在互联网出现之前,“抄”很不方便,一是“源”少,而是发布渠道少;而在互联网出现之后,“抄”变得很简单,铺天盖地的“源”源源不断,发布渠道也数不胜数,博客论坛甚至是自建网站,而爬虫还可以让“抄”完全自动化不费劲。这就导致了互联网上的“文章”重复性很高。这里的“文章”只新闻、博客等文字占据绝大部分内容的网页。
中文新闻网站的“转载”(其实就是抄)现象非常严重,这种“转载”几乎是全文照抄,或改下标题,或是改下编辑姓名,或是文字个别字修改。所以,对新闻网页的去重很有必要。
一、去重算法原理
文章去重(或叫网页去重)是根据文章(或网页)的文字内容来判断多个文章之间是否重复。这是爬虫爬取大量的文本行网页(新闻网页、博客网页等)后要进行的非常重要的一项操作,也是搜索引擎非常关心的一个问题。搜索引擎中抓取的网页是海量的,海量文本的去重算法也出现了很多,比如minihash, simhash等等。
在工程实践中,对simhash使用了很长一段时间,有些缺点,一是算法比较复杂、效率较差;二是准确率一般。
网上也流传着百度采用的一种方法,用文章最长句子的hash值作为文章的标识,hash相同的文章(网页)就认为其内容一样,是重复的文章(网页)。
这个所谓的“百度算法”对工程很友好,但是实际中还是会有很多问题。中文网页的一大特点就是“天下文章一大抄”,各种博文、新闻几乎一字不改或稍作修改就被网站发表了。这个特点,很适合这个“百度算法”。但是,实际中个别字的修改,会导致被转载的最长的那句话不一样,从而其hash值也不一样了,最终结果是,准确率很高,召回率较低。
为了解决这个问题,我提出了nshash(top-n longest sentences hash)算法,即:取文章的最长n句话(实践下来,n=5效果不错)分别做hash值,这n个hash值作为文章的指纹,就像是人的5个手指的指纹,每个指纹都可以唯一确认文章的唯一性。这是对“百度算法”的延伸,准确率还是很高,但是召回率大大提高,原先一个指纹来确定,现在有n个指纹来招回了。
二、算法实现
该算法的原理简单,实现起来也不难。比较复杂一点的是对于一篇文章(网页)返回一个similar_id,只要该ID相同则文章相似,通过groupby similar_id即可达到去重目的。
为了记录文章指纹和similar_id的关系,我们需要一个key-value数据库,本算法实现了内存和硬盘两种key-value数据库类来记录这种关系:
HashDBLeveldb 类:基于leveldb实现, 可用于海量文本的去重;
HashDBMemory 类:基于Python的dict实现,可用于中等数量(只要Python的dict不报内存错误)的文本去重。
这两个类都具有get()和put()两个方法,如果你想用Redis或MySQL等其它数据库来实现HashDB,可以参照这两个类的实现进行实现。
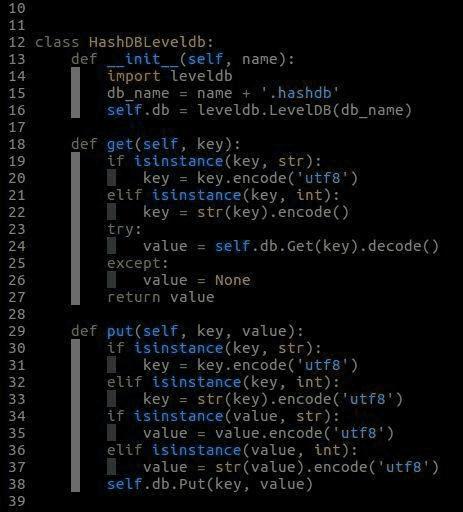
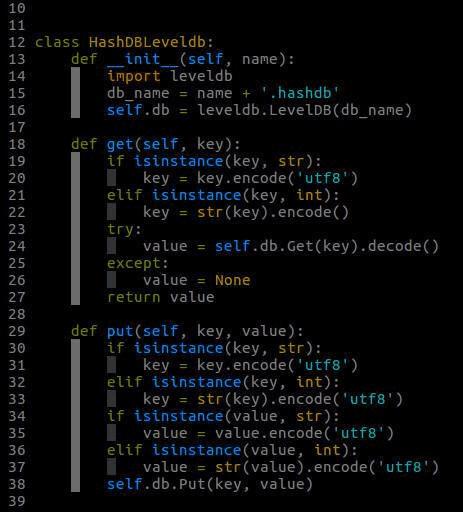
HashDBLeveldb类的实现
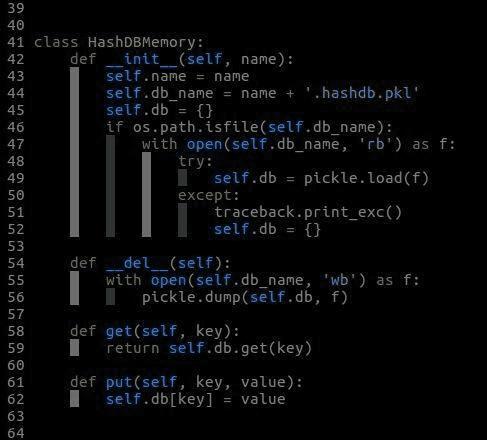
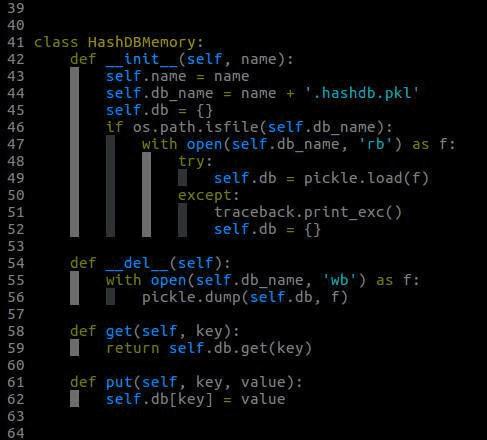
HashDBMemory类的实现
从效率上看,肯定是HashDBMemory速度更快。利用nshash对17400篇新闻网页内容的测试结果如下:
HashDBLeveldb: 耗时2.47秒; HashDBMemory: 耗时1.6秒;
具体测试代码请看 example/test.py。
有了这两个类,就可以实现nshash的核心算法了。
首先,对文本进行分句,以句号、感叹号、问号、换行符作为句子的结尾标识,一个正在表达式就可以分好句了。
其次,挑选最长的n句话,分别进行hash计算。hash函数可以用Python自带模块hashlib中的md5, sha等等,也可以用我在爬虫教程中多次提到的farmhash。
最后,我们需要根据这n个hash值给文本内容一个similar_id,通过上面两种HashDB的类的任意一种都可以比较容易实现。其原理就是,similar_id从0开始,从HashDB中查找这n个hash值是否有对应的similar_id,如果有就返回这个对应的similar_id;如果没有,就让当前similar_id加1作为这n个hash值对应的similar_id,将这种对应关系存入HashDB,并返回该similar_id即可。
这个算法实现为NSHash类:
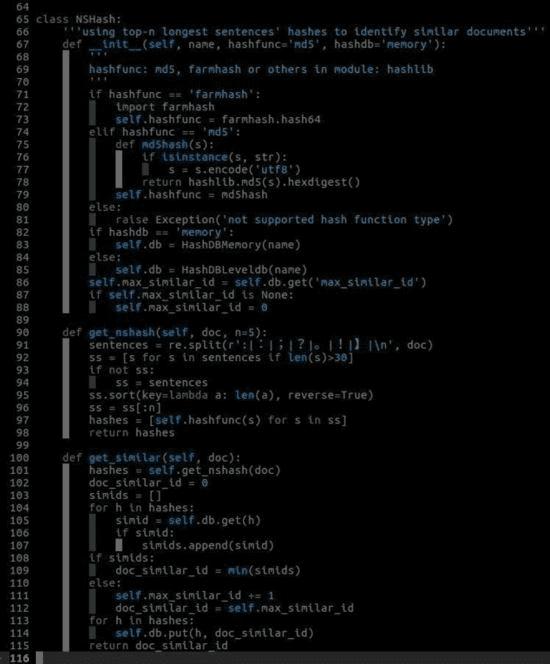
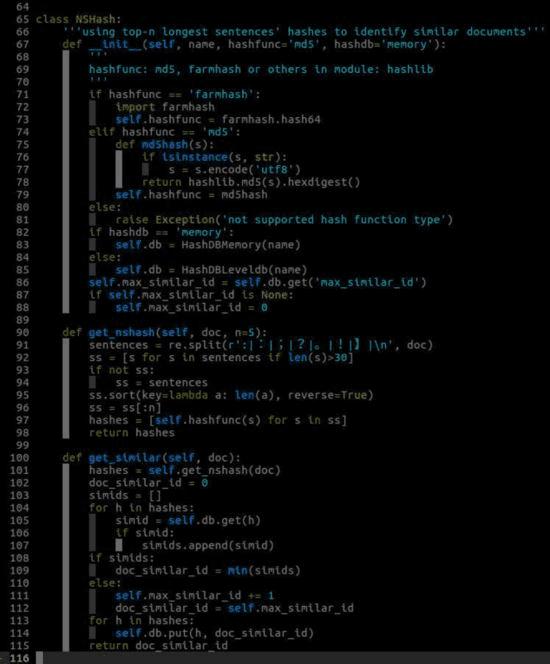
NSHash类的实现
三、使用方法
import nshash
nsh = nshash.NSHash(name='test', hashfunc='farmhash', hashdb='memory')
similar_id = nsh.get_similar(doc_text)
NSHash 类有三个参数:
name : 用于hashdb保存到硬盘的文件名,如果hashdb是HashDBMemory, 则用pickle序列化到硬盘;如果是HashDBLeveldb,则leveldb目录名为:name+'.hashdb'。name按需随便起即可。
hashfunc : 计算hash值的具体函数类别,目前实现两种类型: md5 和 farmhash 。默认是 md5 ,方便Windows上安装farmhash不方便。
hashdb :默认是 memory 即选择HashDBMemory,否则是HashDBLeveldb。
至于如何利用similar_id进行海量文本的去重,这要结合你如何存储、索引这些海量文本。可参考example/test.py文件。这个test是对excel中保存的新闻网页进行去重的例子。
总结
以上所述是小编给大家介绍的使用Python检测文章抄袭及去重算法原理解析 ,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!