摘要:我发现,凡是涉及到大数据存储,好像都得有个横向扩容方案,不管是在应用层实现,还是在数据存储本身实现。Redis作为一个高效的数据缓存,也周到的提供了数据sharding特性,本文就先讲下最基础的东西:什么是redis的sharding以及如何搭建redis cluster,欢迎大家关注我的微信公众号虾米兵法(sammytalk)和我一起讨论。
简单介绍数据分片模型
所谓数据分片,就是将所存储的数据按照一定的规则存储在不同的存储服务/介质上,通过降低单服务/介质的数据量级来提升数据处理效能,从而达到拥有数据处理横向扩容的能力的目的。
这样说貌似有点抽象,我们通过一个例子简单看下。有一个数据主存储器拥来存储每天的订单,随着时间的推移,数据量级不断扩大,因为机器硬件能力有限,必然造成数据存储性能的衰减,如果应用层的容错机制设计不合理,很容易造成整个服务的性能下降。
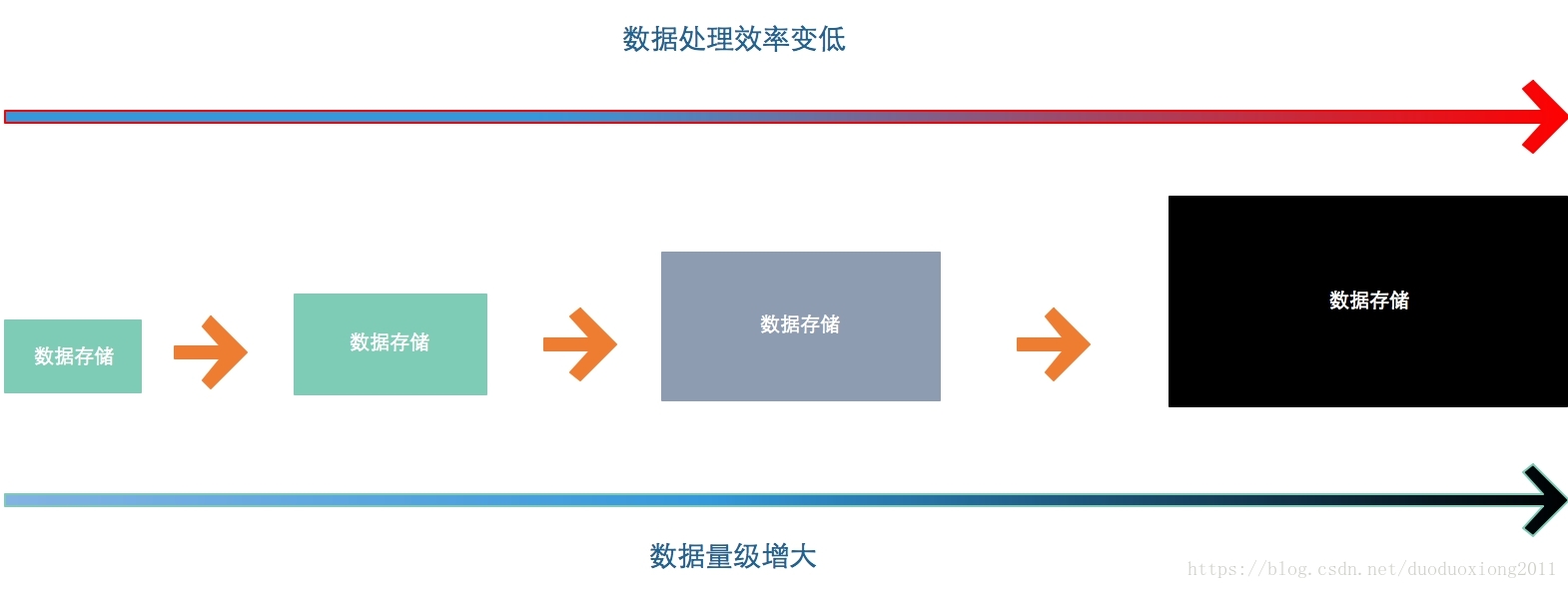
要解决这个问题,除了加强硬件配置以外,还可以通过增加节点,将数据全集拆分成一个个的小数据集合进行存储的方式来解决。那么拆分以后,数据该如何存储?如何读取?如何迁移数据呢?这里就需要一个数据分布规则方案来支撑。通过这种方式,每个数据节点都可以将数据集保持在一定大小范围,从而保持一定都数据处理效率,而应对数据增长采用增加节点都方式来进行,当然数据分布规则和(数据-节点)的获取方式成为影响效率的关键,如果处理不好,非常可能将耗时集中在节点查找及数据合并处理上。

redis如何实现数据分片
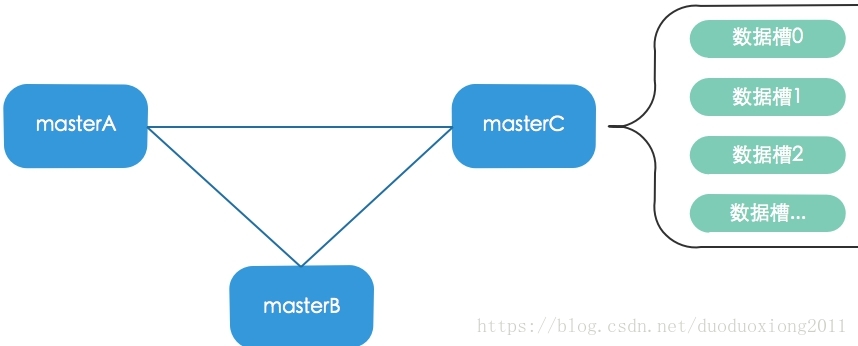
Redis至少存在三个数据分片,每个分片称为master,分片之前的关系为完全图,假设整个cluster有N个节点,那么每个节点都和其他N-1个节点保持连接和心跳,节点之间采用Gossip协议进行通信。通信主要确认节点是否存活、节点的数据版本、投票选择新的master等内容。
Redis的数据如何分布在分片上呢?Redis内部被固定划分为16384个槽(slot),每个数据都会被存储在指定都槽内,当用户put一个key时,redis会调用crc16函数然后与0x3FFF进行&运算确定数据存储的槽位,当数据正确存储后,通过Gossip协议向其他节点广播该数据当位置,所以redis没有中心路由的概念,所有节点都知道数据-节点都路由信息。
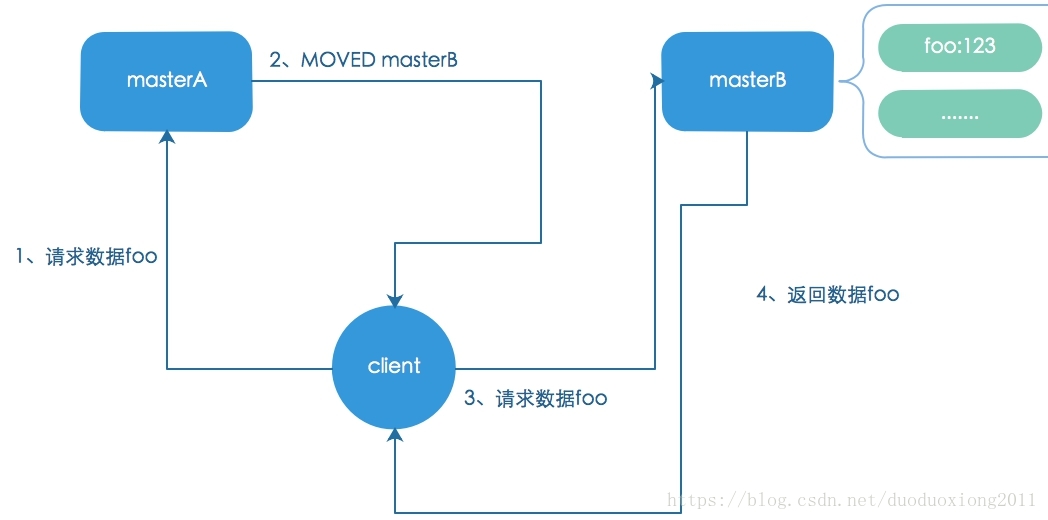
既然没有中心路由,客户端在一开获取/更新数据的时候是随机对master节点进行访问,如果数据经过计算是在该节点上,那么存取没有问题,否则会返回一个MOVED异常(slot没有正在移动过程中),客户端需要重新指向正确的节点对数据进行处理,当然客户端最好能缓存数据与节点的对应关系,提升数据访问或者更新速度。
Redis分片对通讯机制东西很多,这里初步介绍一下,详细对在后面的文章中具体介绍。
开始动手搭建redis cluster
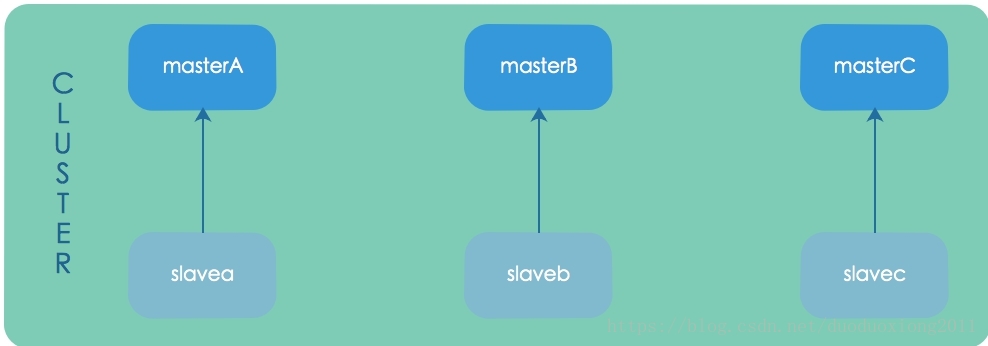
在此实战小结里,我将一步步的搭建一个分片集群(如下图),包括3个master节点和3个slave节点(每个master节点有1个slave节点)。
首先准备6台Linux服务器(我安装的是Centos7.2)。
在每台服务器上安装redis服务,具体如下:
#下载redis4.0.8
wget http://download.redis.io/releases/redis-4.0.8.tar.gz#解压安装包
tar xzvf redis-4.0.8.tar.gz#安装GCC
yum -y install gcc#进入redis目录
cd redis-4.0.8#编译redis源码
make MALLOC=libc#安装redis
make install所有的服务安装好之后,开始修改src文件夹下的配置文件redis.conf,修改如下几项(最小配置):
#端口分别设置为10000~10005
port10000#开启cluster
cluster-enabled yes#clusetr的配置文件名,保存节点相关的信息#自动创建,内容无需手工修改
cluster-config-file nodes.conf#节点fail的超时时间
cluster-node-timeout3000#开始aof文件持久化
appendonly yes#绑定监听的ip地址,写物理ip地址
bind xx.xx.xx.xx选择一台机器安装ruby运行环境,因为redis的集群管理工具redis-trib.rb需要ruby运行环境。
gpg --keyserver hkp://keys.gnupg.net --recv-keys409B6B1796C275462A1703113804BB82D39DC0E37D2BAF1CF37B13E2069D6956105BD0E739499BDB
curl -sSL https://get.rvm.io | bash -s stable以上步骤是安装rvm管理器,安装成功后会有如下提示:
- To start using RVM you need to run
source /etc/profile.d/rvm.sh
in all your open shell windows, in rare cases you need to reopen all shell windows.
执行提示语句,并安装ruby2.4.2:
source /etc/profile.d/rvm.sh
rvminstall2.4.2
geminstall redis --version3.0.0启动redis服务
redis-server redis.confg &创建redis分片集群
随便选择一台服务器,进入redis安装目录的src目录,执行如下命令:
./redis-trib.rbcreate--replicas 1 ip1:port1 ip2:port2其中ip和port就是redis的ip和端口,–replicas 1表示为每个master生成一个slave节点。
执行后,redis会生成集群创建计划,输入yes,回车,直到看到如下信息,redis集群就创建完毕了。
[OK] All 16384 slots covered.
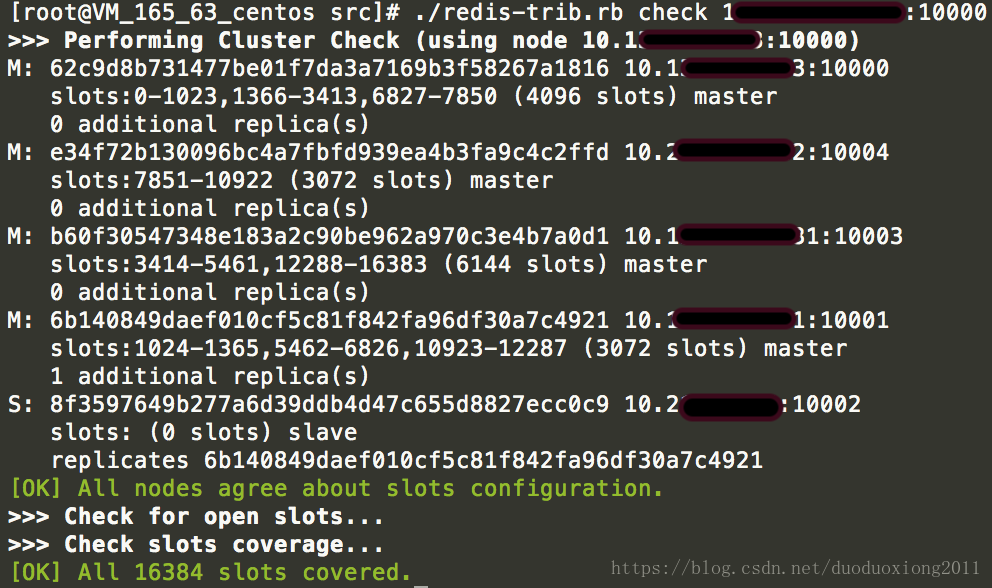
运行如下命令检查集群状态
./redis-trib.rbcheck ip:portip和port为任意一个redis的ip和端口,可以看到输出的集群信息,包括节点的id、地址、负责的槽区范围、主/从节点角色信息。如果是从节点,还会显示主节点的id。
后续
Redis分片集群还有很多东西可以分享,本文初步介绍了下基本概念和基本的安装过程,不过我认为:虽然redis支持分片,但是redis并不保证的数据的完全一致性,所以,在使用redis分片的过程中,请把它当成一个锦上添花的工具,不要过分依赖,设计好强大的应用层的数据保障机制才是王道。本文就到这里,如有错误,欢迎指正。