1 DataParallel
据说存在多个GPU之间显存不均衡的问题,因此我直接选择了pytorch所建议的DistributedDataParallel,为多机多卡设计,但同时也可以实现单机多卡,能够使得各个GPU之间负载均衡。
2 DistributedDataParallel
现在的DistributedDataParallel是基于多进程策略的多GPU训练方式。首先是单机多卡的方式上,针对每个GPU,启动一个进程,然后这些进程在最开始的时候会保持一致,同时在更新模型的时候,梯度传播也是完全一致的,这样就可以保证任何一个GPU上面的模型参数就是完全一致的,所以这样就不会出现DataParallel那样的显存不均衡的问题。
引自知乎:https://zhuanlan.zhihu.com/p/86441879
2.1 程序中设置
- 1 首先设置程序可见的GPU设备列表:
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0,1,2,3"注意:一定要将其设置在所有访问cuda的语句之前,否则会失效。建议import os后就设置,因为import的文件中可能也有访问cuda的操作。或者在启动程序的命令行中设置,见下文。
- 2 初始化使用nccl后端:(这是什么我也不太懂 反正就这么用的)
if torch.cuda.device_count()>1:print("Let's use", torch.cuda.device_count(),"GPUs!")
torch.distributed.init_process_group(backend="nccl")- 3 如果程序中设置了argparse的话,则一定要添加
--local_rank参数,以接收每个进程的rank值。
具体设置如下:
parser.add_argument('--local_rank',type=int, default=-1)
opt= parser.parse_args()- 4 而后为每个进程设置其device:
torch.cuda.set_device(opt.local_rank)
device= torch.device("cuda", opt.local_rank)- 5 DistributedDataParallel并不会自动分配数据。如果使用Dataset类的话,构建DataLoader的时候需要使用sampler对其进行采样并分配,具体如下:
train_sampler= DistributedSampler(train_dataset)
train_loader= DataLoader(train_dataset, opt.batch_size, shuffle=False, collate_fn=my_collate, sampler=train_sampler)注意:shuffle需要设置为False,其和samlper互斥,否则会出现ValueError: sampler option is mutually exclusive with shuffle的问题。查阅pytorch文档可知,DistributedSampler中的shuffle属性默认为True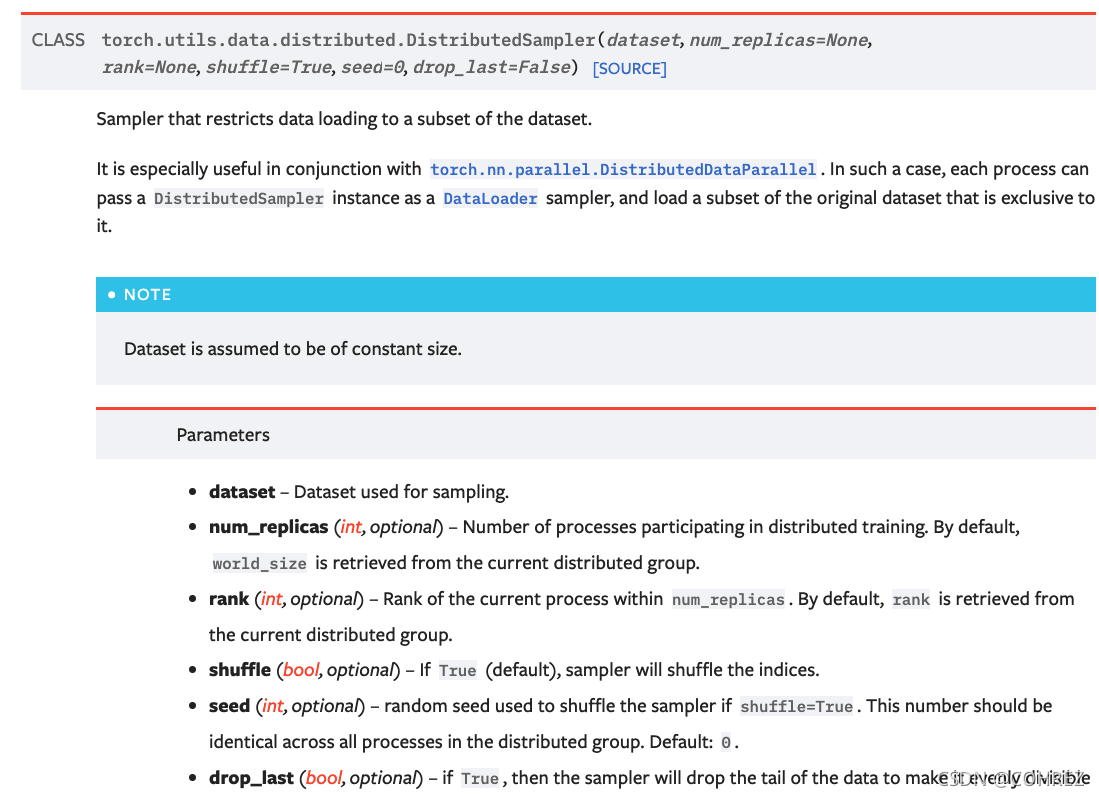
- 6 加载模型,并将其放到GPU上:
model= Model()
model= model.to(device)- 7 模型并行:
model= DistributedDataParallel(model,device_ids=[opt.local_rank], output_device=opt.local_rank, find_unused_parameters=True)注意:如果存在下述情况:
用过DDP都知道,如果有forward的返回值如果不在计算loss的计算图里,那么需要find_unused_parameters=True,即返回值不进入backward去算grad,也不需要在不同进程之间进行通信。
引自知乎:https://www.zhihu.com/question/67209417/answer/850135688
(我的理解的就是模型有部分参数是不需要更新的,比如embedding),应设置find_unused_parameters为True,否则报错如下:
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that
your module has parameters that were not used in producing loss. You can enable unused parameter detection by (1)
passing the keyword argument find_unused_parameters=True to torch.nn.parallel.DistributedDataParallel; (2) making
sure all forward function outputs participate in calculating loss. If you already have done the above two steps, then the
distributed data parallel module wasn’t able to locate the output tensors in the return value of your module’s forward
function. Please include the loss function and the structure of the return value of forward of your module when reporting
this issue (e.g. list, dict, iterable). (prepare_for_backward at /opt/conda/conda-2.2 程序启动
设置完初始化、device、DataLoader以及model后,启动程序如下:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 train.py注意:
1 如果程序中已经设置过CUDA_VISIBLE_DEVICES,则可以省略
2--nproc_per_node值与GPU个数保持一致(每个GPU上一个进程)
3 其他注意事项
RuntimeError: Input and parameter tensors are not at the same device
问题原因:前文只降Dataloader中的输入数据放入到了device中,而模型中其他另外初始化的数据,例如LSTM中的h0和c0,应一并.to(device)
4 参考资源
【知乎】pytorch多gpu并行训练链接:https://zhuanlan.zhihu.com/p/86441879.
【知乎】【分布式训练】单机多卡的正确打开方式(三):PyTorch:https://zhuanlan.zhihu.com/p/74792767?utm_source=wechat_session&utm_medium=social&utm_oi=1015947654509039616.
5 写在后面
博主还是个菜鸡,门还没入,理解太浅,有问题的话欢迎提出,互相学习!
(此篇后续还会随着理解的深入和实践的累积继续更新。