文章目录
python课后练习
本学习的课程Python程序设计的练习在拼题A上完成,为了记录学习过程,对课后练习进行整理
python课后练习整理(二)
Python练习01
判断题

- 在Python 3.x中可以使用中文作为变量名
答案:True
原因:Python3中,源文件默认使用UTF-8编码 - Python变量使用前必须先声明,并且一旦声明就不能再当前作用域内改变其类型。
答案:False
原因:在当前作用域内,可以对Python变量重新赋值,根据赋值不同,其类型也会发生改变
示例:
- Python运算符%不仅可以用来求余数,还可以用来格式化字符串
答案:True
示例: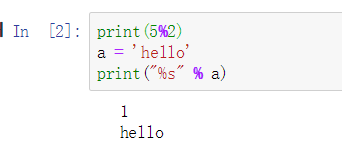
- 在Python 3.x中,使用内置函数input()接收用户输入时,不论用户输入的什么格式,一律按字符串进行返回。
答案:True
示例: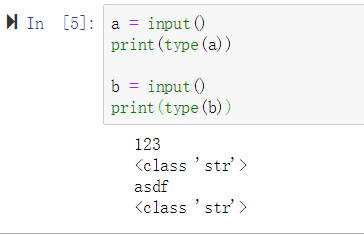
- 在Python中,变量不直接存储值,而是存储值的引用,也就是值在内存中的地址。
答案:True
示例: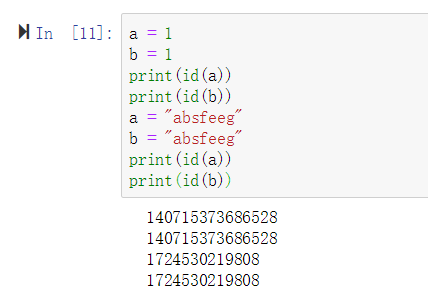
编程题
- jmu-python-输入输出-计算字符串中的数
将字符串中的每个数都抽取出来,然后统计所有数的个数并求和。
输入格式:
一行字符串,字符串中的数之间用1个空格或者多个空格分隔。
输出格式:
第1行:输出数的个数。
第2行:求和的结果,保留3位小数。
输入样例:
2.1234 2.1 3 4 5 6
输出样例:
6
22.223
解答:
s = input()
num = s.split()
Sum = 0
for i in num:
Sum += float(i)
print(len(num))
print("%0.3f" % Sum)
- 输入列表,求列表元素和(eval输入应用)
在一行中输入列表,输出列表元素的和。
输入格式:
一行中输入列表。
输出格式:
在一行中输出列表元素的和。
输入样例:
[3,8,-5]
输入样例:
6
解答:
不使用eval()函数的时候,我是这么写的
a=input().lstrip('[').rstrip(']') # 先将输入的字符串去掉两端括号
list=[] # 新建列表,用来存放数字
for i in a.split(','): # 再将字符串使用','切片
list.append(int(i)) # 将字符列表里的字符型数字强制转换为数字型,并添加到list里
sum=0
for num in list: # 对列表list进行求和
sum+=num
print(sum)
当我使用eval()函数
list=eval(input()) # eval()函数直接将字符串类型的列表转化为列表类型
sun = 0
for num in list: # 列表求和
sum+=num
print(sum)
- 你好
你的程序会读入一个名字,比如John,然后输出“Hello John”。
输入格式:
一行文字。
输出格式:
一行文字。
输入样例:
Mary Johnson
输出样例:
Hello Mary Johnson
解答:
# 直接进行字符串连接输出就可以了
a=input()
print("Hello",a) # print()函数在输出多个参数时,默认使用空格间隔
# 以下是运行结果
Mike
Hello Mike
- List item
程序会读入两行,每行都是一个数字,输出这两个数字的和
输入格式:
两行文字,每行都是一个数字
输出格式:
一行数字
输入样例:
18
21
输出样例:
39
解答:
# 由于规定了输入格式为数字,所以只需进求和输出即可
a = eval(input())
b = eval(input())
print(a+b)
笔记
-
input()函数
- 获取用户输入,返回值为字符串
-
如果需要在输入前打印提示信息,可以在括号里添加字符串
如:python input("请输入")
split()函数
- 格式:split(str,num)
- 功能:通过指定分隔符对字符串进行切片
- 参数说明:str表示分割使用的字符,num表示分割次数,默认为全部分割 eval()函数
- 格式: eval(s)
- 功能:将字符串格式的对象具现化
Python练习02
判断题

-
已知st=“Hello World!”,使用print(st[0:-1])语句可以输出字符串变量st中的所有内容。(False)
示例: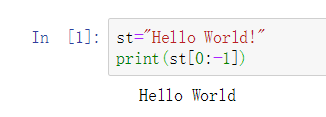
-
Python程序设计中的整数类型没有取值范围限制,但受限于当前计算机的内存大小。 True
-
已知: x=1 y=2 z=[2,3,4] 则语句 x not in z 计算结果是True。 True
in 和 not in 在python里称为成员运算符,表示一个值是否属于某一序列,返回值为True或False -
已知 x = 3,那么执行语句 x+=6 之后,x的内存地址不变。 False
python使用引用型数据,所以进行运算后,数字型的x的地址会发生改变
单选题

- 表达式1+2*3.14>0的结果类型是: (2分)
int
long
float
bool
1+2*3.14显然大于0,所以结果是Ture,为bool型
- 八进制35的十进制值是_。 (2分)
30
25
19
29
十进制转其他进制使用除n取余法,其他进制转十进制则相反,3*81+5*80
- Python语言正确的标识符是_。 (2分)
2you
my-name
_item
abc*234
Python规定,标识符的命名必须只能采用字母数字下划线,且不能以数字开头
- _号表示同一行的后面部分是Python程序的注释。 (2分)
*
%
/
#
Python里使用#进行行注释
- Python 语句 print(0xA + 0xB)的输出结果是__。 (2分)
0xA + 0xB
A + B
0xA0xB
21
'0x’前缀表示十六进制,0xA 0xB分别表示10和11
- Python 语句’car’; y = 2; print (x+y)的输出结果是__。 (2分)
语法错
2
'car2’
'carcar’
1,car两端的引号使用的是中文的单引号,非法
2,Python里不以分号表示语句结束
3,无法直接进行字符串和数字相加,如果要进行连接的话,应进行类型转换
编程题
- 产生每位数字相同的n位数
读入2个正整数A和B,1<=A<=9, 1<=B<=10,产生数字AA...A,一共B个A
输入格式:
在一行中输入A和B。
输出格式:
在一行中输出整数AA...A,一共B个A
输入样例1:
在这里给出一组输入。例如:
1, 5
输出样例1:
在这里给出相应的输出。例如:
11111
输入样例2:
在这里给出一组输入。例如:
3 ,4
输出样例2:
在这里给出相应的输出。例如:
3333
解答:
a,b= eval(input())
print(str(a)*b)
- 转换函数使用
输入一个整数和进制,转换成十进制输出
输入格式:
在一行输入整数和进制
输出格式:
在一行十进制输出结果
输入样例:
在这里给出一组输入。例如:
45,8
输出样例:
在这里给出相应的输出。例如:
37
解答:
a,b=eval(input())
print(int(str(a),b)) # int(str,num)将num进制的数str转换为十进制
- jmu-python-统计字符个数
输入一个字符串,统计其中数字字符及小写字符的个数
输入格式:
输入一行字符串
输出格式:
共有?个数字,?个小写字符,?填入对应数量
输入样例:
helo134ss12
输出样例:
共有5个数字,6个小写字符
解答:
lowerletters=0
numbers=0
strs=input()
for c in strs:
if(c.islower()):
lowerletters+=1
if(c.isdigit()):
numbers+=1
print('共有%d个数字,%d个小写字符' % (numbers,lowerletters))
笔记
- Python进制函数,常见的有
bin()# 二进制,二进制数字格式为0b**
oct()# 八进制,八进制数字格式为0o**
hex()# 十六进制,十六进制数字格式为0x** - 字符串的乘法
python里直接用字符串乘以一个数n,表示n个相同字符串拼接而成的字符串 - 判断字符,小写,数字
isdigit()
True: Unicode数字,byte数字(单字节),全角数字(双字节)
False: 汉字数字,罗马数字,小数
Error: 无
isdecimal()
True: Unicode数字,,全角数字(双字节)
False: 罗马数字,汉字数字,小数
Error: byte数字(单字节)
isnumeric()
True: Unicode 数字,全角数字(双字节),汉字数字
False: 小数,罗马数字
Error: byte数字(单字节)
num = "1" #unicode
num.isdigit() # True
num.isdecimal() # True
num.isnumeric() # True
num = "1" # 全角
num.isdigit() # True
num.isdecimal() # True
num.isnumeric() # True
num = b"1" # byte
num.isdigit() # True
num.isdecimal() # AttributeError 'bytes' object has no attribute 'isdecimal'
num.isnumeric() # AttributeError 'bytes' object has no attribute 'isnumeric'
num = "IV" # 罗马数字
num.isdigit() # False
num.isdecimal() # False
num.isnumeric() # False
num = "四" # 汉字
num.isdigit() # False
num.isdecimal() # False
num.isnumeric() # True
以上内容来源于菜鸟教程1
python练习03
判断题

如a是一个列表,且a[:]与a[::-1]相等,则a中元素按顺序排列构成一个回文。
True a[:]表示正序切片,a[::-1]表示逆序切片,两者相等则a中元素按顺序构成回文
表达式 {1, 3, 2} > {1, 2, 3} 的值为True。
False 两集合元素相同,所以{1,2,3}=={1,3,2},原表达式的值为False
已知x为非空列表,那么执行语句x[0] = 3之后,列表对象x的内存地址不变。
True 修改列表某个元素不会更改整个列表的地址
Python内置的集合set中元素顺序是按元素的哈希值进行存储的,并不是按先后顺序。
True 集合元素是无序的,按hash存储
已知x是一个列表,那么x = x[3:] + x[:3]可以实现把列表x中的所有元素循环左移3位。
True x[3:]表示列表x从第4个元素到最后一个元素,x[:3]表示列表x从开始到第三个元素,两者进行拼接,效果是将列表x中所有元素循环左移3位
编程题
- 图的字典表示。
图的字典表示。输入多行字符串,每行表示一个顶点和该顶点相连的边及长度,输出顶点数,边数,边的总长度。比如上图0点表示:
{'O':{'A':2,'B':5,'C':4}}
输入格式:
第一行表示输入的行数 下面每行输入表示一个顶点和该顶点相连的边及长度的字符串
输出格式:
在一行中输出顶点数,边数,边的总长度
输入样例:
在这里给出一组输入。例如:
4
{'a':{'b':10,'c':6}}
{'b':{'c':2,'d':7}}
{'c':{'d':10}}
{'d':{}}
输相应的输出。例如:
4 5 35
解答:
pointnum = int(input()) # 输入点的数量
edgesum = 0 # 声明周长
edgenum = 0 # 声明边数for i in range(pointnum):
dictlist=eval(input()) # 获取表示一个顶点和该顶点相连的边及长度的字典
for j in dictlist:
dict=dictlist[j] # 获取边长字典
for k in dict:
edgenum += 1 # 边数计数
edgesum += dict[k] # 边长求和
break
print(pointnum,edgenum,edgesum)
- jmu-python-逆序输出
输入一行字符串,然后对其进行如下处理。
输入格式:
字符串中的元素以空格或者多个空格分隔。
输出格式:
逆序输出字符串中的所有元素。
然后输出原列表。
然后逆序输出原列表每个元素,中间以1个空格分隔。注意:最后一个元素后面不能有空格。
输入样例:
a b c e f gh
输出样例:
ghfecba
['a', 'b', 'c', 'e', 'f', 'gh']
gh f e c b a
解答:
str=input()
list=[]
for c in str.split(): #字符串切片
list.append(c) # 生成新的字符列表
print("".join(list[::-1])) # 将列表元素无间隔逆序输出
print(list) # 输出列表
print(" ".join(list[::-1])) # 将列表元素以空格为间隔逆序输出
- jmu-python-班级人员信息统计
输入a,b班的名单,并进行如下统计。
输入格式:
第1行::a班名单,一串字符串,每个字符代表一个学生,无空格,可能有重复字符。
第2行::b班名单,一串字符串,每个学生名称以1个或多个空格分隔,可能有重复学生。
第3行::参加acm竞赛的学生,一串字符串,每个学生名称以1个或多个空格分隔。
第4行:参加英语竞赛的学生,一串字符串,每个学生名称以1个或多个空格分隔。
第5行:转学的人(只有1个人)。
输出格式
特别注意:输出人员名单的时候需调用sorted函数,如集合为x,则print(sorted(x))
输出两个班级的所有人员数量
输出两个班级中既没有参加ACM,也没有参加English的名单和数量
输出所有参加竞赛的人员的名单和数量
输出既参加了ACM,又参加了英语竞赛的所有人员及数量
输出参加了ACM,未参加英语竞赛的所有人员名单
输出参加英语竞赛,未参加ACM的所有人员名单
输出参加只参加ACM或只参加英语竞赛的人员名单
最后一行:一个同学要转学,首先需要判断该学生在哪个班级,然后更新该班级名单,并输出。如果没有在任何一班级,什么也不做。
输入样例:
abcdefghijab
1 2 3 4 5 6 7 8 9 10
1 2 3 a b c
1 5 10 a d e f
a
输出样例:
Total: 20
Not in race: ['4', '6', '7', '8', '9', 'g', 'h', 'i', 'j'], num: 9
All racers: ['1', '10', '2', '3', '5', 'a', 'b', 'c', 'd', 'e', 'f'], num: 11
ACM + English: ['1', 'a'], num: 2
Only ACM: ['2', '3', 'b', 'c']
Only English: ['10', '5', 'd', 'e', 'f']
ACM Or English: ['10', '2', '3', '5', 'b', 'c', 'd', 'e', 'f']
['b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
解答:
a = input()
# a="abcdefghijab"
seta = set(a) # 由题意可知,要进行集合运算,则用集合表示每个群体
# print(seta)
b = input()
# b="1 2 3 4 5 6 7 8 9 10"
setb = set(b.split()) # 通过切片操作消除空格
# print(setb)
acm = input()
# acm = "1 2 3 a b c"
setacm = set(acm.split())
# print(setacm)
english = input()
# english = "1 5 10 a d e f"
setenglish = set(english.split())
# print(setenglish)
zhuanxue = input()
# zhuanxue = "a"
# setzhuanxue = set(zhuanxue) # 转学生作为独立集合
# print(setzhuanxue)
Total = seta.union(setb) # 两班所有学生---并集
race = setacm.union(setenglish) #竞赛学生---并集
Notinrace = Total.difference(race) #非竞赛学生---差集
ACMplusEnglish = setacm.intersection(setenglish) # 报名两项竞赛学生---交集
OnlyACM = setacm.difference(setenglish) # 仅报ACM学生---差集
OnlyEnglish = setenglish.difference(setacm) # 仅报英语竞赛学生---差集
ACMOrEnglish = setacm.symmetric_difference(setenglish) # 报名一项竞赛---对称差集
print("Total:",len(seta.union(setb)))
print("Not in race:",sorted(Notinrace),end=", ")
print("num:",len(Notinrace))
print("All racers:",sorted(race),end=", ")
print("num:",len(race))
print("ACM + English:",sorted(ACMplusEnglish),end=", ")
print("num:",len(ACMplusEnglish))
print("Only ACM:",sorted(OnlyACM))
print("Only English:",sorted(OnlyEnglish))
print("ACM Or English:",sorted(ACMOrEnglish))
# 将转学学生当成集合,进行差集运算,考虑到只有一个转学生,故使用第二种方法
# if zhuanxue in seta:
# seta.difference_update(setzhuanxue)
# print(sorted(seta))
# elif zhuanxue in setb:
# setb.difference_update(setzhuanxue)
# print(sorted(setb))
# 将转学学生当成集合元素,进行元素移除运算
if zhuanxue in seta:
seta.remove(zhuanxue)
print(sorted(seta))
elif zhuanxue in setb:
setb.remove(zhuanxue)
print(sorted(setb))
笔记
- join()函数
--语法:str.join(sequence)
--功能:将序列中的元素以指定的字符连接生成一个新的字符串
--参数说明
----str表示连接所用的字符,sequence表示需要连接的序列 - 集合函数
seta.union(setb,setc....) # 并集
seta.difference(setb) # 差集
seta.intersection(setb,setc....)# 交集
seta.symmetric_difference() # 对称差集
seta.remove(item) # 移除指定元素
Python练习04
这次的判断题没什么难度,所以不进行整理
编程题
- jmu-python-汇率兑换
按照1美元=6人民币的汇率编写一个美元和人民币的双向兑换程序
输入格式:
输入人民币或美元的金额,人民币格式如:R100,美元格式如:$100
输出格式:
输出经过汇率计算的美元或人民币的金额,格式与输入一样,币种在前,金额在后,结果保留两位小数
输入样例1:
R60
输出样例1:
$10.00
输入样例2:
$5
输出样例2:
R30.00
解答:
money = input()
if money.startswith('R',0,1):
numofchange = int(money.lstrip('R'))/6
print('$',"%.2f" % numofchange,sep='')
elif money.startswith('$',0,1):
numofchange = int(money.lstrip('$'))*6
print('R',"%.2f" % numofchange,sep='')
- jmu-python-成绩转换
本题要求编写程序将一个百分制成绩转换为五分制成绩。转换规则:
大于等于90分为A; 小于90且大于等于80为B; 小于80且大于等于70为C; 小于70且大于等于60为D; 小于60为E。
输入样例:
98
输出样例:
A
解答:
score100 = int(input())
if score100>=90:
print('A')
elif 80<=score100<90:
print('B')
elif 70<=score100<80:
print('C')
elif 60<=score100<70:
print('D')
else:
print('E')
笔记
- 汇率转换主要包含的问题有
–识别输入字符串的开头字符-----------使用str.startswith(str,beg,end)函数,返回值为bool类型
–从字符串中提取数字并进行运算-----先去除开头字符str.lstrip(str),然后字符串转数字
–输出的数字要带两位小数--------------”%.2f"%num,或者format(num,’.2f’) - 成绩转换主要涉及多重分支的选择结构
由于python里没有switch语句
所以只有不断的if … elif …else