读取文件时,如果文件过大,则一次读取全部内容到内存,容易造成内存不足,所以要对大文件进行批量的读取内容。
python读取大文件通常两种方法:第一种是利用yield生成器读取;第二种是:利用open()自带方法生成迭代对象,这个是一行一行的读取。
1、利用yield生成器读取
示例代码:
# import random
# 生成模拟测试数据
# for i in range(100000):
# random_data = random.randint(1, 100)
# data = f"num:{i}, random_num: {random_data} \n"
# with open('data/big_data.txt', 'a', encoding='utf-8') as f:
# f.write(data)
def read_big_file(file_path, size=1024, encoding='utf-8'):
with open(file_path, 'r', encoding=encoding) as f:
while True:
part = f.read(size)
if part:
yield part
else:
return None
file_path = 'data/big_data.txt'
size = 100 # 每次读取指定大小的内容到内存,为了测试更加明显,这儿写的小一些
# 注意:以'a'追加模式下,大文件也不会占用太多内存
for part in read_big_file(file_path, size):
with open('data/new_big_data.txt', 'a', encoding='utf-8') as w:
w.write(part)
print(part)
print('*' * 100)
运行结果:

2、利用open()自带方法生成迭代对象
注意:这是一行一行的读取,在数据量比较大的时候效率是极低的。
示例代码:
# import random
# 生成模拟测试数据
# for i in range(100000):
# random_data = random.randint(1, 100)
# data = f"num:{i}, random_num: {random_data} \n"
# with open('data/big_data.txt', 'a', encoding='utf-8') as f:
# f.write(data)
file_path = 'data/big_data.txt'
new_file_path = 'data/new_big_data.txt'
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
print(line)
with open(new_file_path, 'a', encoding='utf-8') as a:
a.write(line)
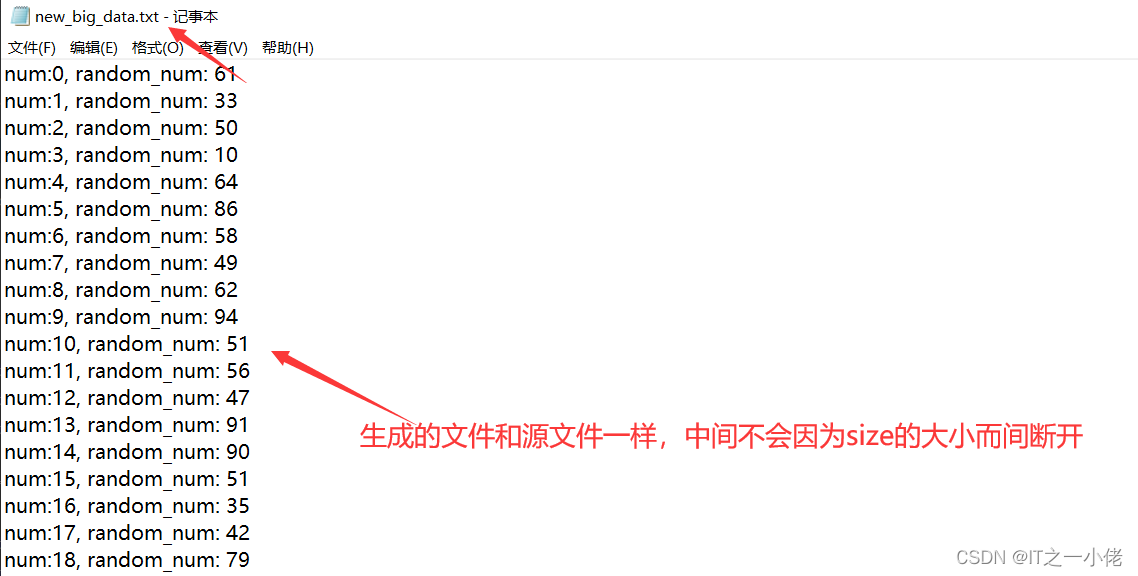
运行结果: