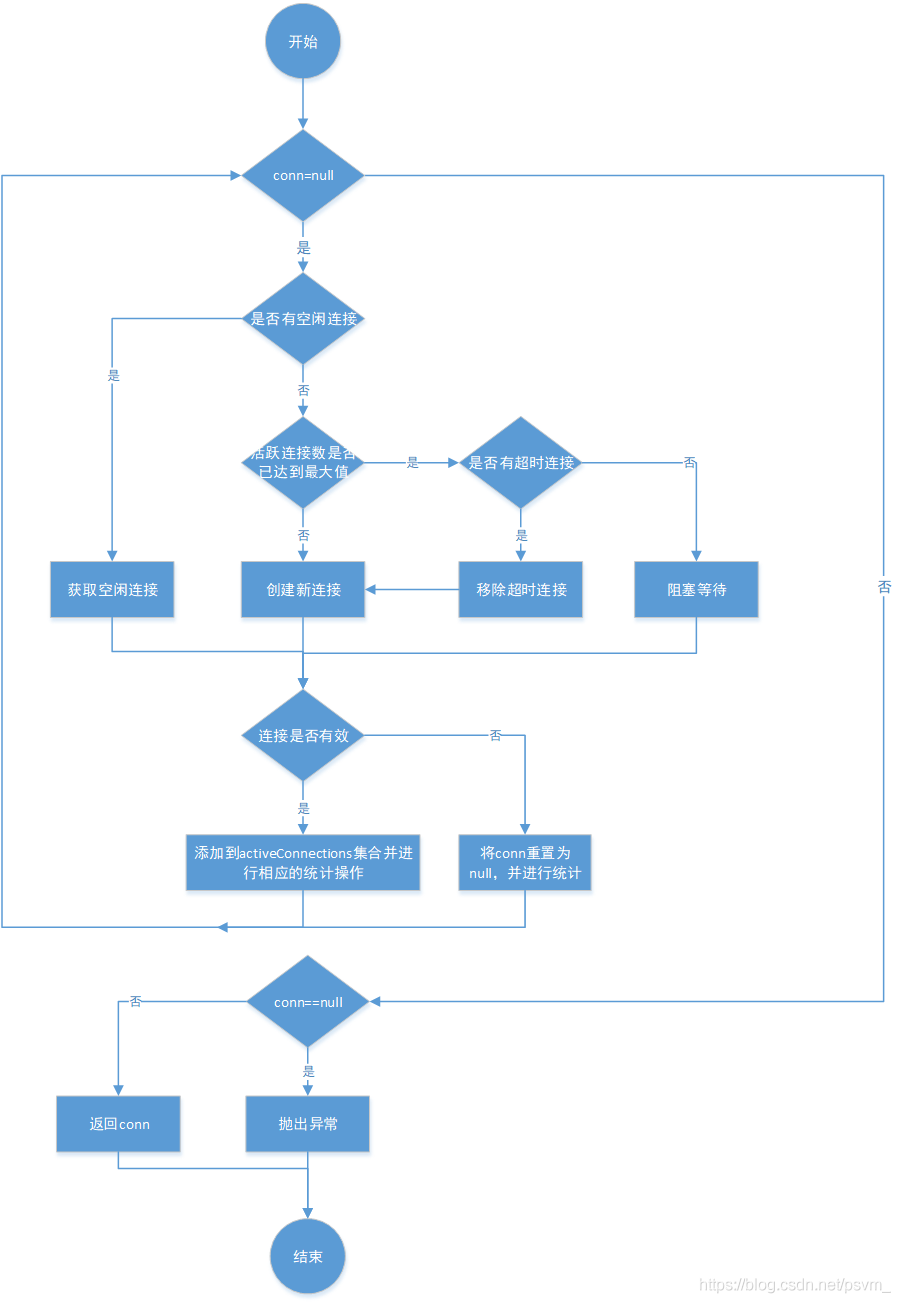
参考代码:org.apache.ibatis.datasource.pooled.PooledDataSource.popConnection(String, String)
//回收连接资源protectedvoidpushConnection(PooledConnection conn)throwsSQLException{synchronized(state){//回收连接必须是同步的
state.activeConnections.remove(conn);//从活跃连接池中删除此连接if(conn.isValid()){//判断闲置连接池资源是否已经达到上限if(state.idleConnections.size()< poolMaximumIdleConnections&& conn.getConnectionTypeCode()== expectedConnectionTypeCode){//没有达到上限,进行回收
state.accumulatedCheckoutTime+= conn.getCheckoutTime();if(!conn.getRealConnection().getAutoCommit()){
conn.getRealConnection().rollback();//如果还有事务没有提交,进行回滚操作}//基于该连接,创建一个新的连接资源,并刷新连接状态PooledConnection newConn=newPooledConnection(conn.getRealConnection(),this);
state.idleConnections.add(newConn);
newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());//老连接失效
conn.invalidate();if(log.isDebugEnabled()){
log.debug("Returned connection "+ newConn.getRealHashCode()+" to pool.");}//唤醒其他被阻塞的线程
state.notifyAll();}else{//如果闲置连接池已经达到上限了,将连接真实关闭
state.accumulatedCheckoutTime+= conn.getCheckoutTime();if(!conn.getRealConnection().getAutoCommit()){
conn.getRealConnection().rollback();}//关闭真的数据库连接
conn.getRealConnection().close();if(log.isDebugEnabled()){
log.debug("Closed connection "+ conn.getRealHashCode()+".");}//将连接对象设置为无效
conn.invalidate();}}else{if(log.isDebugEnabled()){
log.debug("A bad connection ("+ conn.getRealHashCode()+") attempted to return to the pool, discarding connection.");}
state.badConnectionCount++;}}}//从连接池获取资源privatePooledConnectionpopConnection(String username,String password)throwsSQLException{boolean countedWait=false;PooledConnection conn=null;long t=System.currentTimeMillis();//记录尝试获取连接的起始时间戳int localBadConnectionCount=0;//初始化获取到无效连接的次数while(conn==null){synchronized(state){//获取连接必须是同步的if(!state.idleConnections.isEmpty()){//检测是否有空闲连接// Pool has available connection//有空闲连接直接使用
conn= state.idleConnections.remove(0);if(log.isDebugEnabled()){
log.debug("Checked out connection "+ conn.getRealHashCode()+" from pool.");}}else{// 没有空闲连接if(state.activeConnections.size()< poolMaximumActiveConnections){//判断活跃连接池中的数量是否大于最大连接数// 没有则可创建新的连接
conn=newPooledConnection(dataSource.getConnection(),this);if(log.isDebugEnabled()){
log.debug("Created connection "+ conn.getRealHashCode()+".");}}else{// 如果已经等于最大连接数,则不能创建新连接//获取最早创建的连接PooledConnection oldestActiveConnection= state.activeConnections.get(0);long longestCheckoutTime= oldestActiveConnection.getCheckoutTime();if(longestCheckoutTime> poolMaximumCheckoutTime){//检测是否已经以及超过最长使用时间// 如果超时,对超时连接的信息进行统计
state.claimedOverdueConnectionCount++;//超时连接次数+1
state.accumulatedCheckoutTimeOfOverdueConnections+= longestCheckoutTime;//累计超时时间增加
state.accumulatedCheckoutTime+= longestCheckoutTime;//累计的使用连接的时间增加
state.activeConnections.remove(oldestActiveConnection);//从活跃队列中删除if(!oldestActiveConnection.getRealConnection().getAutoCommit()){//如果超时连接未提交,则手动回滚try{
oldestActiveConnection.getRealConnection().rollback();}catch(SQLException e){//发生异常仅仅记录日志/*
Just log a message for debug and continue to execute the following
statement like nothing happend.
Wrap the bad connection with a new PooledConnection, this will help
to not intterupt current executing thread and give current thread a
chance to join the next competion for another valid/good database
connection. At the end of this loop, bad {@link @conn} will be set as null.
*/
log.debug("Bad connection. Could not roll back");}}//在连接池中创建新的连接,注意对于数据库来说,并没有创建新连接;
conn=newPooledConnection(oldestActiveConnection.getRealConnection(),this);
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());//让老连接失效
oldestActiveConnection.invalidate();if(log.isDebugEnabled()){
log.debug("Claimed overdue connection "+ conn.getRealHashCode()+".");}}else{// 无空闲连接,最早创建的连接没有失效,无法创建新连接,只能阻塞try{if(!countedWait){
state.hadToWaitCount++;//连接池累计等待次数加1
countedWait=true;}if(log.isDebugEnabled()){
log.debug("Waiting as long as "+ poolTimeToWait+" milliseconds for connection.");}long wt=System.currentTimeMillis();
state.wait(poolTimeToWait);//阻塞等待指定时间
state.accumulatedWaitTime+=System.currentTimeMillis()- wt;//累计等待时间增加}catch(InterruptedException e){break;}}}}if(conn!=null){//获取连接成功的,要测试连接是否有效,同时更新统计数据// ping to server and check the connection is valid or notif(conn.isValid()){//检测连接是否有效if(!conn.getRealConnection().getAutoCommit()){
conn.getRealConnection().rollback();//如果遗留历史的事务,回滚}//连接池相关统计信息更新
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime+=System.currentTimeMillis()- t;}else{//如果连接无效if(log.isDebugEnabled()){
log.debug("A bad connection ("+ conn.getRealHashCode()+") was returned from the pool, getting another connection.");}
state.badConnectionCount++;//累计的获取无效连接次数+1
localBadConnectionCount++;//当前获取无效连接次数+1
conn=null;//拿到无效连接,但如果没有超过重试的次数,允许再次尝试获取连接,否则抛出异常if(localBadConnectionCount>(poolMaximumIdleConnections+ poolMaximumLocalBadConnectionTolerance)){if(log.isDebugEnabled()){
log.debug("PooledDataSource: Could not get a good connection to the database.");}thrownewSQLException("PooledDataSource: Could not get a good connection to the database.");}}}}}if(conn==null){if(log.isDebugEnabled()){
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");}thrownewSQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");}return conn;}4. 缓存模块分析
4.1 需求分析
MyBatis 缓存模块需满足如下需求:
MyBatis 缓存的实现是基于 Map 的,从缓存里面读写数据是缓存模块的核心基础功能;
除核心功能之外,有很多额外的附加功能,如:防止缓存击穿,添加缓存清空策略(fifo、 lru)、序列化功能、日志能力、定时清空能力等;
附加功能可以以任意的组合附加到核心基础功能之上; 基于Map核心缓存能力,将阻塞、清空策略、序列化、日志等等能力以任意组合的方式优 雅的增强是 Mybatis 缓存模块实现最大的难题,用动态代理或者继承的方式扩展多种附加能力的传统方式存在以下问题:这些方式是静态的,用户不能控制增加行为的方式和时机;另外,新功能的存在多种组合,使用继承可能导致大量子类存在。
综上,MyBtis 缓存模块采用 了装饰器模式实现了缓存模块;
4.2 装饰器模式
装饰器模式是一种用于代替继承的技术,无需通过继承增加子类就能扩展对象的新功能。使 用对象的关联关系代替继承关系,更加灵活,同时避免类型体系的快速膨胀。装饰器 UML 类图如下: