在pytorch上使用多个GPU(在同一台设备上,并非分布式)进行训练是件非常容易的事情,只要在源代码中添加(修改)两行代码即可。下面贴上官方教程给的示例代码。并在文末总结一些自己在使用多GPU实验时发现的问题。
官方tutorial
把模型放在GPU上:
device= torch.device("cuda:0")
model.to(device)将tensor复制到GPU上
mytensor= my_tensor.to(device)请注意,调用my_tensor.to(device)会在GPU上返回一个新的my_tensor副本,而不是重写my_tensor。你需要给它分配一个新的张量,然后在GPU上使用这个张量。
Pytorch默认情况下只使用一个GPU。想用多GPU同时训练,只需下面一步简单的操作:使用模块DataParallel,你就可以很容易地在多个gpu上运行你的操作:
model= nn.DataParallel(model)上面这行代码就是本教程的核心。
(注意:有时候只使用上面这一行代码还不能实现多gpu训练,会报错,文末会给解决办法)
官方示例代码
import torchimport torch.nnas nnfrom torch.utils.dataimport Dataset, DataLoaderimport os
os.environ['CUDA_VISIBLE_DEVICES']='2,3'# 这里输入你的GPU_id# Parameters and DataLoaders
input_size=5
output_size=2
batch_size=30
data_size=100
device= torch.device("cuda:0"if torch.cuda.is_available()else"cpu")# Dummy DataSetclassRandomDataset(Dataset):def__init__(self, size, length):
self.len= length
self.data= torch.randn(length, size)def__getitem__(self, index):return self.data[index]def__len__(self):return self.len
rand_loader= DataLoader(dataset=RandomDataset(input_size, data_size),
batch_size=batch_size, shuffle=True)# Simple ModelclassModel(nn.Module):# Our modeldef__init__(self, input_size, output_size):super(Model, self).__init__()
self.fc= nn.Linear(input_size, output_size)defforward(self,input):
output= self.fc(input)print("\tIn Model: input size",input.size(),"output size", output.size())return output# Create Model and DataParallel
model= Model(input_size, output_size)if torch.cuda.device_count()>1:print("Let's use", torch.cuda.device_count(),"GPUs!")# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
model= nn.DataParallel(model)
model.to(device)#Run the Modelfor datain rand_loader:input= data.to(device)
output= model(input)print("Outside: input size",input.size(),"output_size", output.size())运行上面代码,会在控制台打印出:
Let's use 2 GPUs!
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])
In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])闲来无事可以跑一下,感受一下官方的多GPU训练。
最近在尝试使用多GPU训练的时候,遇到了一些问题,记录下来留作以后参考,也给遇到同样问题的朋友做参考。
问题一:
按照官方教程设置,即model = nn.DataParallel(model),运行后报错:
TypeError:Broadcast function not implemented for CPU tensors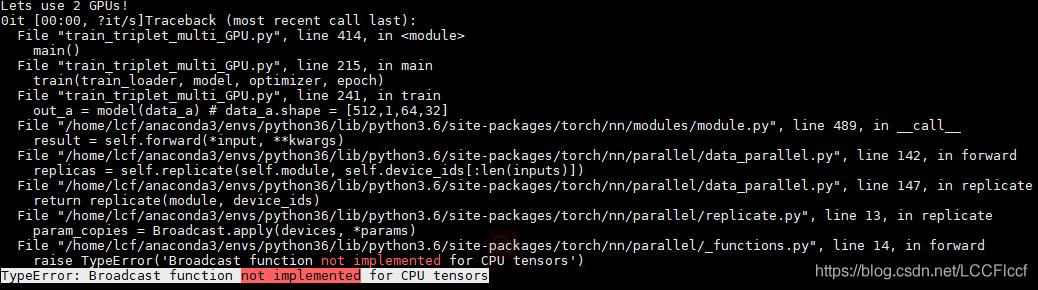
网上求解,发现原因是使用DataParallel()前没把model转为cuda模式,因此报这个错误。
解决方案:
修改为:
model= nn.DataParallel(model.cuda())参考:https://discuss.pytorch.org/t/broadcast-function-not-implemented-for-cpu-tensors/9893
问题二:
报如下错误:
AttributeError: 'DataParallel' object has no attribute 'forward_classifier'
类似这样的问题“AttributeError: ‘DataParallel’ object has no attribute ‘xxx’”,解决办法为先在dataparallel后的model调用module模块,然后再调用xxx。在使用了DataParallel之后,有这样的关系:model.xxx = nn.DataParallel.module.xxx
报错的代码为:
cls_a= model.forward_classifier(selected_data_a)解决方案
将其修改为如下即可解决问题:
cls_a= model.module.forward_classifier(selected_data_a)此问题参考:https://discuss.pytorch.org/t/fine-tuning-resnet-dataparallel-object-has-no-attribute-fc/14842