1.方法一:调用cuda()
步骤如下:
(1)找到网络模型,调用cuda方法,将网络模型转移到cuda中去
tudui=Tudui()
#A.找到网络模型,调用cuda方法,将网络模型转移到cuda中去
if torch.cuda.is_available():#如果cuda可用
tudui=tudui.cuda()(2)找到损失函数,调用cuda方法,将网络模型转移到cuda中去
#4.定义损失函数loss_fn=nn.CrossEntropyLoss() #B.找到损失函数,调用cuda方法,将网络模型转移到cuda中去 if torch.cuda.is_available(): loss_fn=loss_fn.cuda()
(3)将数据转移到cuda中去
训练集的数据:
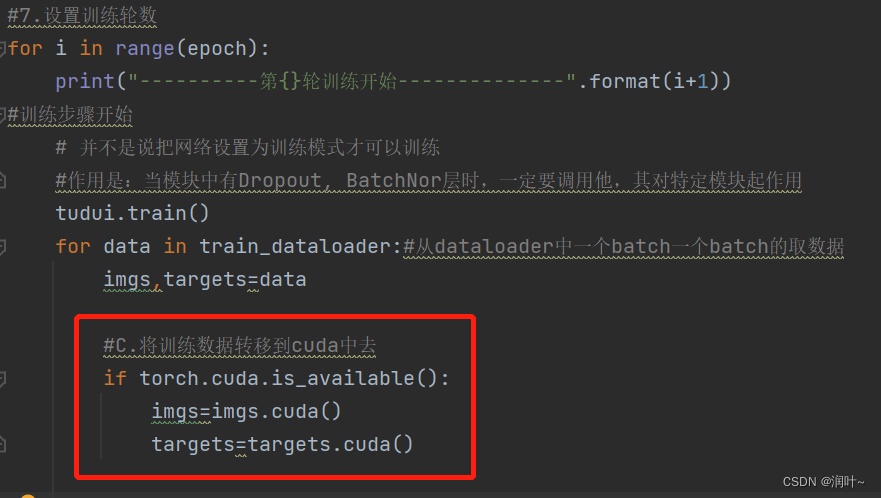
测试集的数据:
完整代码Train_gpu_1.py如下:
#A.找到网络模型
#B.数据(输入,标注)
#C.损失函数
#找到以上3种,调用.cuda()方法
import torch
from torch import nn
import torchvision.datasets
#把model中的所有引入,model中有模型
from torch.utils.tensorboard import SummaryWriter
import time
#from model import *
#1.准备数据集
#训练集
from torch import nn
from torch.utils.data import DataLoader
#训练集
train_data=torchvision.datasets.CIFAR10("dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
#测试集
test_data=torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#查看数据集有多少数据
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("训练数据集的长度为:{}".format(test_data_size))
#2.利用dataloader加载数据集
train_dataloader=DataLoader(train_data,batch_size=64)
test_databoader=DataLoader(test_data,batch_size=64)
#3.创建网络模型
class Tudui(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
tudui=Tudui()
#A.找到网络模型,调用cuda方法,将网络模型转移到cuda中去
if torch.cuda.is_available():#cuda可用的话
tudui=tudui.cuda()
#4.定义损失函数
loss_fn=nn.CrossEntropyLoss()
#B.找到损失函数,调用cuda方法,将网络模型转移到cuda中去
if torch.cuda.is_available():
loss_fn=loss_fn.cuda()
#5.定义优化器
# learning_rate=0.01#学习速率 1e-2=1x(10)^(-2)
learning_rate=1e-2
optimizer=torch.optim.SGD(tudui.parameters(),lr=learning_rate)#params:网络模型
#6.设置训练网络的一些参数
#记录训练的次数
total_train_step=0
#记录测试的册数
total_test_step=0
#训练的轮数
epoch=10
#添加tensorboard
writer=SummaryWriter("logs_train")
start_time=time.time()#记录当前时间
#7.设置训练轮数
for i in range(epoch):
print("----------第{}轮训练开始--------------".format(i+1))
#训练步骤开始
# 并不是说把网络设置为训练模式才可以训练
#作用是:当模块中有Dropout, BatchNor层时,一定要调用他,其对特定模块起作用
tudui.train()
for data in train_dataloader:#从dataloader中一个batch一个batch的取数据
imgs,targets=data
#C.将训练数据转移到cuda中去
if torch.cuda.is_available():
imgs=imgs.cuda()
targets=targets.cuda()
output=tudui(imgs)#真实输出64*10维
#print(output)
#(1)计算真实输出与目标之间的误差
loss=loss_fn(output,targets)
#(2)优化器调优 优化模型
optimizer.zero_grad()#梯度清零
loss.backward()#反向传播,得到每个参数的梯度
optimizer.step()#对每个梯度进行优化
total_train_step=total_train_step+1
if total_train_step%100==0:
end_time=time.time()#记录当前时间
print(end_time-start_time)
print("训练次数:{}, Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_losss",loss.item(),total_train_step)
#如何知道模型有没有训练好---------进行测试,在测试集上跑一遍,用测试数据集上的损失或正确率来评估模型有没有训练好
#8.测试
#(1)设置测试 参数
total_test_loss=0#总损失
total_accuracy=0#整体正确率
#(2)测试步骤开始,
# 作用是:当模块中有Dropout, BatchNor层时,一定要调用他,其对特定模块起作用
tudui.eval()
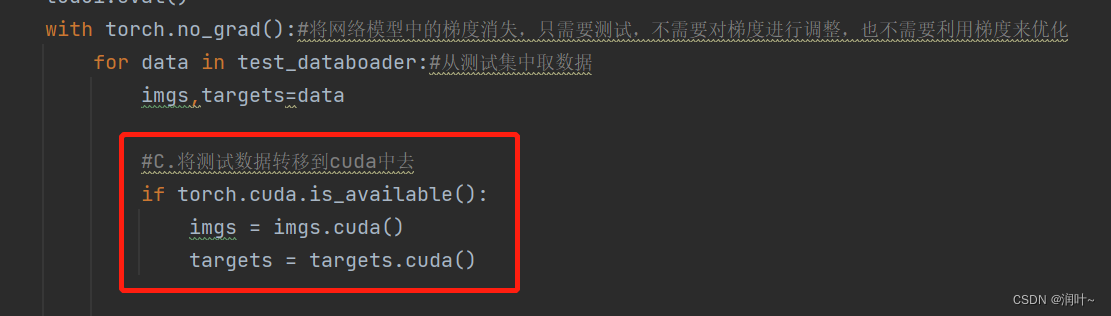
with torch.no_grad():#将网络模型中的梯度消失,只需要测试,不需要对梯度进行调整,也不需要利用梯度来优化
for data in test_databoader:#从测试集中取数据
imgs,targets=data
#C.将测试数据转移到cuda中去
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs=tudui(imgs)
loss=loss_fn(outputs,targets)
total_test_loss=total_test_loss+loss.item()
# 求每个对应位置最大的值和targets比较返回true或false。利用sum求和
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
#9.计算测试集的loss,正确率,以此展现训练网络在测试集上的效果
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))#正确率为测试正确的个数/测试集总个数
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
writer.add_scalar("test_loss",total_test_loss,total_test_step)
total_test_step=total_test_step+1
#12.保存模型(在特定的步数或某一轮保存模型)
#方式1:保存模型
torch.save(tudui,"tudui_{}.pth".format(i))#将模型保存在指定路径中
#方式2:保存模型
#torch.sava(tudui.state_dict(),"tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
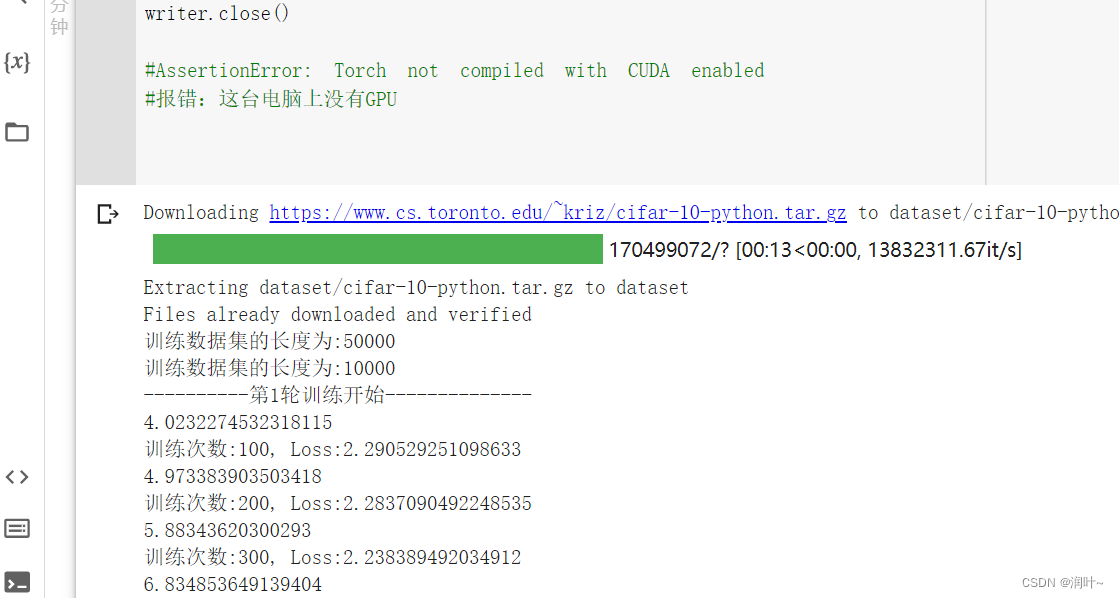
#AssertionError: Torch not compiled with CUDA enabled
#报错:这台电脑上没有GPU注:google为我们提供了一个免费的GPU供我们使用,每周可以免费使用30个小时
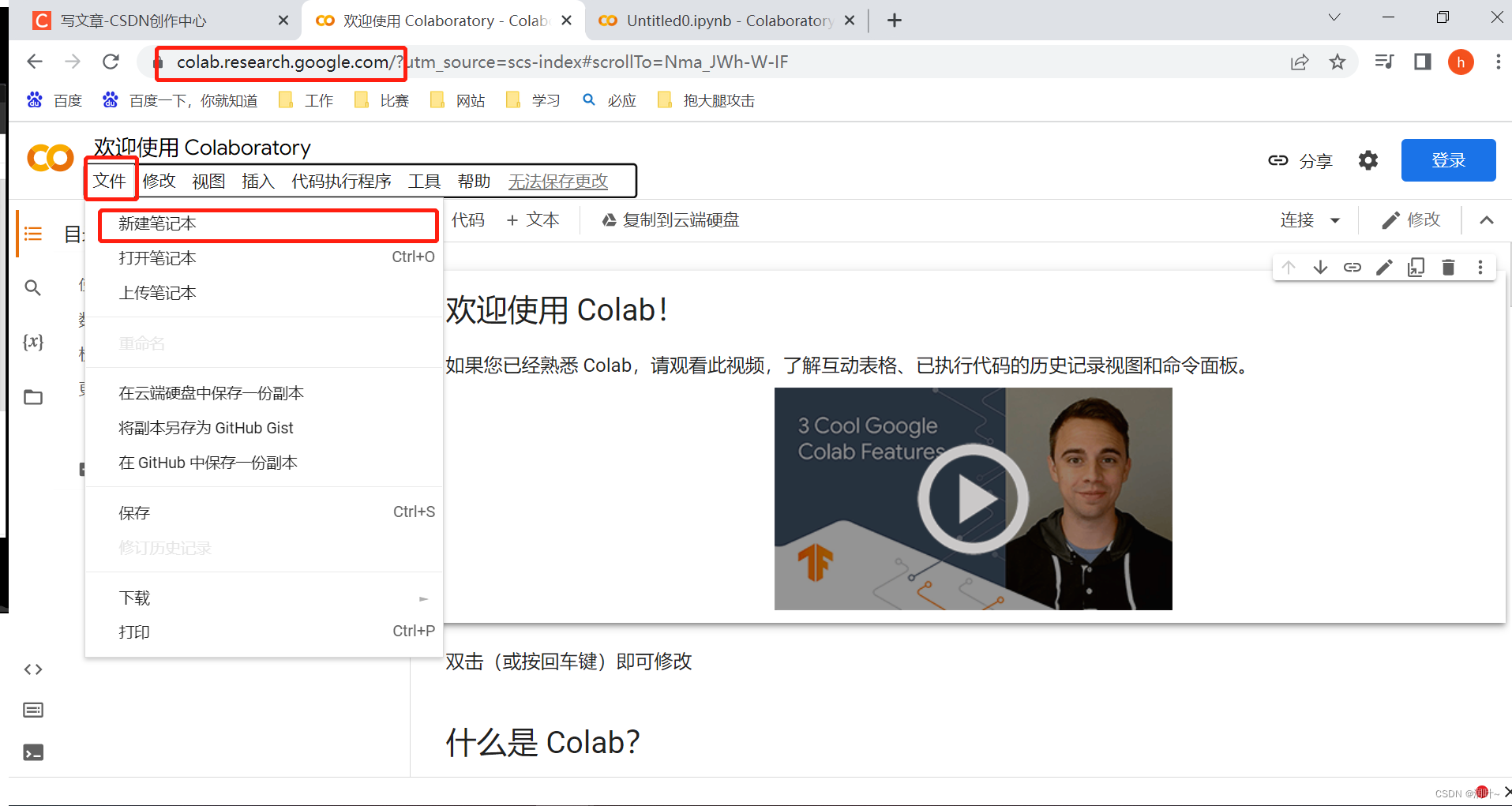
https://colab.research.google.com/?utm_source=scs-index#scrollTo=Nma_JWh-W-IF
a. 新建一个笔记本
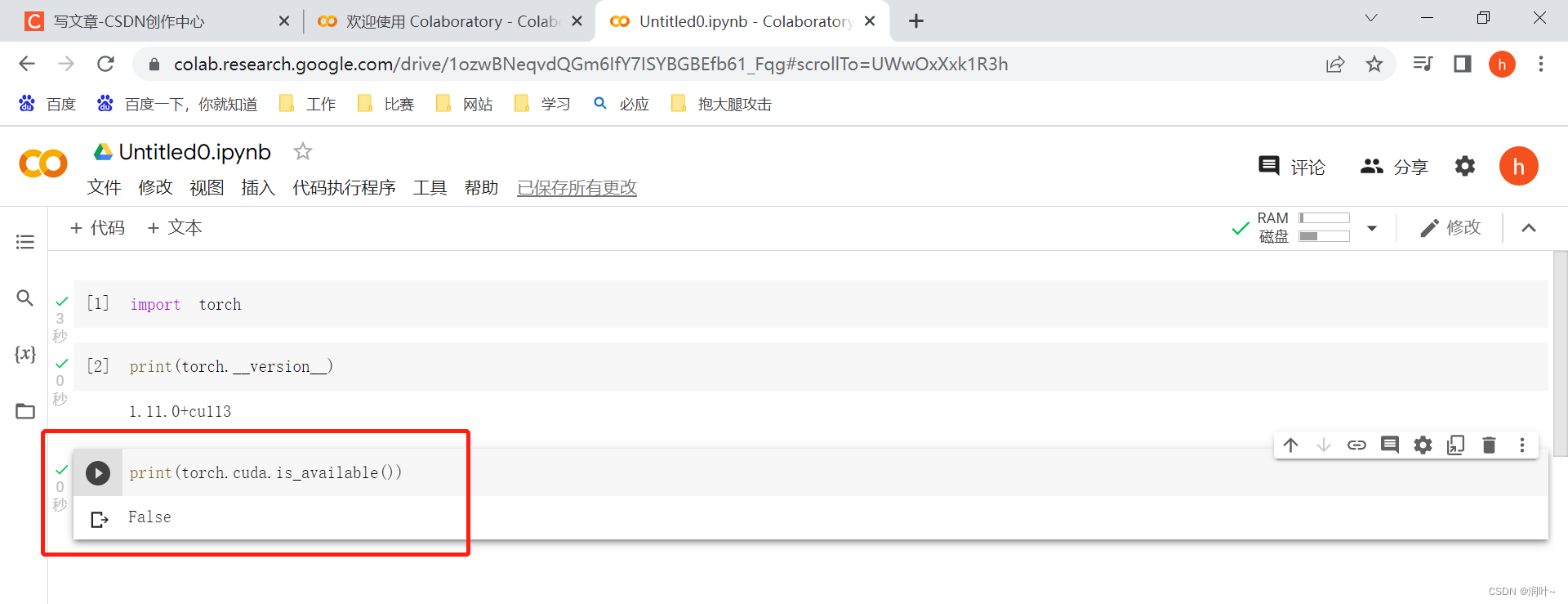
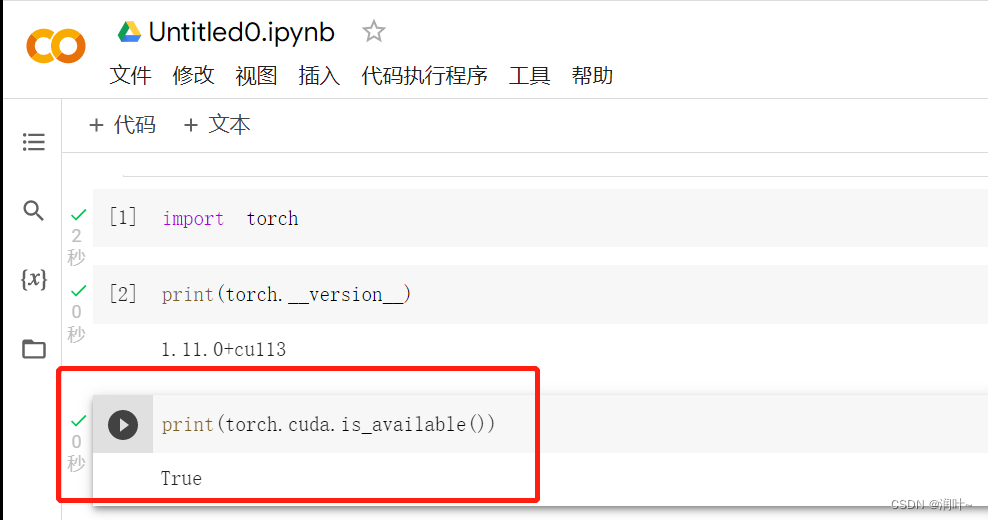
b. 看看cuda可不可用
c. 不可用的话选择----修改---->笔记本设置 ---->选择GPU---->保存

d. 现在可以用了
将上述代码复制进去,运行,发现,使用google的GPU训练速度较快
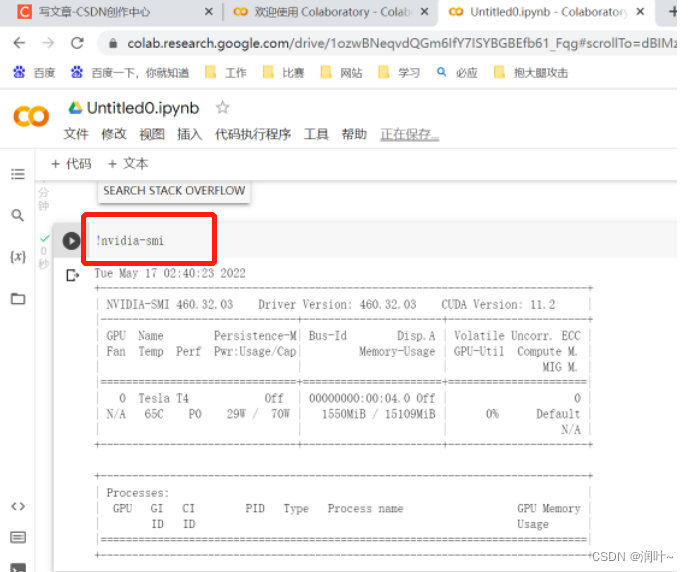
e. 如果想在里面运行命令行,前面加!
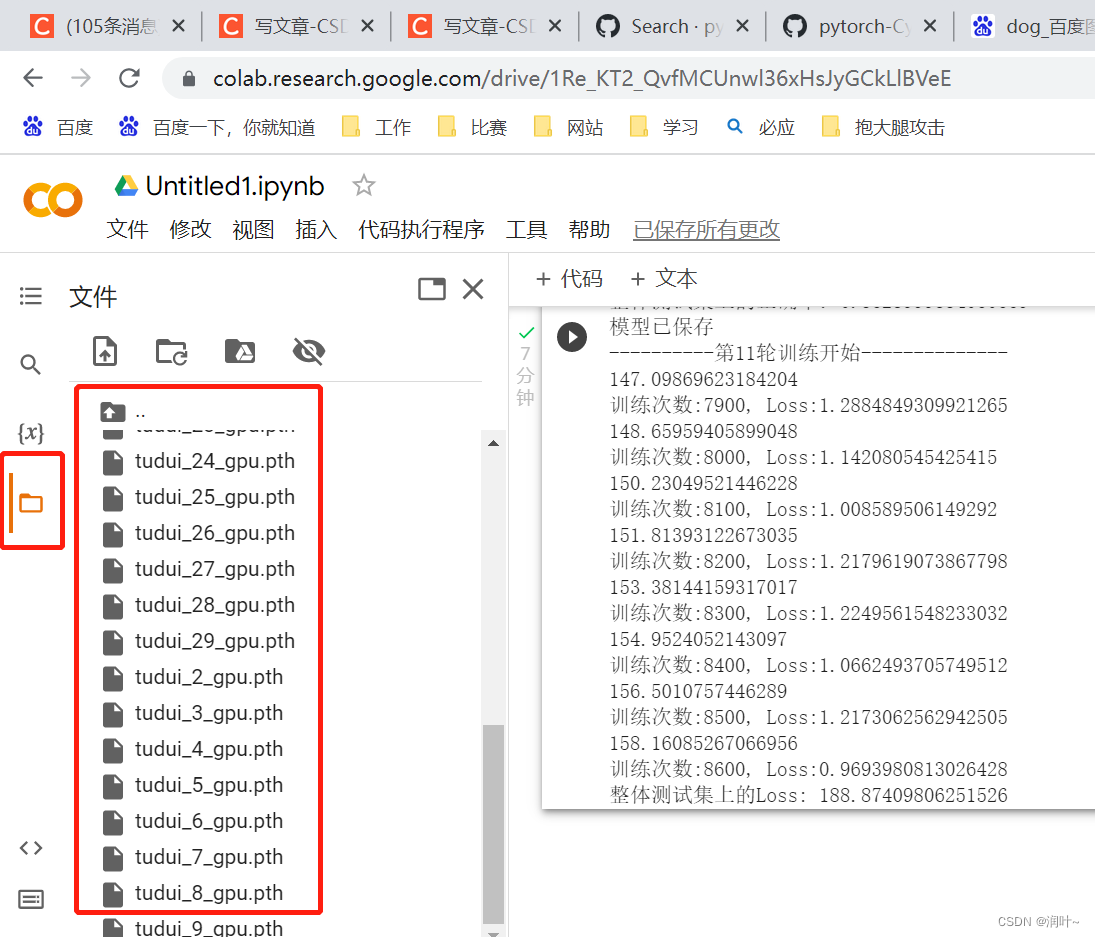
f.在这里查看保存的模型和数据
2、方法二:调用.to(device)
device=torch.device("cpu")或torch.device("cuda")
如果电脑上有一个显卡torch.device("cuda:0")
如果电脑上有多个显卡torch.device("cuda:1") 指定第二个显卡
步骤入下:
(1)定义训练的设备
#定义训练的设备
device=torch.device("cuda")
#device=torch.device("cuda" if torch.cuda.is_available() else "cpu")(2)找到网络模型,调用to方法,将网络模型转移到设备中去
tudui=Tudui() #A.找到网络模型,调用to方法,将网络模型转移到设备中去 tudui.to(device)
(3)找到损失函数,调用to方法,将网络模型转移到设备中去
#4.定义损失函数 loss_fn=nn.CrossEntropyLoss() #B.找到损失函数,调用to方法,将网络模型转移到设备中去 loss_fn=loss_fn.to(device)
(4)将训练数据转移到设备中去
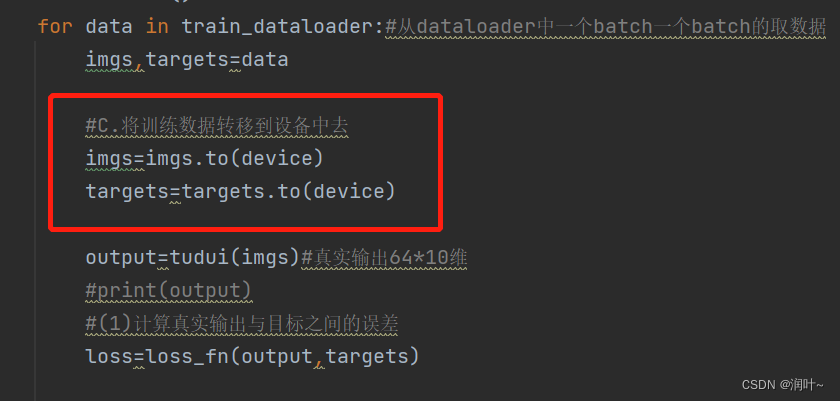
(5)将测试数据转移到设备中去
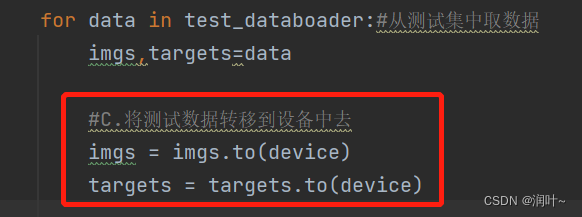
完整代码Train_gpu_2.py如下:
#A.找到网络模型
#B.数据(输入,标注)
#C.损失函数
#找到以上3种,调用.cuda()方法
import torch
from torch import nn
import torchvision.datasets
#把model中的所有引入,model中有模型
from torch.utils.tensorboard import SummaryWriter
import time
#from model import *
#1.准备数据集
#训练集
from torch import nn
from torch.utils.data import DataLoader
#定义训练的设备
device=torch.device("cuda")
#device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
#训练集
train_data=torchvision.datasets.CIFAR10("dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
#测试集
test_data=torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
#查看数据集有多少数据
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("训练数据集的长度为:{}".format(test_data_size))
#2.利用dataloader加载数据集
train_dataloader=DataLoader(train_data,batch_size=64)
test_databoader=DataLoader(test_data,batch_size=64)
#3.创建网络模型
class Tudui(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
tudui=Tudui()
#A.找到网络模型,调用to方法,将网络模型转移到设备中去
tudui.to(device)
#4.定义损失函数
loss_fn=nn.CrossEntropyLoss()
#B.找到损失函数,调用to方法,将网络模型转移到设备中去
loss_fn=loss_fn.to(device)
#5.定义优化器
# learning_rate=0.01#学习速率 1e-2=1x(10)^(-2)
learning_rate=1e-2
optimizer=torch.optim.SGD(tudui.parameters(),lr=learning_rate)#params:网络模型
#6.设置训练网络的一些参数
#记录训练的次数
total_train_step=0
#记录测试的册数
total_test_step=0
#训练的轮数
epoch=10
#添加tensorboard
writer=SummaryWriter("logs_train")
start_time=time.time()#记录当前时间
#7.设置训练轮数
for i in range(epoch):
print("----------第{}轮训练开始--------------".format(i+1))
#训练步骤开始
# 并不是说把网络设置为训练模式才可以训练
#作用是:当模块中有Dropout, BatchNor层时,一定要调用他,其对特定模块起作用
tudui.train()
for data in train_dataloader:#从dataloader中一个batch一个batch的取数据
imgs,targets=data
#C.将训练数据转移到设备中去
imgs=imgs.to(device)
targets=targets.to(device)
output=tudui(imgs)#真实输出64*10维
#print(output)
#(1)计算真实输出与目标之间的误差
loss=loss_fn(output,targets)
#(2)优化器调优 优化模型
optimizer.zero_grad()#梯度清零
loss.backward()#反向传播,得到每个参数的梯度
optimizer.step()#对每个梯度进行优化
total_train_step=total_train_step+1
if total_train_step%100==0:
end_time=time.time()#记录当前时间
print(end_time-start_time)
print("训练次数:{}, Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_losss",loss.item(),total_train_step)
#如何知道模型有没有训练好---------进行测试,在测试集上跑一遍,用测试数据集上的损失或正确率来评估模型有没有训练好
#8.测试
#(1)设置测试 参数
total_test_loss=0#总损失
total_accuracy=0#整体正确率
#(2)测试步骤开始,
# 作用是:当模块中有Dropout, BatchNor层时,一定要调用他,其对特定模块起作用
tudui.eval()
with torch.no_grad():#将网络模型中的梯度消失,只需要测试,不需要对梯度进行调整,也不需要利用梯度来优化
for data in test_databoader:#从测试集中取数据
imgs,targets=data
#C.将测试数据转移到设备中去
imgs = imgs.to(device)
targets = targets.to(device)
outputs=tudui(imgs)
loss=loss_fn(outputs,targets)
total_test_loss=total_test_loss+loss.item()
# 求每个对应位置最大的值和targets比较返回true或false。利用sum求和
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
#9.计算测试集的loss,正确率,以此展现训练网络在测试集上的效果
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))#正确率为测试正确的个数/测试集总个数
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
writer.add_scalar("test_loss",total_test_loss,total_test_step)
total_test_step=total_test_step+1
#12.保存模型(在特定的步数或某一轮保存模型)
#方式1:保存模型
torch.save(tudui,"tudui_{}.pth".format(i))#将模型保存在指定路径中
#方式2:保存模型
#torch.sava(tudui.state_dict(),"tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
#AssertionError: Torch not compiled with CUDA enabled
#报错:这台电脑上没有GPU