1. String/StringBuilder/StringBuffer 区别
1.1 String
String 对象一旦创建之后就是不可变的,不可变的!
问题:既然String 对象是不可变的,那么其包含的常用修改值的方法是如何实现的呢?
Demo
substring(int,int) 字符串截取split(String,int) 字符串分割toLowerCase() 字符串所有字母小写...其实,这些方法底层都是通过重新创建一个String 对象来接收变动后的字符串,而最初的 String 对象并未发生改动!
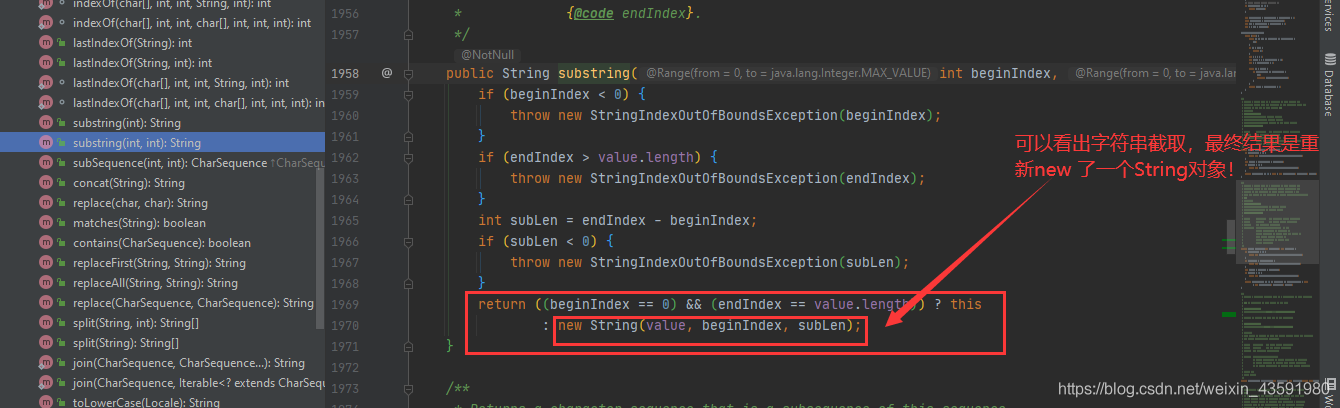
注意点(重要)
我们经常使用String 字符串进行+ 或者+= 操作,来改变字符串的值,这种情况比较特殊!
首先在JAVA中+ 和+= 是仅有的两个重载过的操作符,在进行字符串相加时候其String 对象并未发生改变,而是值发生改变了!
案例1:
String str="Hello"+"Wrold";使用javap 命令对其进行反编译后得到如下代码:
str=newStringBuilder("Hello").append("Wrold").toString();结论:从上面案例得出,String 字符串+ 的操作,底层其实是通过StringBuilder 执行的!
从效率角度触发,在大部分情况下,使用+ 连接字符串并不会造成效率上的损失,而且还可以提高程序的易读性和简洁度!
案例2:
String str="0";
String append="1";for(int i=0; i<10000; i++){// 结果为:str = 011111.......(很多1)
str+= append;}这种情况下,如果反编译的话,得到的是如下代码:
...for(int i=0; i<10000; i++){// 结果为:str = 011111.......(很多1)
str=(newStringBuilder()).append(str).append(append).toString();}这种情况下,由于大量StringBuilder 创建在堆内存中,肯定会造成效率的损失,所以在这种情况下建议在循环体外创建一个StringBuilder 对象调用append() 方法手动拼接!
案例3:
除了上面两种情况,我们再来分析一种特殊情况,即:
当+ 两端均为字符串常量(此时指的是"xxx" 而不是final修饰的String对象)时,在编译过后会直接拼接好,例如:
System.out.println("Hello"+"World");反编译后变为:
System.out.println("HelloWorld");这样的情况下通过+拼接字符串效率是最佳的!
1.2 StringBuilder
StringBulider 是一个可变的字符串类!可以把它看作是一个容器。
- StringBuilder 可以通过
toString()方法转换成String - String 可以通过StringBuilder 的构造方法,转换成StringBuilder
eg:
String string=newStringBuffer().toString();
StringBulider stringBuilder=newStringBulider(newString());StringBuilder 拼接字符串的效率较高,但是它不是线程安全的!
1.3 StringBuffer
StringBuffer 同样是一个可变的字符串类!也可以被看作是一个容器。
- StringBuffer 可以通过
toString()方法转换成String - String 可以通过StringBuffer 的构造方法,转换成StringBuffer
eg:
String string=newStringBuffer().toString();
StringBuffer stringBuffer=newStringBuffer(newString());Stringbuffer拼接字符串的效率相对于 StringBuilder 较低,但是它是线程安全的!
2. String/StringBuilder/StringBuffer 源码
2.1 String 源码分析
2.1.1 String 类
publicfinalclassStringimplementsjava.io.Serializable, Comparable<String>, CharSequence{...}- 首先从代码可以看出,String 类被final 关键字修饰,该类不能被继承!
- String 还实现了
Serializable ,Comparable<String>, CharSequence等接口,能够被序列化,支持字符串判等比较,且是 一个char 值的可读序列 - Comparable 接口有
compareTo(String s)方法,CharSequence 接口有length(),charAt(int index),subSequence(int start,int end)方法。
2.1.2 String 类的属性
// 不可变的char数组用来存放字符串,说明其是不可变量.privatefinalchar value[];// int型的变量hash用来存放计算后的哈希值.privateint hash;// 默认为0// 序列化版本号privatestaticfinallong serialVersionUID=-6849794470754667710L;2.1.3 String 类的构造函数
// 不含参数的构造函数,一般没什么用,因为 value 是不可变量publicString(){this.value="".value;// "",注意不是null//this.value = new char[0]; jdk1.8之前的写法}// 参数为String类型的构造函数publicString(String original){this.value= original.value;this.hash= original.hash;}// 参数为char数组,使用java.utils包中的Arrays类复制publicString(char value[]){this.value= Arrays.copyOf(value, value.length);}// 调用public String(byte bytes[], int offset, int length, String charsetName)构造函数publicString(byte bytes[], String charsetName)throws UnsupportedEncodingException{this(bytes,0, bytes.length, charsetName);}publicString(byte bytes[],int offset,int length, String charsetName)throws UnsupportedEncodingException{if(charsetName== null)thrownewNullPointerException("charsetName");checkBounds(bytes, offset, length);this.value= StringCoding.decode(charsetName, bytes, offset, length);}
还有其他的构造方法,可以自己点入String 详细阅读...2.1.4 String 类的常用方法
简单方法
// 字符串长度publicintlength(){return value.length;}// 字符串是否为空publicbooleanisEmpty(){return value.length==0;}// 根据下标获取字符数组对应位置的字符publiccharcharAt(int index){if((index<0)||(index>= value.length)){thrownewStringIndexOutOfBoundsException(index);}return value[index];}// 得到字节数组publicbyte[]getBytes(){return StringCoding.encode(value,0, value.length);}重点方法
equals(Object anObject)
// 两个对象之间判等publicbooleanequals(Object anObject){// 如果引用的是同一个对象,返回trueif(this== anObject){returntrue;}// 如果不是String类型的数据,返回falseif(anObjectinstanceofString){
String anotherString=(String)anObject;int n= value.length;// 如果char数组长度不相等,返回falseif(n== anotherString.value.length){char v1[]= value;char v2[]= anotherString.value;int i=0;// 从后往前单个字符判断,如果有不相等,返回falsewhile(n--!=0){if(v1[i]!= v2[i])returnfalse;
i++;}returntrue;}}returnfalse;}该方法判等规则:
- 如果二者内存地址相同,则为true
- 如果对象类型不是String 类型,则为false,如果是就继续进行判等
- 如果对象字符长度不相等,则为false,如果相等就继续进行判等
- 从后往前,判断String 类中char 数组value 的单个字符是否相等,有不相等则为false。如果一直相等直到第一个数,则返回true
结论:根据判等规则得出,如果两个超长的字符串进行比较,是非常费时间的!
hashCode()
// 返回此字符串的哈希码publicinthashCode(){int h= hash;// 如果hash没有被计算过,并且字符串不为空,则进行hashCode计算if(h==0&& value.length>0){char val[]= value;//计算过程//val[0]*31^(n-1) + val[1]*31^(n-2) + ... + val[n-1]for(int i=0; i< value.length; i++){
h=31* h+ val[i];}
hash= h;}return h;}String 类重写了hashCode方法,Object中的hashCode方法是一个Native调用。String类的hash采用多项式计算得来,我们完全可以通过不相同的字符串得出同样的hash,所以两个String对象的hashCode相同,并不代表两个String是一样的。
那么计算hash值的时候为什么要使用31 作为基数呢?
先要明白为什么需要HashCode.每个对象根据值计算HashCode,这个code大小虽然不奢求必须唯一(因为这样通常计算会非常慢),但是要尽可能的不要重复,因此基数要尽量的大。另外,31N可以被编译器优化为左移5位后减1即31N = (N<<5)-1,有较高的性能。使用31的原因可能是为了更好的分配hash地址,并且31只占用5bits!
结论:
- 基数要用质数:质数的特性(只有1和自己是因子)能够使得它和其他数相乘后得到的结果比其他方式更容易产成唯一性,也就是Hash Code值的冲突概率最小。
- 选择31是观测哈希值分布结果后的一个选择,不清楚原因,但的确有利(更分散,减少冲突)。
compareTo(String anotherString)
// 按字典顺序比较两个字符串,比较是基于字符串中每个字符的Unicode值publicintcompareTo(String anotherString){// 自身对象字符串长度len1int len1= value.length;// 被比较对象字符串长度len2int len2= anotherString.value.length;// 取两个字符串长度的最小值limint lim= Math.min(len1, len2);char v1[]= value;char v2[]= anotherString.value;int k=0;// 从value的第一个字符开始到最小长度lim处为止,如果字符不相等,返回自身(对象不相等处字符-被比较对象不相等字符)while(k< lim){char c1= v1[k];char c2= v2[k];if(c1!= c2){return c1- c2;}
k++;}// 如果前面都相等,则返回(自身长度-被比较对象长度)return len1- len2;}这个方法写的很巧妙,先从0开始判断字符大小。如果两个对象能比较字符的地方比较完了还相等,就直接返回自身长度减被比较对象长度,如果两个字符串长度相等,则返回的是0,巧妙地判断了三种情况。
startsWith(String prefix,int toffset)
// 判断此字符串的子字符串是否从指定的索引开始,并以指定的前缀开头publicbooleanstartsWith(String prefix,int toffset){char ta[]= value;int to= toffset;char pa[]= prefix.value;int po=0;int pc= prefix.value.length;// Note: toffset might be near -1>>>1.// 如果起始地址小于0或者(起始地址+所比较对象长度)大于自身对象长度,返回falseif((toffset<0)||(toffset> value.length- pc)){returnfalse;}// 从所比较对象的末尾开始比较while(--pc>=0){if(ta[to++]!= pa[po++]){returnfalse;}}returntrue;}// startsWith重载方法1publicbooleanstartsWith(String prefix){returnstartsWith(prefix,0);}// startsWith重载方法2publicbooleanendsWith(String suffix){returnstartsWith(suffix, value.length- suffix.value.length);}起始比较和末尾比较都是比较经常用得到的方法,例如在判断一个字符串是不是http协议的,或者初步判断一个文件是不是mp3文件,都可以采用这个方法进行比较。
concat(String str)
// 将指定的字符串连接到该字符串的末尾public Stringconcat(String str){int otherLen= str.length();if(otherLen==0){returnthis;}int len= value.length;char buf[]= Arrays.copyOf(value, len+ otherLen);
str.getChars(buf, len);// 注意:这里是新new一个String对象返回,而并非原来的String对象returnnewString(buf,true);}// 位于 java.util.Arrays 类中publicstaticchar[]copyOf(char[] original,int newLength){char[] copy=newchar[newLength];// 调用底层c++
System.arraycopy(original,0, copy,0,
Math.min(original.length, newLength));return copy;}replace(char oldChar, char newChar)
// 返回一个字符串,该字符串是通过用 newChar 替换该字符串中所有出现的 oldChar 而产生的public Stringreplace(char oldChar,char newChar){// 新旧值先对比if(oldChar!= newChar){int len= value.length;int i=-1;char[] val= value;/* avoid getfield opcode */// 找到旧值最开始出现的位置while(++i< len){if(val[i]== oldChar){break;}}// 从那个位置开始,直到末尾,用新值代替出现的旧值if(i< len){char buf[]=newchar[len];for(int j=0; j< i; j++){
buf[j]= val[j];}while(i< len){char c= val[i];
buf[i]=(c== oldChar)? newChar: c;
i++;}// 注意:这里是新new一个String对象返回,而并非原来的String对象returnnewString(buf,true);}}returnthis;}trim()
// 返回值是此字符串的字符串,其中已删除所有前导和尾随的空格public Stringtrim(){int len= value.length;int st=0;char[] val= value;/* avoid getfield opcode */// 找到字符串前段没有空格的位置while((st< len)&&(val[st]<=' ')){
st++;}// 找到字符串末尾没有空格的位置while((st< len)&&(val[len-1]<=' ')){
len--;}// 如果前后都没有出现空格,返回字符串本身return((st>0)||(len< value.length))?substring(st, len):this;}案例分析
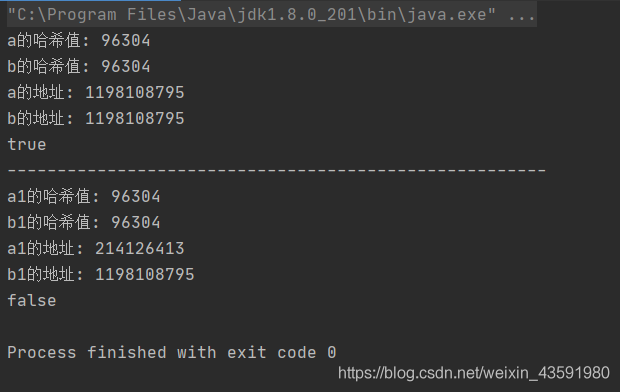
publicstaticvoidmain(String[] args){
String a="a"+"b"+1;
String b="ab1";// ab1 是放在常量池(constant pool)中的// 所以,虽然a,b都等于 ab1,但是内存中只有一份副本,所以 == 的结果为true
System.out.println("a的哈希值: "+ a.hashCode());
System.out.println("b的哈希值: "+b.hashCode());
System.out.println("a的地址: "+System.identityHashCode(a));
System.out.println("b的地址: "+System.identityHashCode(b));
System.out.println(a== b);
System.out.println("---------------------------------------------------
String a1=newString("ab1");
String b1="ab1";// new 方法决定了String "ab1" 被创建放在了内存heap区(堆上),被a1所指向// b1 位于常量池 因此 == 返回了false
System.out.println("a1的哈希值: "+ a1.hashCode());
System.out.println("b1的哈希值: "+b1.hashCode());
System.out.println("a1的地址: "+System.identityHashCode(a1));
System.out.println("b1的地址: "+System.identityHashCode(b1));
System.out.println(a1== b1);}输出结果:
2.2 StringBuilder 源码分析
2.2.1 StringBuilder 类
publicfinalclassStringBuilderextendsAbstractStringBuilderimplementsjava.io.Serializable, CharSequence{...}首先StringBuilder 同String 一样 被final 关键字修饰该类不能被继承!
从继承体系可以看出,StringBuilder 继承了AbstractStringBuilder类,该类中包含了可变字符串的相关操作方法:append()、insert()、delete()、replace()、charAt()等等。**StringBuffer 和 StringBuilder ** 均继承该类!
比如在StringBuilder 中的append(String str) 方法(后文还会讲到):
// java.lang.StringBuilder 类中@Overr