ResultMap collection多层嵌套使用
ResultMap介绍
在Mybatis使用中,ResultMap是最复杂的一种结构,也是功能最强大的结构之一。通过ResultMap能够将复杂的1对多的结果集映射到一个实体当中去,可以借助Mybatis来将复杂结构的数据对象映射到一个结果集中组装好。
结构
ResultMap有3个属性,如下:
<resultMapid="studentMap"type="User"extends="userMap"></resultMap>| 名称 | 说明 |
|---|---|
| id | resultMap标识,区分不同的resultMap |
| type | resultMap的属性,返回的类型 |
| extends | 继承的resultMap,类似类的继承,resultMap也可以继承 |
子元素
| 名称 | 说明 |
|---|---|
| id | 子元素中的id属性扮演主键作用,指定了该属性,则查询结果会以该属性字段为主键,允许多个主键,多个主键称为联合主键 |
| result | 返回结果字段,一般一个字段对应一个result |
| collection | 表示一对多关系,一般用于结果集中的集合属性,如List |
| association | 表示一对一关系 |
| discriminator | 鉴别器,根据实际选择来采用哪个类别作为实例 |
| constructor | 配置构造方法 |
id和result存在一些相同的属性:
property:映射的POJO属性名,如果column元素相同,会自动映射到POJO上
column:sql查询的列名
javaType:配置java的类型,可以是特定的类完全限定名或Mybatis上下文别名
jdbcType:配置数据库类型,一般不需要限定,Mybatis已经为我们做了此工作
typeHander:类型处理器,允许你使用特定的处理器来覆盖默认处理器。需要制定jdbcType和javaType相互转换规则
使用场景
举例:
查询一个复杂的结构,真实场景是不确定度详情信息,一个不确定度详情包含10项列表信息汇总,其中多项是list集合,list中依旧嵌套list,如图所示,此例子只演示2个比较复杂的list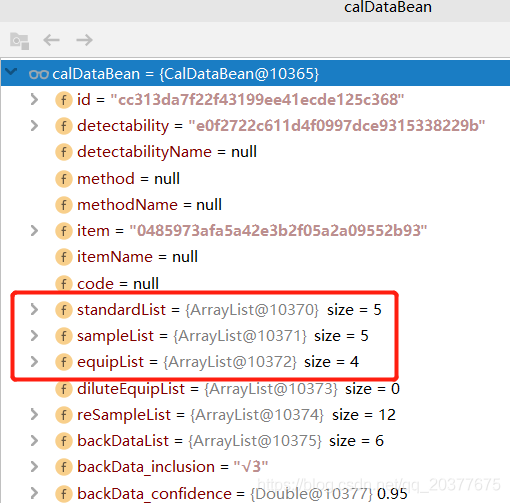
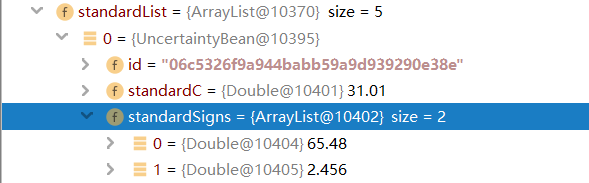
standardList是标准溶液列表,结构中standardSigns也是list结构,包含多个数值:
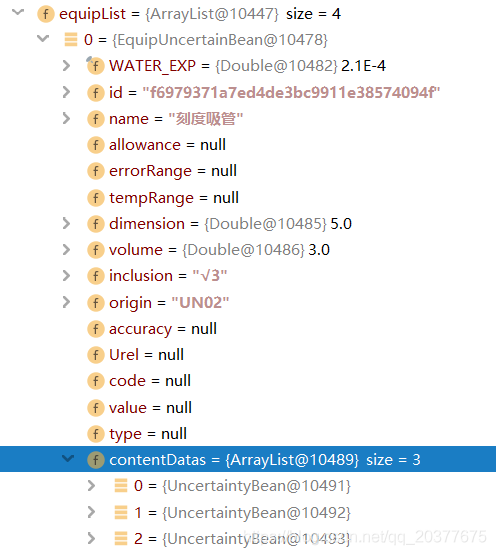
equipList是设备列表,每个设备中包含多个内容 contentDatas:
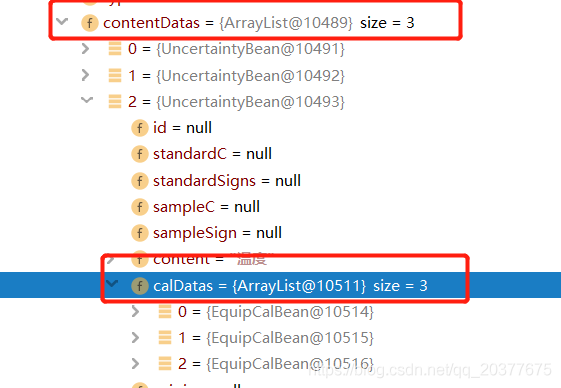
每个contentDatas中包含多个计算值信息calDatas:
最复杂的结构如上所示,接下来说如何实现。
实现方式一
一开始我是使用以前的办法,一个sql语句通过左连接将所有表关联起来,然后只使用一个resultMap让mybatis自己去映射关系。
<select id="getUncertainDataById1" resultMap="calDataMap1">SELECT
a.id,
a.urel,
a.inclusionAS k,
a.selected_cAS selectedC,
a.detectability,
a.item,
sar.`value`AS sampleC,
sac.`value`AS sampleSign,
bar.`value`AS backData,
bar.inclusionAS backData_k,
auto.nameAS autoName,
auto.accuracyAS accuracy,
auto.inclusionAS auto_k,
a.standard_cAS standardC,
a.rel_uncertaintyAS relUncertainty,
a.uncertainty,
a.backData_critical,
a.backData_isBack,
a.backData_confidence,
a.standard_inclusion,
a.backData_avg,
a.unit,
a.sampleSign_avg,
a.line_a,
a.line_b,
a.line_r,
eq.idAS eqid,
eq.`name`,
eq.dimension,
eq.volume,
eq.inclusionAS eq_k,
eq.origin,
eqr.idAS rid,
eqr.`value`AS content,
eqr.inclusion,
eqc.rowAS crow,
eqc.`value`,
eqc.sort,
eqc.description,
str.idAS strid,
str.`value`AS standardC,
stc.`value`AS standardSignFROM
t_uncertain a-- 关联样品数据LEFTJOIN t_uncertain_row sarON a.id= sar.`code`AND sar.type=2LEFTJOIN t_uncertain_column sacON sac.`row`= sar.id-- 关联回收率数据LEFTJOIN t_uncertain_row barON a.id= bar.`code`AND bar.type=4LEFTJOIN t_uncertain_column bacON bac.`row`= bar.id-- 关联自动进样器LEFTJOIN t_uncertain_equip autoON a.id= auto.`code`AND auto.origin='UN10'-- 仪器leftjoin t_uncertain_equip eqON eq.`code`= a.idand eq.origin='UN02'LEFTJOIN t_uncertain_row eqrON eq.id= eqr.equipAND eqr.type='3'LEFTJOIN t_uncertain_column eqcON eqc.`row`= eqr.id-- 标准曲线标准溶液LEFTJOIN t_uncertain_row strON str.`code`= a.idand str.type=1LEFTJOIN t_uncertain_column stcON stc.`row`= str.idWHERE
a.id=#{id}</select>将所有表关联起来查询,查询结果是呈笛卡尔积增加,仅仅查询一个结构该sql结果就已经达到了7200条数据!
之后再通过resultMap进行映射:
<resultMap id="calDataMap1"type="com.koron.laboratory.web.business.others.bean.CalDataBean"><idcolumn="id" property="id"/><!--样品数据--><collection property="sampleList" ofType="com.koron.laboratory.web.business.others.bean.UncertaintyBean"><resultcolumn="sampleC" property="sampleC"/><resultcolumn="sampleSign" property="sampleSign"/></collection><!--标准溶液--><collection property="standardList"column="id" ofType="com.koron.laboratory.web.business.others.bean.UncertaintyBean"><idcolumn="strid" property="id"/><resultcolumn="standardId" property="id"/><resultcolumn="standardC" property="standardC"/><collection property="standardSigns" ofType="java.lang.Double"><resultcolumn="standardSign"/></collection></collection><!--设备数据--><collection property="equipList"column="id" ofType="com.koron.laboratory.web.business.others.bean.EquipUncertainBean"><idcolumn="eqid" property="id"/><resultcolumn="name" property="name"/><resultcolumn="dimension" property="dimension"/><resultcolumn="volume" property="volume"/><resultcolumn="eq_k" property="inclusion"/><resultcolumn="origin" property="origin"/><resultcolumn="inclusion" property="inclusion"/><collection property="contentDatas" ofType="com.koron.laboratory.web.business.others.bean.UncertaintyBean"><idcolumn="crow"/><resultcolumn="content" property="content"/><resultcolumn="inclusion" property="inclusion"/><collection property="calDatas" ofType="com.koron.laboratory.web.business.others.bean.EquipCalBean"><resultcolumn="value" property="value"/><resultcolumn="description" property="description"/><resultcolumn="sort" property="sort"/></collection></collection></collection></resultMap>这里只保留了几个复杂list结构在resultMap中,其他不是list结构的数据省略了,但是由于也是需要去关联表,所以只要list结构数据量一旦大起来,最终结果都会变得很庞大。
这里需要注意的是 collection中的id属性,当在关联多个表的sql中 id属性作为主键来让mybatis知道该如何映射。即使collection中依旧包含collection,都会通过id属性来判断是否属于一个实体里面,当id相同时,collection中的属性就会自动映射进去。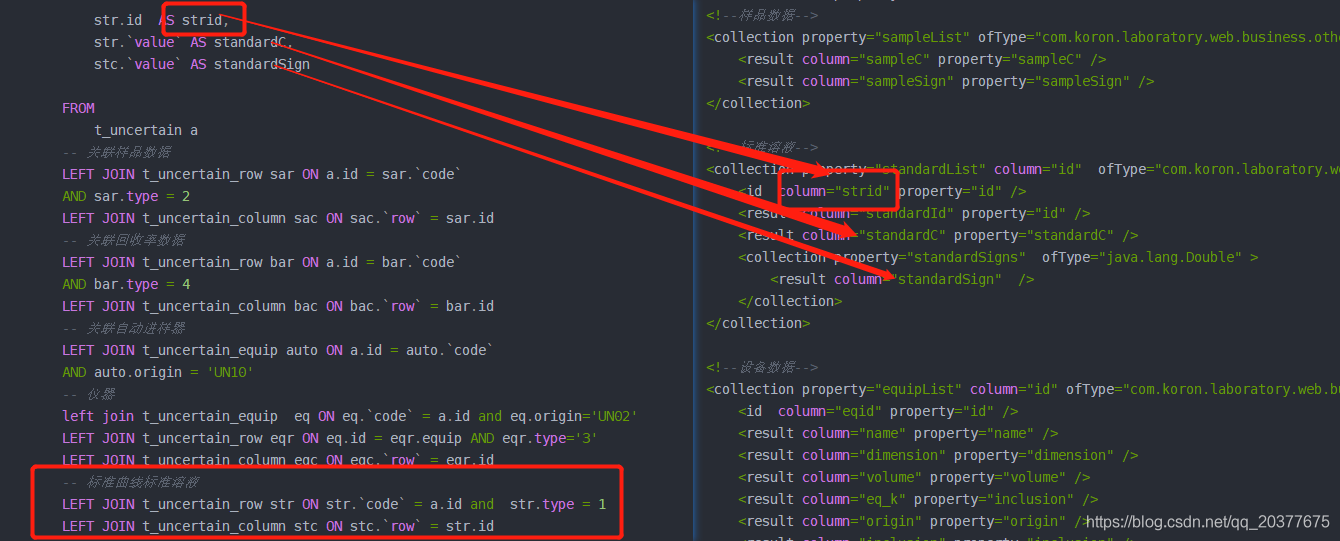
这里我遇见的问题就是一开始不知道通过id属性来区分list中,以前遇见的结构最多嵌套1层list,导致这里的多层list嵌套无法识别,仅仅都映射在第一个数据里了。
这种方法虽然能成功将数据映射好,但是将查询的多个结果直接交给mybatis处理,还是比较影响性能的。
实现方式二
将sql拆分成多个select,每个复杂的list结构的select 都用resultMap来接收,这里将standardList和equipList都通过一个select来将查询分开,resultMap具体结构如下:
<resultMap id="calDataMap" type="com.koron.laboratory.web.business.others.bean.CalDataBean"><id column="id" property="id"/><!--标准溶液--><collection property="standardList" column="id" select="getStandardList"/><!--样品数据--><collection property="sampleList" ofType="com.koron.laboratory.web.business.others.bean.UncertaintyBean"><result column="sampleC" property="sampleC"/><result column="sampleSign" property="sampleSign"/></collection><!--设备数据--><collection property="equipList" column="id" select="getEquipList"/><!--稀释设备数据--></resultMap><!-- 标准溶液查询resultMap--><resultMap id="standardListMap" type="com.koron.laboratory.web.business.others.bean.UncertaintyBean"><id column="id" property="id"/><result column="standardId" property="id"/><result column="standardC" property="standardC"/><collection property="standardSigns" ofType="java.lang.Double"><result column="standardSign"/></collection></resultMap><!-- 设备查询resultMap--><resultMap id="equipListMap" type="com.koron.laboratory.web.business.others.bean.EquipUncertainBean"><id column="id" property="id"/><result column="name" property="name"/><result column="dimension" property="dimension"/><result column="volume" property="volume"/><result column="eq_k" property="inclusion"/><result column="origin" property="origin"/><result column="inclusion" property="inclusion"/><collection property="contentDatas" ofType="com.koron.laboratory.web.business.others.bean.UncertaintyBean"><id column="crow"/><result column="content" property="content"/><result column="inclusion" property="inclusion"/><collection property="calDatas" ofType="com.koron.laboratory.web.business.others.bean.EquipCalBean"><result column="value" property="value"/><result column="description" property="description"/><result column="sort" property="sort"/></collection></collection></resultMap>标准溶液和仪器的select如下:
<!-- 查询标准溶液信息--><select id="getStandardList" resultMap="standardListMap">SELECT
str.id,
str.`value`AS standardC,
stc.`value`AS standardSignFROM
t_uncertain_row strLEFTJOIN t_uncertain_column stcON stc.`row`= str.idWHERE`code`=#{id}AND str.type=1ORDERBY
str.id</select><!-- 查询仪器信息--><select id="getEquipList" resultMap="equipListMap">SELECT
eq.id,
eq.`name`,
eq.dimension,
eq.volume,
eq.inclusionAS eq_k,
eq.origin,
eqr.idAS rid,
eqr.`value`AS content,
eqr.inclusion,
eqc.rowAS crow,
eqc.`value`,
eqc.sort,
eqc.descriptionFROM t_uncertain_equip eqLEFTJOIN t_uncertain_row eqrON eq.id= eqr.equipLEFTJOIN t_uncertain_column eqcON eqc.`row`= eqr.idwhere eq.`code`=#{id} AND eqr.type='3' and eq.origin='UN02'ORDERBY eq.`name`,eqr.`value`</select>在主体calDataMap中将复杂的collection拆分成select结构,每个select结构有自己独有的resultMap来接收,拆分后每个sql单独执行单独进行数据映射,最终映射好直接插入主体的calDataMap中,这样的做法可以大大的提高效率,以我个人简单的测试结果来看,当方式一查询结果达到7200数据时,方式二可以比方式一快10倍速度左右,当然这个倍数并不准确,但是可以明确的是速度可以快好几倍,效率可以大大提升。
上图是我进行测试的数据,第一个时间是方式二执行的,第二个是方式一执行的,很明显可以看出2种方式在性能上的差距。
总结
当结构并不是特别复杂的情况下,可以通过使用一个sql将resultMap映射好,当结构中嵌套多层类似list结构的集合时,则需要考虑性能问题,最好将每个collocation拆分开单独对应一个select,这样可以大大提高效率。