该博客基于以下项目的开源代码进行分析:
Simple Pose: Rethinking and Improving a Bottom-up Approach for Multi-Person Pose Estimation”
Github代码地址:代码
参考:
Github《Distribution is all you need》
知乎《一个 Pytorch 训练实践 (分布式训练 + 半精度/混合精度训练)》
《pytorch apex 混合精度训练和horovod分布式训练》
《PyTorch 单机多卡操作总结:分布式DataParallel,混合精度,Horovod)》
《超全Pytorch多GPU训练》(1. 单机多卡2. 多机多卡 训练见此博客)
《pytorch单机多卡:从DataParallel到distributedDataParallel》
Nvidia深度学习加速包Apex介绍:主要是apex不仅可以分布式训练,还可以使用混合精度模式以及同步bn(Sync-BN)
内容速览
- 'train.py':仅在一个 GPU 上进行单一进程训练的代码【单GPU无并行】;
- 'train_parallel.py':利用Dataparallel在多个GPU 上进行单一进程训练的代码 (包括不同GPU之间的负载均衡);【多GPU单线程】
- 'train_distributed.py' (recommended): 使用usingNvidia Apex &Distributed Training在多个GPU 上进行多进程训练的代码。【多GPU多线程】
运行执行命令:
python -m torch.distributed.launch --nproc_per_node=4 train_distributed.py其中nproc_per_node参数用于指定为当前主机创建的进程数,由于我们是单机多卡,所以这里node数量为1,所以我们这里设置为所使用的GPU数量即可。
基础知识
一、同步BN (SyncBN)
同步批归一化也称作跨卡同步批归一化(Cross-GPU Synchronized Batch Normalization)。
现有的标准 Batch Normalization 因为使用数据并行(Data Parallel),是单卡的实现模式,只对单个卡上对样本进行归一化,相当于减小了批量大小(batch-size)(详见BN工作原理部分)。 对于比较消耗显存的训练任务时,往往单卡上的相对批量过小,影响模型的收敛效果。 之前在我们在图像语义分割的实验中,Jerry和我就发现使用大模型的效果反而变差,实际上就是BN在作怪。 跨卡同步 Batch Normalization 可以使用全局的样本进行归一化,这样相当于‘增大‘了批量大小,这样训练效果不再受到使用 GPU 数量的影响。 最近在图像分割、物体检测的论文中,使用跨卡BN也会显著地提高实验效果,所以跨卡 BN 已然成为竞赛刷分、发论文的必备神器。
(1)Batch Normalization如何工作
既然是技术贴,读者很多是深学大牛,为什么还要在这里赘述BatchNorm这个简单概念吗?其实不然,很多做科研的朋友如果没有解决过相关问题, 很容易混淆BN在训练和测试时候的工作方式。记得在17年CVPR的tutoial 上, 何恺明和RBG两位大神分别在自己的talk上都特意强调了BN的工作原理,可见就算台下都是CV的学者,也有必要复习一遍这些知识。
- 工作原理:
BN 有效地加速了模型训练,加大 learning rate,让模型不再过度依赖初始化。它在训练时在网络内部进行归一化(normalization), 为训练提供了有效的 regularization,抑制过拟合,用原作者的话是防止了协方差偏移。这里上一张图来展示训练模式的BN:
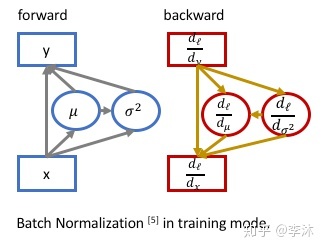
其中输入样本,其均值为,方差为, BN的输出,是可学习对参数。 个人认为,这种强大的效果其实来自于back-propagation时候,来自于均值和方差对输入样本的梯度( )。 这也是BN在训练模式与其在测试模式的重要区别,在测试模式(evaluation mode)下, 使用训练集上累积的均值和方差,在back-propagation的时候他们对输入样本没有梯度(gradient)。
- 数据并行:
深度学习平台在多卡(GPU)运算的时候都是采用的数据并行(DataParallel),如下图:
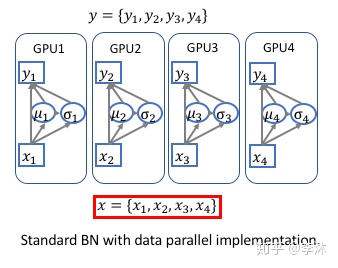
每次迭代,输入被等分成多份,然后分别在不同的卡上前向(forward)和后向(backward)运算,并且求出梯度,在迭代完成后合并 梯度、更新参数,再进行下一次迭代。因为在前向和后向运算的时候,每个卡上的模型是单独运算的,所以相应的Batch Normalization 也是在卡内完成,所以实际BN所归一化的样本数量仅仅局限于卡内,相当于批量大小(batch-size)减小了。
(2)如何实现 SyncBN
跨卡同步BN的关键是在前向运算的时候拿到全局的均值和方差,在后向运算时候得到相应的全局梯度。 最简单的实现方法是先同步求均值,再发回各卡然后同步求方差,但是这样就同步了两次。实际上只需要同步一次就可以, 我们使用了一个非常简单的技巧,把方差表示为, 附上一张图:
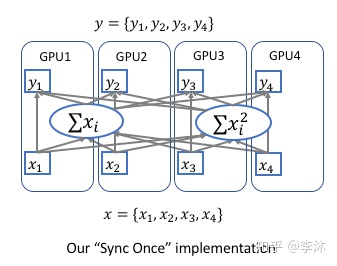
这样在前向运算的时候,我们只需要在各卡上算出均值与方差,再跨卡求出全局的和即可得到正确的均值和方差, 同理我们在后向运算的时候只需同步一次,求出相应的梯度与。 我们在最近的论文Context Encoding for Semantic Segmentation 里面也分享了这种同步一次的方法。
有了跨卡BN我们就不用担心模型过大用多卡影响收敛效果了,因为不管用多少张卡只要全局的批量大小一样,都会得到相同的效果。
(3)代码实现 SyncBN
方法一:使用Pytorch的DataParallel实现如下:
import torch
from modules import nn as NN
num_gpu = torch.cuda.device_count()
model = nn.Sequential(
nn.Conv2d(3, 3, 1, 1, bias=False),
NN.BatchNorm2d(3),
nn.ReLU(inplace=True),
nn.Conv2d(3, 3, 1, 1, bias=False),
NN.BatchNorm2d(3),
).cuda()
model = nn.DataParallel(model, device_ids=range(num_gpu))
x = torch.rand(num_gpu, 3, 2, 2).cuda()
z = model(x)方法二:使用Nvidia官方深度学习加速库Apex包【Document】的convert_syncbn_model实现如下:
model = Network(opt, config, dist=True, bn=True)
if args.sync_bn: # 判断是否需要同步批归一化
import apex
print("Using apex synced BN.")
model = apex.parallel.convert_syncbn_model(model)二、分布式并行训练
分布式和并行是两个概念,分布式计算强调分布,通常指的的多台机器或者节点干一件事情.典型的例子就是mapreduce, spark之流.当然现在比较火的tensorflow, mxnet 如果是多机做训练也可归入分布式计算;
并行计算的概念比分布式计算大的多,简单来说,并行的做一件事情就可以理解成并行计算,一定要理解并行可不一定要分布。举个例子,mapreduce, spark可以看作并行计算,同一台机器上的multi-core上跑的multi-thread程序也可以看作并行计算,GPU利用processing unit也是并行计算。
(1)何为并行?
pytorch的并行分为模型并行、数据并行。
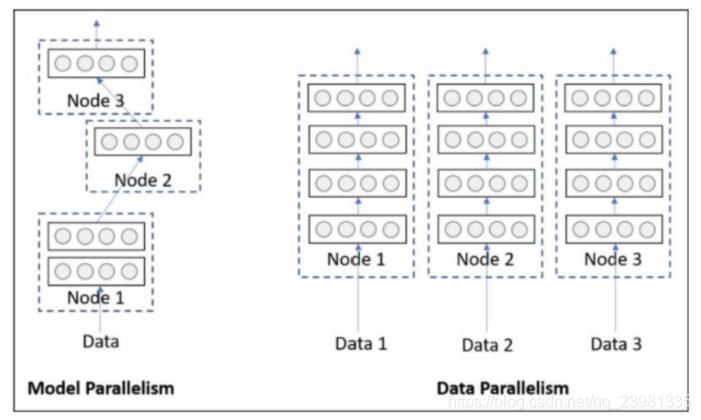
左侧模型并行:是网络太大,一张卡存不了,那么拆分,然后进行模型并行训练。
右侧数据并行:多个显卡同时采用数据训练网络的副本。
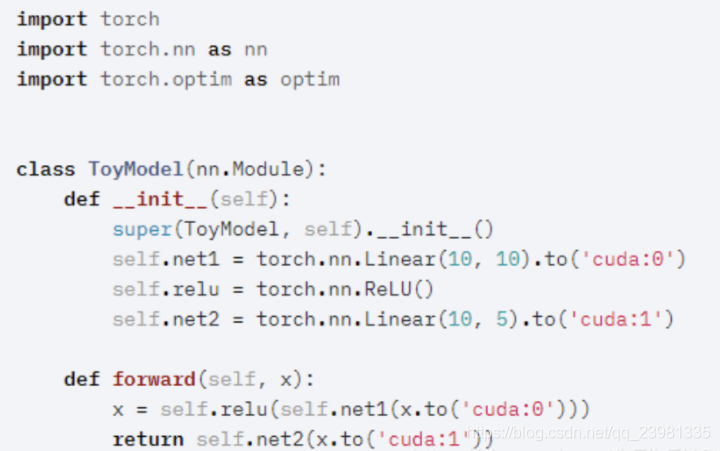
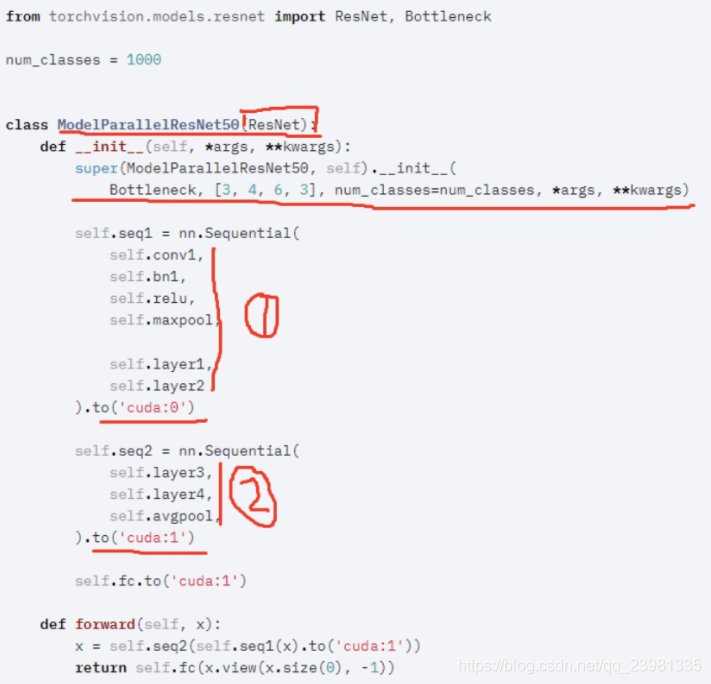
A.模型并行的代码实现
B.数据并行
数据并行的操作要求我们将数据划分成多份,然后发送给多个 GPU 进行并行的计算。在Pytorh中使用最多的为数据并行,以下详细介绍。
(2)数据并行【torch.nn.DataParallel】及分布式数据并行 【torch.nn.parallel.DistributedDataParallel】
torch.nn.DataParallel与torch.nn.parallel.DistributedDataParallel的区别:
- 如果模型太大而无法容纳在单个 GPU 上,则必须使用模型并行将其拆分到多个 GPU 中。与模型并行一起使用;
DataParallel目前没有。DataParallel是单进程多线程,并且只能在单台机器上运行,而DistributedDataParallel是多进程,并且适用于单机和多机训练。 因此,即使在单机训练中,数据足够小以适合单机,DistributedDataParallel仍比DataParallel快。DistributedDataParallel还预先复制模型,而不是在每次迭代时复制模型,并避免了全局解释器锁定。- 如果您的两个数据都太大而无法容纳在一台计算机和上,而您的模型又太大了以至于无法安装在单个 GPU 上,则可以将模型并行(跨多个 GPU 拆分单个模型)与
DistributedDataParallel结合使用。 在这种情况下,每个DistributedDataParallel进程都可以并行使用模型,而所有进程都将并行使用数据。
A. torch.nn.DataParallel及其使用代码
DataParallel的并行处理机制:DataParallel是将输入一个 batch 的数据均分成多份,分别送到对应的 GPU 进行计算,各 个 GPU 得到的梯度累加。与 Module 相关的所有数据也都会以浅复制的方式复制多份。每个 GPU 将针对各自的输入数据独立进行 forward 计算,在 backward 时,每个卡上的梯度会汇总到原始的 module 上,再用反向传播更新单个 GPU 上的模型参数,再将更新后的模型参数复制到剩余指定的 GPU 中,以此来实现并行。
DataParallel会将定义的网络模型参数默认放在GPU 0上,所以dataparallel实质是可以看做把训练参数从GPU拷贝到其他的GPU同时训练,这样会导致内存和GPU使用率出现很严重的负载不均衡现象,即GPU 0的使用内存和使用率会大大超出其他显卡的使用内存,因为在这里GPU0作为master来进行梯度的汇总和模型的更新,再将计算任务下发给其他GPU,所以他的内存和使用率会比其他的高。
1.单gpu(用做对比)import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
#在训练函数和测试函数中,有两个地方要判断是否用cuda,将模型和数据搬到gpu上去
model = TextCNN(args)
if args.cuda:
model.cuda()
。。。
for batch_idx, (data, target) in enumerate(train_loader):
if args.cuda:
data, target = data.cuda(), target.cuda()2.多gpu,DataParallel使用#device_ids = [0,1,2,3]
如果不设定好要使用的device_ids的话, 程序会自动找到这个机器上面可以用的所有的显卡用于训练。
如果想要限制使用的显卡数,怎么办呢?
在代码最前面使用:
os.environ['CUDA_VISIBLE_DEVICES'] == '0,5'
或者
CUDA_VISIBLE_DEVICES=1,2,3 python
# 限制代码能看到的GPU个数,这里表示指定只使用实际的0号和5号GPU
# 注意:这里的赋值必须是字符串,list会报错
————————————————下面是重点
if args.cuda:
model = model.cuda() #这里将模型复制到gpu
if len(device_ids)>1:
model = nn.DataParallel(model)
#when train and test
data = data.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)稍微完整一点:
# 这里要 model.cuda()
model = nn.DataParallel(model.cuda(), device_ids=gpus, output_device=gpus[0])
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
# 这里要 images/target.cuda()
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()B. torch.nn.parallel.DistributedDataParallel及其使用代码
DistributedDataParallel的并行处理机制:DistributedDataParallel支持 all-reduce,broadcast,send 和 receive 等等。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信。可以用于单机多卡也可用于多机多卡, 官方也曾经提到用 DistributedDataParallel 解决 DataParallel 速度慢,GPU 负载不均衡的问题。效果比DataParallel好太多!!!torch.distributed相对于torch.nn.DataParalle 是一个底层的API,所以我们要修改我们的代码,使其能够独立的在机器(节点)中运行。
与 DataParallel 的单进程控制多 GPU 不同,在 distributed 的帮助下,我们只需要编写一份代码,torch 就会自动将其分配给n个进程,分别在 n 个 GPU 上运行。
对比DataParallel,它的优势如下:
- 每个进程对应一个独立的训练过程,且只对梯度等少量数据进行信息交换。在每次迭代中,每个进程具有自己的
optimizer,并独立完成所有的优化步骤,进程内与一般的训练无异。在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由rank=0的进程,将其broadcast到所有进程。之后,各进程用该梯度来独立的更新参数。而 DataParallel是梯度汇总到gpu0,反向传播更新参数,再广播参数给其他的gpu由于各进程中的模型,初始参数一致 (初始时刻进行一次broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。而在DataParallel中,全程维护一个optimizer,对各GPU上梯度进行求和,而在主GPU进行参数更新,之后再将模型参数broadcast到其他GPU。相较于DataParallel,torch.distributed传输的数据量更少,因此速度更快,效率更高。 - 每个进程包含独立的解释器和 GIL。一般使用的Python解释器CPython:是用C语言实现Pyhon,是目前应用最广泛的解释器。全局锁使Python在多线程效能上表现不佳,全局解释器锁(Global Interpreter Lock)是Python用于同步线程的工具,使得任何时刻仅有一个线程在执行。由于每个进程拥有独立的解释器和
GIL,消除了来自单个Python进程中的多个执行线程,模型副本或GPU的额外解释器开销和GIL-thrashing,因此可以减少解释器和GIL使用冲突。这对于严重依赖Python runtime的models而言,比如说包含RNN层或大量小组件的models而言,这尤为重要。
在使用DistributedDataParallel钱,首先来了解分布式的几个概念:
group:进程组,一般就需要一个默认的
即进程组。默认情况下,只有一个组,一个 job 即为一个组,也即一个 world。当需要进行更加精细的通信时,可以通过 new_group 接口,使用 word 的子集,创建新组,用于集体通信等。
world size :所有的进程数量,几乎在所有的DDP情况下都是使用一个GPU对应一个Process
表示全局进程个数。
rank:全局的进程id
表示进程序号,用于进程间通讯,表征进程优先级。rank = 0 的主机为 master 节点。
local_rank:某个节点上的进程id。当前进程对应的GPU号,它是
to_device()方法的一个重要参数(指定加载到哪个GPU); 虽然我们经常喜欢使用os.environ['CUDA_VISIBLE_DEVICES']=0,1,5,6这样的命令,但是其实当我们使用to_device()方法时,永远都是对应0,1,2,3,也就是说全局的可见的GPU在程序local来看,是经过了一次mapping的,因此可以通过local_rank来控制将模型和数据放到哪个GPU上。进程内,GPU 编号,非显式参数,由 torch.distributed.launch 内部指定。比方说, rank = 3,local_rank = 0 表示第 3 个进程内的第 1 块 GPU。
global_rank (rank):在单节点的情况下,rank和local_rank是一致的;
torch.distributed.get_rank()# 获取全局rank,单节点就是local_ranklocal_word_size: 某个节点上的进程数 (相对比较少见)
这里需要注意的是,目前为止所有的概念的基本单元都是进程,与GPU没有关系,一个进程可以对应若干个GPU。 所以world_size 并不是等于所有的GPU数量,而人为设定的,这一点网上的很多描述并不准确。只不过平时用的最多的情况是一个进程使用一块GPU,这种情况下 world_size 可以等于所有节点的GPU数量。
假设所有进程数即 world_size为W,每个节点上的进程数即local_world_size为L,则每个进程上的两个ID:
- rank的取值范围:[0, W-1],rank=0的进程为主进程,会负责一些同步分发的工作
- local_rank的取值:[0, L-1]
官方的示意图的非常形象,如下:
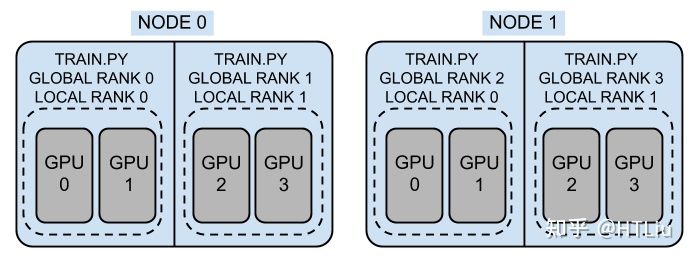
假定有2个机器或者节点(Node),每个机器上有4块GPU。图中一共有4个进程,即world_size=4,那这样每个进程占用两块GPU,其中rank就是[0,1,2,3],每个节点的local_rank就是[0,1]了,其中local_world_size 也就是2。 这里需要注意的是,local_rank是隐式参数,即torch自动分配的。比如local_rank 可以通过自动注入命令行参数或者环境变量来获得) 。
从torch1.10开始,官方建议使用环境变量的方式来获取local_rank, 在后期版本中,会移除命令行的方式。
一些简单的测试:
import torch.distributed as dist
import argparse, os
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=ine, default=0)
args = parser.parse_args()
dist.init_process_group("nccl")
rank = dist.get_rank()
local_rank_arg = args.local_rank # 命令行形式ARGS形式
local_rank_env = int(os.environ['LOCAL_RANK']) # 在利用env初始ENV环境变量形式
local_world_size = int(os.environ['LOCAL_WORLD_SIZE'])
print(f"{rank=}; {local_rank_arg=}; {local_rank_env=}; {local_world_size=}")使用python3 -m torch.distributed.launch --nproc_per_node=4 test.py在一台4卡机器上执行, 样例输出:
rank=2; local_rank_arg=2; local_rank_env=2, local_world_size=4
rank=0; local_rank_arg=0; local_rank_env=0, local_world_size=4
rank=3; local_rank_arg=3; local_rank_env=3, local_world_size=4
rank=1; local_rank_arg=1; local_rank_env=1, local_world_size=4一般的分布式训练都是为每个进程赋予一块GPU,这样比较简单而且容易调试。 这种情况下,可以通过local_rank作为当前进程GPU的id。
分布式训练的场景很多,单机多卡,多机多卡,模型并行,数据并行等等。接下来就以常见的单机多卡的情况进行记录。
目前Pytorch的分布式并行训练常使用DDP模式(Distributed DataParallell ),从基本概念,初始化启动,以及第三方的分布式训练框架展开介绍。最后以一个Bert情感分类给出完整的代码例子:torch-ddp-examples。
B.1 DDP初始化
torch的distributed分布式训练首先需要对进程组进行初始化,这是核心的一个步骤,其关键参数如下:
torch.distributed.init_process_group(backend, init_method=None, world_size=-1, rank=-1, store=None,...)首先需要指定分布式的后端,torch提供了NCCL, GLOO,MPI三种可用的后端,这三类支持的分布式操作有所不同,因此选择的时候,需要考虑具体的场景,按照官网说明,CPU的分布式训练选择GLOO, GPU的分布式训练就用NCCL即可。
接下来是初始化方法,有两种方法:
- 显式指定
init_method,可以是TCP连接、File共享文件系统、ENV环境变量三种方式,后面具体介绍。 - 显式指定
store,同时指定world_size 和 rank参数。这里的store是一种分布式中核心的key-value存储,用于不同的进程间共享信息。
这两种方法是互斥的,其实本质上第一种方式是对第二种的一个更高的封装,最后都要落到store上进行实现。如果这两种方法都没有使用,默认使用init_method='env'的方式来初始化。
对于三种init_method:
init_method='tcp://ip:port': 通过指定rank 0(即:MASTER进程)的IP和端口,各个进程进行信息交换。 需指定 rank 和 world_size 这两个参数。init_method='file://path':通过所有进程都可以访问共享文件系统来进行信息共享。需要指定rank和world_size参数。init_method=env://(常用):从环境变量中读取分布式的信息(os.environ),主要包括MASTER_ADDR, MASTER_PORT, RANK, WORLD_SIZE。 其中,rank和world_size可以选择手动指定,否则从环境变量读取。
可以发现,tcp和env两种方式比较类似(其实env就是对tcp的一层封装),都是通过网络地址的方式进行通信,也是最常用的初始化方法。
接下来看具体TCP/ENV初始化的的一个小例子:
import os, argparse
import torch
import torch.distributed as dist
parse = argparse.ArgumentParser()
parse.add_argument('--init_method', type=str)
parse.add_argument('--rank', type=int)
parse.add_argument('--ws', type=int)
args = parse.parse_args()
if args.init_method == 'TCP':
dist.init_process_group('nccl', init_method='tcp://127.0.0.1:28765', rank=args.rank, world_size=args.ws)
elif args.init_method == 'ENV':
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
print(f"rank = {rank} is initialized")
# 单机多卡情况下,localrank = rank. 严谨应该是local_rank来设置device
torch.cuda.set_device(rank)
tensor = torch.tensor([1, 2, 3, 4]).cuda()
print(tensor)假设单机双卡的机器上运行,则开两个终端,同时运行下面的命令,
# TCP方法
python3 test_ddp.py --init_method=TCP --rank=0 --ws=2
python3 test_ddp.py --init_method=TCP --rank=1 --ws=2
# ENV方法
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=0 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV
MASTER_ADDR='localhost' MASTER_PORT=28765 RANK=1 WORLD_SIZE=2 python3 test_gpu.py --init_method=ENV如果开启的进程未达到word_size 的数量,则所有进程会一直等待,直到都开始运行,可以得到输出如下:
# rank0 的终端:
rank 0 is initialized
tensor([1, 2, 3, 4], device='cuda:0')
# rank1的终端
rank 1 is initialized
tensor([1, 2, 3, 4], device='cuda:1')可以看出,在初始化DDP的时候,能够给后端提供主进程的地址端口、本身的RANK,以及进程数量即可。初始化完成后,就可以执行很多分布式的函数了,比如dist.get_rank, dist.all_gather等等。
B.2 DDP启动方法
上面的例子是最基本的使用方法,需要手动运行多个程序,相对繁琐。实际上本身DDP就是一个python 的多进程,因此完全可以直接通过多进程的方式来启动分布式程序。 torch提供了以下两种启动工具来更加方便的运行torch的DDP程序。
启动方法一:mp.spawn
第一种方法便是使用torch.multiprocessing(python的multiprocessing的封装类) 来自动生成多个进程,使用方法也很简单,先看看基本的调用函数spawn:
mp.spawn(fn, args=(), nprocs=1, join=True, daemon=False)其中:
- fn: 进程的入口函数,该函数的第一个参数会被默认自动加入当前进程的rank, 即实际调用:
fn(rank, *args) - nprocs: 进程数量,即:world_size
- args: 函数fn的其他常规参数以tuple的形式传递
具体看一个例子:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def fn(rank, ws, nums):
dist.init_process_group('nccl', init_method='tcp://127.0.0.1:28765',
rank=rank, world_size=ws)
rank = dist.get_rank()
print(f"rank = {rank} is initialized")
torch.cuda.set_device(rank)
tensor = torch.tensor(nums).cuda()
print(tensor)
if __name__ == "__main__":
ws = 2
mp.spawn(fn, nprocs=ws, args=(ws, [1, 2, 3, 4]))直接执行一次命令python3 test_ddp.py 即可,输出如下:
rank = 0 is initialized
rank = 1 is initialized
tensor([1, 2, 3, 4], device='cuda:1')
tensor([1, 2, 3, 4], device='cuda:0')这种方式同时适用于TCP和ENV初始化。
启动方法二:launch/run
第二种方法则是torch提供的torch.distributed.launch工具,可以以模块的形式直接执行:
python3 -m torch.distributed.launch --配置 train.py --args参数常用配置有:
- --nnodes: 使用的机器数量,单机的话,就默认是1了
- --nproc_per_node: 单机的进程数,即单机的worldsize
- --master_addr/port: 使用的主进程rank0的地址和端口
- --node_rank: 当前的进程rank
在单机情况下, 只有--nproc_per_node 是必须指定的,--master_addr/port和node_rank都是可以由launch通过环境自动配置,举例如下:
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import os
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
local_rank = os.environ['LOCAL_RANK']
master_addr = os.environ['MASTER_ADDR']
master_port = os.environ['MASTER_PORT']
print(f"rank = {rank} is initialized in {master_addr}:{master_port}; local_rank = {local_rank}")
torch.cuda.set_device(rank)
tensor = torch.tensor([1, 2, 3, 4]).cuda()
print(tensor)使用也很方便,通过python3 -m torch.distribued.launch --nproc_per_node=2 test_ddp.py 运行,输出如下:
rank = 0 is initialized in 127.0.0.1:29500; local_rank = 0
rank = 1 is initialized in 127.0.0.1:29500; local_rank = 1
tensor([1, 2, 3, 4], device='cuda:1')
tensor([1, 2, 3, 4], device='cuda:0')torch1.10开始用终端命令torchrun来代替torch.distributed.launch,具体来说,torchrun实现了launch的一个超集,不同的地方在于:
- 完全使用环境变量配置各类参数,如
RANK,LOCAL_RANK, WORLD_SIZE等,尤其是local_rank不再支持用命令行隐式传递的方式 - 能够更加优雅的处理某个worker失败的情况,重启worker。需要代码中有
load_checkpoint(path)和save_checkpoint(path)这样有worker失败的话,可以通过load最新的模型,重启所有的worker接着训练。具体参考imagenet-torchrun - 训练的节点数目可以弹性变化。
同样上面的代码,直接使用torchrun --nproc_per_node=2 test_gpu.py 运行即可,不用写那么长长的命令了。
需要注意的是, torchrun或者launch对上面ENV的初始化方法支持最完善,TCP初始化方法的可能会出现问题,因此尽量使用env来初始化dist。
B.3 DDP模型训练
上面部分介绍了一些细节如何启动分布式训练,接下来介绍如何把单机训练模型的代码改成分布式运行。基本流程如下:
- 分布式训练数据加载。Dataloader需要把所有数据分成N份(N为worldsize), 并能正确的分发到不同的进程中,每个进程可以拿到一个数据的子集,不重叠,不交叉。这部分工作靠 DistributedSampler完成,具体的函数签名如下:
torch.utils.data.distributed.DistributedSampler(dataset,
num_replicas=None, rank=None, shuffle=True, seed=0, drop_last=False)- dataset: 需要加载的完整数据集
- num_replicas: 把数据集分成多少份,默认是当前dist的world_size
- rank: 当前进程的id,默认从dist的rank
- shuffle:是否打乱
- drop_last: 如果数据长度不能被world_size整除,可以考虑是否将剩下的扔掉
- seed:随机数种子。这里需要注意,从源码中可以看出,真正的种子其实是
self.seed+self.epoch这样的好处是,不同的epoch每个进程拿到的数据是不一样,因此需要在每个epoch开始前设置下:sampler.set_epoch(epoch)
其实Sampler的实现也很简单,核心代码就一句:
indices[self.rank: self.total_size: self.num_replicas]假设4卡12条数据的话,rank=0,1,2,3, num_replicas=4, 那么每个卡取的数据索引就是:
rank0: [0 4 8]; rank1: [1 5 9]; rank2: [2 6 10]; rank3: [3 7 11]
保证不重复不交叉。这样在分布式训练的时候,只需要给Dataloader指定DistributedSampler即可,简单示例如下:
sampler = DistributedSampler(dataset)
loader = DataLoader(dataset, sampler=sampler)
for epoch in range(start_epoch, n_epochs):
sampler.set_epoch(epoch) # 设置epoch 更新种子
train(loader)- 模型的分布式训练封装。将单机模型使用
torch.nn.parallel.DistributedDataParallel进行封装,如下:
torch.cuda.set_device(local_rank)
model = Model().cuda()
model = DistributedDataParallel(model, device_ids=[local_rank])
# 要调用model内的函数或者属性. model.module.xxxx这样在多卡训练时,每个进程有一个model副本和optimizer,使用自己的数据进行训练,之后反向传播计算完梯度的时候,所有进程的梯度会进行all-reduce操作进行同步,进而保证每个卡上的模型更新梯度是一样的,模型参数也是一致的。
这里有一个需要注意的地方,在save和load模型时候,为了减小所有进程同时读写磁盘,一般处理方法是以主进程为主,rank0先save模型,在map到其他进程。这样的另外一个好处,在最开始训练时,模型随机初始化之后,保证了所有进程的模型参数保持一致。
【注:其实在torch的DDP封装的时候,已经做到了这一点,即使开始随机初始化不同,经过DDP封装,所有进程都一样的参数】简洁代码如下:
model = DistributedDataParallel(model, device_ids=[local_rank])
CHECKPOINT_PATH ="./model.checkpoint"
if rank == 0:
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
# barrier()其他保证rank 0保存完成
dist.barrier()
map_location = {"cuda:0": f"cuda:{local_rank}"}
model.load_state_dict(torch.load(CHECKPOINT_PATH, map_location=map_location))
# 后面正常训练代码
optimizer = xxx
for epoch:
for data in Dataloader:
model(data)
xxx
# 训练完成 只需要保存rank 0上的即可
# 不需要dist.barrior(), all_reduce 操作保证了同步性
if rank == 0:
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)项目应用可以参考如下代码:
总结一下的话,使用DDP分布式训练的话,一共就如下个步骤:
- 初始化进程组
dist.init_process_group - 如果需要进行小组内集体通信,用
new_group创建子分组; - 设置分布式采样器
DistributedSampler - 使用
DistributedDataParallel封装模型 - 使用
torchrun或者mp.spawn启动分布式训练
补充一点使用分布式做evaluation的时候,一般需要先所有进程的输出结果进行gather,再进行指标的计算,两个常用的函数:
dist.all_gather(tensor_list, tensor): 将所有进程的tensor进行收集并拼接成新的tensorlist返回,比如:dist.all_reduce(tensor, op)这是对tensor的in-place的操作, 对所有进程的某个tensor进行合并操作,op可以是求和等:
import torch
import torch.distributed as dist
dist.init_process_group('nccl', init_method='env://')
rank = dist.get_rank()
torch.cuda.set_device(rank)
tensor = torch.arange(2) + 1 + 2 * rank
tensor = tensor.cuda()
print(f"rank {rank}: {tensor}")
tensor_list = [torch.zeros_like(tensor).cuda() for _ in range(2)]
dist.all_gather(tensor_list, tensor)
print(f"after gather, rank {rank}: tensor_list: {tensor_list}")
dist.barrier()
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print(f"after reduce, rank {rank}: tensor: {tensor}")通过torchrun --nproc_per_node=2 test_ddp.py 输出结果如下:
rank 1: tensor([3, 4], device='cuda:1')
rank 0: tensor([1, 2], device='cuda:0')
after gather, rank 1: tensor_list: [tensor([1, 2], device='cuda:1'), tensor([3, 4], device='cuda:1')]
after gather, rank 0: tensor_list: [tensor([1, 2], device='cuda:0'), tensor([3, 4], device='cuda:0')]
after reduce, rank 0: tensor: tensor([4, 6], device='cuda:0')
after reduce, rank 1: tensor: tensor([4, 6], device='cuda:1')在evaluation的时候,可以拿到所有进程中模型的输出,最后统一计算指标,基本流程如下:
pred_list = []
for data in Dataloader:
pred = model(data)
batch_pred = [torch.zeros_like(label) for _ in range(world_size)]
dist.all_gather(batch_pred, pred)
pred_list.extend(batch_pred)
pred_list = torch.cat(pred_list, 1)
# 所有进程pred_list是一致的,保存所有数据模型预测的值(3)实现多GPU多进程并行训练的两种方式
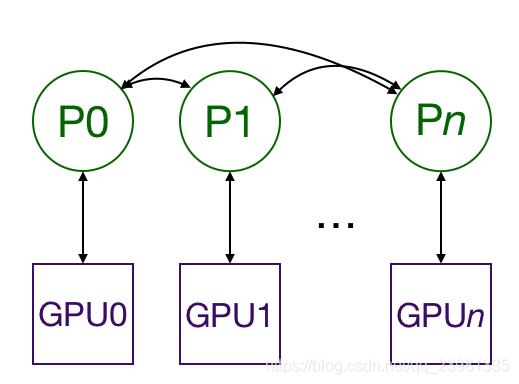
方法一:
首先是Pytorch自带的分布式APIDistributedDataParallel (见上小节):
import argparse
parse = argparse.ArgumentParser()
# 在训练的开始要设置一个叫local_rank的参数到环境变量中,local_rank代表当前程序进程使用的GPU标号,用argparse模块。
# 当使用分布式训练时Pytorch会开多进程,这个参数负责表示具体进程。
# 通常我们只需要其中一个进程输出结果就可以了。
parse.add_argument('--local_rank', type=int, default=0)
args = parse.parse_args()
local_rank = args.local_rank
# 设置并初始化环境,后端通常用nccl就可以。
torch.cuda.set_device(local_rank)
torch.distributed.init_process_group(backend="nccl", init_method='env://')
device = torch.device("cuda:{}".format(local_rank))
# 加载数据集,注意加载如DataLoader时,要使用分布式sampler的API,然后把shuffle设置为False。
# 具体对训练数据shuffle操作放到了每一轮中额外设置。
# 开启pin_memory是方便后续做数据IO的加速,用到Pytorch自带的一些性质。
# 通常不是数据IO不是瓶颈时用这个就足够
traindataset = train_set()
from torch.utils.data.distributed import DistributedSampler
from torch.utils import data
datasampler = DistributedSampler(dataset=traindataset)
trainloader = data.DataLoader(traindataset, sampler=datasampler, batch_size=xxx, shuffle=False,
pin_memory=True, num_workers=xxx)上述的步骤要求需要多个进程,甚至可能是不同结点上的多个进程同步和通信。而Pytorch通过它的distributed.init_process_group 函数实现。这个函数需要知道如何找到进程0(process 0),一边所有的进程都可以同步,也知道了一共要同步多少进程。每个独立的进程也要知道总共的进程数,以及自己在所有进程中的阶序(rank),当然也要知道自己要用那张GPU。总进程数称之为 world size。最后,每个进程都需要知道要处理的数据的哪一部分,这样批处理就不会重叠。而Pytorch通过nn.utils.data.DistributedSampler 来实现这种效果。
以上是环境初始化以及数据读取部分的设置,无论使用apex还是Pytorch自带的分布式API,上面都是必须做的。
方法二:
以下模型读取的话,Pytorch的API和apex有所不同,主要是Apex不仅可以分布式训练,还可以使用混合精度模式以及同步bn(Sync-BN)。参考代码:
from apex.parallel import DistributedDataParallel as DDP
from apex.parallel import convert_syncbn_model, SyncBatchNorm
from apex.fp16_utils import *
from apex import amp, optimizers
from apex.multi_tensor_apply import multi_tensor_applier
model = XXXNet()
model.train()
model.to(device) # device是上面设置好的device。
# Sync-BatchNorm
# 使用apex自带的同步BN层。
# 调用函数后会自动遍历model的层,将Batchnorm层替换。
model = convert_syncbn_model(model)
optimizer = optim.SGD(model.parameters(), lr=.., decay=.., ...)
# 用于记录训练过程中的loss变化。
def reduce_tensor(tensor, world_size=1):
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
tensor /= world_size
return tensor
# 通过调整下面的opt_level实现半精度训练。
# opt_level选项有:'O0', 'O1', 'O2', 'O3'.
# 其中'O0'是fp32常规训练,'O1'、'O2'是fp16训练,'O3'则可以用来推断但不适合拿来训练(不稳定)
# 注意,当选用fp16模式进行训练时,keep_batchnorm默认是None,无需设置;
# scale_loss是动态模式,可以设置也可以不设置。
model, optimizer = amp.initialize(model, optimizer, opt_level=opt_level,
keep_batchnorm_fp32=keep_bn_32, scale_loss=scale_loss)
'''这里可以使用了两种方法进行分布式训练'''
# 方法一:Pytorch自带的分布式API
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank])
#方法二:Apex的分布式API
model = DDP(model)
# 训练过程中:
while training:
output = model(input)
loss = criterion(output, target)
# 方便记录损失下降
log_loss = reduce_tensor(log_loss.clone().detach_())
optimizer.zero_grad()
# 假如设置了fp16训练模式,则要将反传过程替换为以下。
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()关于模型保存和重用:
# Save checkpoint
# 注意,在保存权重时要注意判断local_rank。
# 因为是多进程任务,假如多个进程同时写同一个文件在同一个地址会损坏文件。
# 通常是local_rank 为默认值时保存权重,由于多个进程之间的保持GPU通信,所以每个进程的权重都是一样的。
if local_rank == 0:
checkpoint = {
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'amp': amp.state_dict()
}
torch.save(checkpoint, 'amp_checkpoint.pt')
...
# 模型重用,把权重放在‘cpu’模式上,然后读取,再设置分布式。
net = XXXNet()
net.train()
resume = 'XXXNet.pth'
checkpoint = torch.load(resume, map_location='cpu') # CPU mode
net.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
model, optimizer = amp.initialize(model, optimizer, opt_level=opt_level)
amp.load_state_dict(checkpoint['amp'])注意,由于我自己还没有尝试过模型重用,所以具体流程还不是特别清楚,所以这里遇到什么问题可以交流下。
最后一步就是开启训练:
# 在终端输入:
NCCL_DEBUG=INFO CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 train.py
# NCCL_DEBUG=INFO 表示打印nccl初始化信息,可选,用于debug。
# CUDA_VISIBLE_DEVICES=0,1 用来指定训练用GPU
# python -m torch.distributed.launch 必须加,用来初始化local_rank到每一个进程
# --nproc_per_node=2 通常一台机器上用多少GPU就设置多少,每个GPU在一个进程上效率较好。二、使用Apex进行混合混合精度训练
混合精度训练,即组合浮点数 (FP32)和半精度浮点数 (FP16)进行训练,允许我们使用更大的batchsize,并利用NVIDIA张量核进行更快的计算。
实例代码:
【注明:每个node指一台机器】
import os
from datetime import datetime
import argparse
import torch.multiprocessing as mp
import torchvision
import torchvision.transforms as transforms
import torch
import torch.nn as nn
import torch.distributed as dist
from apex.parallel import DistributedDataParallel as DDP
from apex import amp
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N',
help='number of data loading workers (default: 4)')#args.nodes 是我们使用的结点数
parser.add_argument('-g', '--gpus', default=1, type=int,
help='number of gpus per node') #args.gpus 是每个结点的GPU数.
parser.add_argument('-nr', '--nr', default=0, type=int,
help='ranking within the nodes')#args.nr 是当前结点的阶序rank,这个值的取值范围是 0 到 args.nodes - 1.
parser.add_argument('--epochs', default=2, type=int, metavar='N',
help='number of total epochs to run')
args = parser.parse_args()
args.world_size = args.gpus * args.nodes #基于结点数以及每个结点的GPU数,我们可以计算 world_size 或者需要运行的总进程数,这和总GPU数相等。
os.environ['MASTER_ADDR'] = 'localhost' #告诉Multiprocessing模块去哪个IP地址找process 0以确保初始同步所有进程。
os.environ['MASTER_PORT'] = '8888'#同样的,这个是process 0所在的端口
mp.spawn(train, nprocs=args.gpus, args=(args,)) #我们需要生成 args.gpus 个进程, 每个进程都运行 train(i, args), 其中 i 从 0 到 args.gpus - 1。注意, main() 在每个结点上都运行, 因此总共就有 args.nodes * args.gpus = args.world_size 个进程.
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
def train(gpu, args):
rank = args.nr * args.gpus + gpu
dist.init_process_group(
backend='nccl',
init_method='env://',
world_size=args.world_size,
rank=rank)
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Wrap the model
##############################################################
model, optimizer = amp.initialize(model, optimizer,
opt_level='O2')
model = DDP(model)
##############################################################
# Data loading code
train_dataset = torchvision.datasets.MNIST(
root='./data',
train=True,
transform=transforms.ToTensor(),
download=True
)
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=args.world_size,
rank=rank)
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=0,
pin_memory=True,
sampler=train_sampler
)
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
labels = labels.cuda(non_blocking=True)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
##############################################################
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
##############################################################
optimizer.step()
if (i + 1) % 100 == 0 and gpu == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(
epoch + 1,
args.epochs,
i + 1,
total_step,
loss.item())
)
if gpu == 0:
print("Training complete in: " + str(datetime.now() - start))
if __name__ == '__main__':
main()重要代码为:
(1)
##############################################################
model, optimizer = amp.initialize(model, optimizer,
opt_level='O2')
model = DDP(model)
##############################################################- amp.initialize 将模型和优化器为了进行后续混合精度训练而进行封装。注意,在调用amp.initialize 之前,模型模型必须已经部署在GPU上。 opt_level 从 O0 (全部使用浮点数)一直到 O3 (全部使用半精度浮点数)。而 O1 和 O2 属于不同的混合精度程度,具体可以参阅APEX的官方文档。注意之前数字前面的是大写字母O。
- apex.parallel.DistributedDataParallel (DDP)是一个 nn.DistributedDataParallel 的替换版本。我们不需要指定GPU,因为Apex在一个进程中只允许用一个GPU。且它也假设程序在把模型搬到GPU之前已经调用了 torch.cuda.set_device(local_rank).
(2)
##############################################################
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
##############################################################混合精度训练需要缩放损失函数以阻止梯度出现下溢。不过Apex会自动进行这些工作。
运行方式:
- 要在4个结点上运行它(每个结点上有8个gpu),我们需要4个终端(每个结点上有一个)。在结点0上:
python src/mnist-distributed.py -n 4 -g 8 -nr 0- 而在其他的结点上:
python src/mnist-distributed.py -n 4 -g 8 -nr i其中 i∈1,2,3. 换句话说,我们要把这个脚本在每个结点上运行脚本,让脚本运行 args.gpus 个进程以在训练开始之前同步每个进程。
注意:脚本中的batchsize设置的是每个GPU的batchsize,因此实际的batchsize要乘上总共的GPU数目(worldsize)。
多GPU分布式并行训练+混合精度加速训练
对应上面开源链接的train_distributed.py脚本。相信最直接的代码以及注释就是最好的说明。该脚本同时包含了最常用的代码模版,包括例如多进程的训练数据准备,模型权重的保存与载入、冻结部分网络层的权重、变相增加batch size、使用Nvidia官方的Apex包通过半精度或混合精度进行模型压缩和加速等等。
import os
import argparse
import time
import tqdm
import cv2
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import apex.optimizers as apex_optim
import torch.distributed as dist
from config.config import GetConfig, COCOSourceConfig, TrainingOpt
from data.mydataset import MyDataset
from torch.utils.data.dataloader import DataLoader
from models.posenet import Network
from models.loss_model import MultiTaskLoss
import warnings
try:
import apex.optimizers as apex_optim
from apex.parallel import DistributedDataParallel as DDP
from apex.fp16_utils import *
from apex import amp #AMP: Automatic Mixed Precision 自动混合精度包
from apex.multi_tensor_apply import multi_tensor_applier
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to run this example.")
warnings.filterwarnings("ignore")
parser = argparse.ArgumentParser(description='PoseNet Training')
parser.add_argument('--resume', '-r', action='store_true', default=True, help='resume from checkpoint')
parser.add_argument('--freeze', action='store_true', default=False,
help='freeze the pre-trained layers before output layers')
parser.add_argument('--warmup', action='store_true', default=True, help='using warm-up learning rate')
parser.add_argument('--checkpoint_path', '-p', default='link2checkpoints_distributed', help='save path')
parser.add_argument('--max_grad_norm', default=10, type=float,
help=("If the norm of the gradient vector exceeds this, "
"re-normalize it to have the norm equal to max_grad_norm"))
# FOR DISTRIBUTED: Parse for the local_rank argument, which will be supplied automatically by torch.distributed.launch.
parser.add_argument("--local_rank", default=0, type=int) #local_rank代表当前程序进程使用的GPU标号:args.gpu = args.local_rank,torch.cuda.set_device(args.gpu)
parser.add_argument('--opt-level', type=str, default='O1')
'''其中的opt-level参数是用户指定采用何种数据格式做训练的。
O0:纯FP32训练,可以作为accuracy的baseline;
O1:混合精度训练(推荐使用),根据黑白名单自动决定使用FP16(GEMM, 卷积)还是FP32(Softmax)进行计算。
O2:“几乎FP16”混合精度训练,不存在黑白名单,除了Batch norm,几乎都是用FP16计算。
O3:纯FP16训练,很不稳定,但是可以作为speed的baseline;
'''
parser.add_argument('--sync_bn', action='store_true', default=True,
help='enabling apex sync BN.') # 设置是否跨卡同步BN,无触发为false, -s 触发为true
parser.add_argument('--keep-batchnorm-fp32', type=str, default=None)
parser.add_argument('--loss-scale', type=str, default=None) # '1.0'
parser.add_argument('--print-freq', '-f', default=10, type=int, metavar='N', help='print frequency (default: 10)')
# ##############################################################################################################
# ################################### Setup for some configurations ###########################################
# ##############################################################################################################
torch.backends.cudnn.benchmark = True # 如果我们每次训练的输入数据的size不变,那么开启这个就会加快我们的训练速度
use_cuda = torch.cuda.is_available()
args = parser.parse_args()
checkpoint_path = args.checkpoint_path
opt = TrainingOpt()
config = GetConfig(opt.config_name)
soureconfig = COCOSourceConfig(opt.hdf5_train_data) # # 对于分布式训练,total_batch size = batch_size*world_size
train_data = MyDataset(config, soureconfig, shuffle=False, augment=True) # shuffle in data loader
soureconfig_val = COCOSourceConfig(opt.hdf5_val_data)
val_data = MyDataset(config, soureconfig_val, shuffle=False, augment=False) # shuffle in data loader
best_loss = float('inf')
start_epoch = 0 # 从0开始或者从上一个epoch开始
args.distributed = False
if 'WORLD_SIZE' in os.environ:
args.distributed = int(os.environ['WORLD_SIZE']) > 1
args.gpu = 0
args.world_size = 1
# FOR DISTRIBUTED: If we are running under torch.distributed.launch,
# the 'WORLD_SIZE' environment variable will also be set automatically.
if args.distributed:
args.gpu = args.local_rank
torch.cuda.set_device(args.gpu)