路径在很多地方都会使用,比如:文件名,URL地址等,JDK 提供了 Path 类用来表示路径。实际使用时,经常需要通过一个路径表示多个地址,比如,Spring 启动时的扫描路径,这就需要增加对通配符的支持,同时也就需要支持对通配符的匹配。
Spring 设计了 PathMatcher 路径匹配器接口,用于支持带通配符的资源路径匹配。这个接口在 Spring 的多个地方得到应用,比如:
- PathMatchingResourcePatternResolver:资源扫描,启动时扫描并加载资源
- AbstractUrlHandlerMapping:请求路径映射到 Controller
- WebContentInterceptor:拦截器拦截路径分析
Spring 为 PathMatcher 接口提供了一个默认实现 AntPathMatcher,支持 Ant 风格的路径匹配
| 匹配符 | 描述 |
|---|---|
| ? | 匹配一个字符 |
| * | 匹配多个字符 |
| ** | 匹配多层路径 |
另外,AntPathMatcher 还支持 {} 进行参数匹配
antPathMatcher.match("/root/aaa","/root/aaa"); // true
antPathMatcher.match("/root/*", "/root/aaa"); // true
// true,都以 / 结束
antPathMatcher.match("/root/*/", "/root/aaa/");// true
// false,结束符不一致
antPathMatcher.match("/root/*", "/root/aaa/"); // false
// true,/ 匹配 /*
antPathMatcher.match("/root/aaa/*", "/root/aaa/"); // true
// true,/ 匹配 /**
antPathMatcher.match("/root/aaa/**", "/root/aaa/"); // true
antPathMatcher.matchStart("/user/*","/user/001"); // 返回 true
antPathMatcher.matchStart("/user/*","/user"); // 返回 true
antPathMatcher.matchStart("/user/*","/user001"); // 返回 false
antPathMatcher.extractPathWithinPattern("uc/profile*","uc/profile.html"); // 返回 profile.html
antPathMatcher.combine("uc/*.html","uc/profile.html"); // uc/profile.html
源码分析
implement PathMatcher
public interface PathMatcher {
/**
* 判断路径是否带模式
*/
boolean isPattern(String path);
/**
* 判断 path 是否完全匹配 pattern
*/
boolean match(String pattern, String path);
/**
* 判断 path 是否前缀匹配 pattern
*/
boolean matchStart(String pattern, String path);
/**
* 去掉路径开头的静态部分,得到匹配到的动态路径
* 例如:myroot/*.html 匹配 myroot/myfile.html 路径,结果为 myfile.html
*/
String extractPathWithinPattern(String pattern, String path);
/**
* 匹配路径中的变量
* 例如:/hotels/{hotel} 匹配 /hotels/1 路径,结果为 hotel -> 1
*/
Map<String, String> extractUriTemplateVariables(String pattern, String path);
/**
* 返回一个排序比较器,用于对匹配到的所有路径进行排序
*/
Comparator<String> getPatternComparator(String path);
/**
* 合并两个模式
*/
String combine(String pattern1, String pattern2);
}
AntPathMatcher
isPattern
实现很简单,只要路径中拥有 *、? 以及 {},则认为是模式
public boolean isPattern(@Nullable String path) {
if (path == null) {
return false;
}
boolean uriVar = false;
for (int i = 0; i < path.length(); i++) {
char c = path.charAt(i);
if (c == '*' || c == '?') {
return true;
}
if (c == '{') {
uriVar = true;
continue;
}
if (c == '}' && uriVar) {
return true;
}
}
return false;
}
match & matchStart
match 匹配,matchStart 前缀匹配,extractUriTemplateVariables 参数匹配,三个方法最终都是走的 doMatch 方法
public boolean match(String pattern, String path) {
return doMatch(pattern, path, true, null);
}
public boolean matchStart(String pattern, String path) {
return doMatch(pattern, path, false, null);
}
public Map<String, String> extractUriTemplateVariables(String pattern, String path) {
Map<String, String> variables = new LinkedHashMap<>();
boolean result = doMatch(pattern, path, true, variables);
if (!result) {
throw new IllegalStateException("Pattern \"" + pattern + "\" is not a match for \"" + path + "\"");
}
return variables;
}
doMatch 是路径匹配的核心方法,这个方法比较长
首先对模式及路径按路径分隔符(默认为 /)进行拆分,得到模式数组与路径数组,然后对两个数组进行逐个对比匹配
/**
* @param pattern 模式
* @param path 路径
* @param fullMatch 是否需要完全匹配
* @param uriTemplateVariables 收集路径中的参数
*/
protected boolean doMatch(String pattern, String path, boolean fullMatch,
Map<String, String> uriTemplateVariables) {
if (path == null || path.startsWith(this.pathSeparator) != pattern.startsWith(this.pathSeparator)) {
return false;
}
String[] pattDirs = tokenizePattern(pattern);
if (fullMatch && this.caseSensitive && !isPotentialMatch(path, pattDirs)) {
return false;
}
String[] pathDirs = tokenizePath(path);
}
tokenizePattern 方法最终也是调用 tokenizePath 方法,只是在其基础上加了一层缓存。而 tokenizePath 方法则是直接调用工具方法 tokenizeToStringArray 方法,与 String.split() 方法效果是差不多的。
protected String[] tokenizePattern(String pattern) {
String[] tokenized = null;
// 是否开启缓存,默认为开启
Boolean cachePatterns = this.cachePatterns;
// 优先从缓存中获取
if (cachePatterns == null || cachePatterns.booleanValue()) {
tokenized = this.tokenizedPatternCache.get(pattern);
}
if (tokenized == null) {
// 调用 tokenizePath 方法进行拆分
tokenized = tokenizePath(pattern);
if (cachePatterns == null && this.tokenizedPatternCache.size() >= CACHE_TURNOFF_THRESHOLD) {
// 关闭缓存、清空缓存
deactivatePatternCache();
return tokenized;
}
if (cachePatterns == null || cachePatterns.booleanValue()) {
this.tokenizedPatternCache.put(pattern, tokenized);
}
}
return tokenized;
}
// split 的结果为空串,会从数组中删除
protected String[] tokenizePath(String path) {
return StringUtils.tokenizeToStringArray(path, this.pathSeparator, this.trimTokens, true);
}
拆分好之后,正式开始匹配。
匹配策略如下图所示:
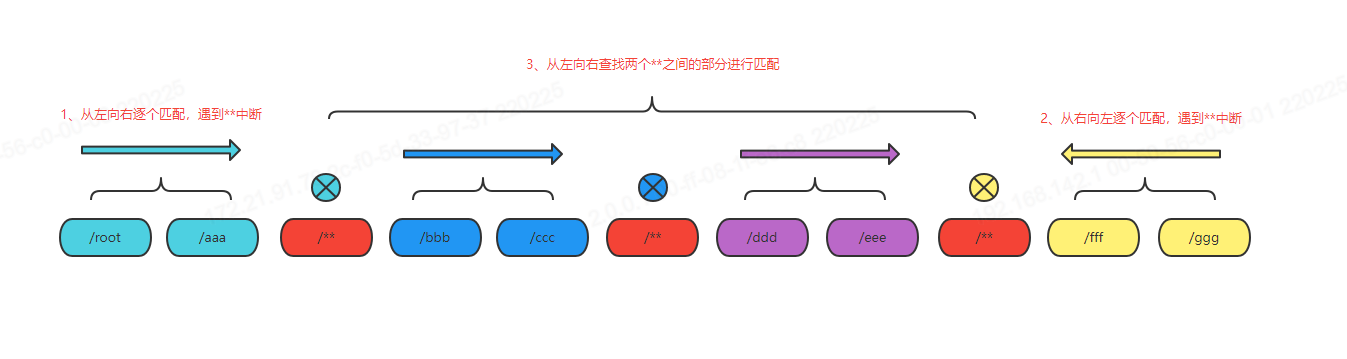
模式数组中可能存在 **,这将可能匹配多级目录,如果出现 **,情况将会变得复杂起来,所以考虑优先处理没有 ** 的情况。
模式数组与路径数组的长度可能一样,也可能不一样,先对最小长度范围内进行匹配,如果出现 **,则向后执行,如果匹配不上,则可以直接返回 false。
int pattIdxStart = 0;
int pattIdxEnd = pattDirs.length - 1;
int pathIdxStart = 0;
int pathIdxEnd = pathDirs.length - 1;
// 如果碰到 ** 则继续向下分析,如果匹配不上,则直接返回 false
while (pattIdxStart <= pattIdxEnd && pathIdxStart <= pathIdxEnd) {
String pattDir = pattDirs[pattIdxStart];
// 模式中如果存在 **,则跳出,因为 ** 代表多层路径
if ("**".equals(pattDir)) {
break;
}
if (!matchStrings(pattDir, pathDirs[pathIdxStart], uriTemplateVariables)) {
return false;
}
pattIdxStart++;
pathIdxStart++;
}
一级路径的匹配使用 matchStrings 方法进行匹配,这个匹配主要就是解析 * 与 {},使用内部类 AntPathStringMatcher 进行解析,这部分源码就不再展开分析了。
private boolean matchStrings(String pattern, String str, Map<String, String> uriTemplateVariables) {
return getStringMatcher(pattern).matchStrings(str, uriTemplateVariables);
}
再回到 doMatch 主流程,程序能运行到现在,有三种情况:
- 在模式与路径的共同范围内出现了
**匹配 - 路径全部匹配完毕
- 模式全部匹配完毕
当然也可能是模式与路径正好都匹配完毕,这可以归属于上面的第二种或者第三种。
如果路径匹配完毕,还需要注意结束符,以 / 结尾与不以 / 结尾表达的是两个意思,前者表示路径还未结束,后者则表示完整路径。
- 模式也正好匹配完成,说明两者完全匹配,此时还需要判断模式与路径的结束符是否一样。比如:模式为
/root/*与/root/aaa及/root/*/与/root/aaa/都可以匹配成功,但/root/*与/root/aaa/则不能匹配。
- 模式解析还没结束,说明前缀匹配成功,如果
fullMatch为false,则可以返回了。比如:模式为/root/*/bbb,路径为/root/aaa,前缀匹配成功。
- 模式解析还没结束,未解析部分为
/*,而路径以/结尾,也是可以匹配的。比如:模式为/root/*/*,路径为/root/aaa/,匹配成功。
- 以上都不是,则模式后面的规则无法匹配,匹配失败。比如:模式为
/root/*/bbb,路径为/root/aaa,匹配失败。
如果模式匹配完毕,但路径还没结束,说明匹配不成功,即便模式以 / 结尾。比如:模式为 /root/*/,路径为 /root/aaa/bbb,依然匹配失败。
// 路径已经分析完成
if (pathIdxStart > pathIdxEnd) {
// 模式也分析完成,说明完全匹配,判断最后的 `/` 是否匹配
if (pattIdxStart > pattIdxEnd) {
return (pattern.endsWith(this.pathSeparator) == path.endsWith(this.pathSeparator));
}
// 模式未分析完成,前缀匹配
if (!fullMatch) {
return true;
}
// /root/aaa/* 匹配 /root/aaa/ 可以成功
if (pattIdxStart == pattIdxEnd && pattDirs[pattIdxStart].equals("*") && path.endsWith(this.pathSeparator)) {
return true;
}
// 如果模式后面全是 ** 则匹配成功,否则失败
for (int i = pattIdxStart; i <= pattIdxEnd; i++) {
if (!pattDirs[i].equals("**")) {
return false;
}
}
return true;
} else if (pattIdxStart > pattIdxEnd) {
// 模式已经分析完,但路径还没有分析完,匹配失败
return false;
} else if (!fullMatch && "**".equals(pattDirs[pattIdxStart])) {
// /root/**/xxx 前缀匹配 /root/aaa 可以成功
return true;
}
程序能运行到现在,只有一种情况,就是模式中出现了 **,而且还不能确定后续还会不会出现 **,一个模式中是可以出现多个 ** 的。
此时路径的前半部分已经匹配,可以从后向前,继续判断路径后半部分是否匹配,如果都匹配上了,那么中间部分全是 ** 则匹配成功,否则匹配不成功。
while (pattIdxStart <= pattIdxEnd && pathIdxStart <= pathIdxEnd) {
String pattDir = pattDirs[pattIdxEnd];
if (pattDir.equals("**")) {
break;
}
if (!matchStrings(pattDir, pathDirs[pathIdxEnd], uriTemplateVariables)) {
return false;
}
pattIdxEnd--;
pathIdxEnd--;
}
// 路径与模式最后部分完全匹配,则要求模式中间部分全部都是 **,才能匹配成功
if (pathIdxStart > pathIdxEnd) {
// String is exhausted
for (int i = pattIdxStart; i <= pattIdxEnd; i++) {
if (!pattDirs[i].equals("**")) {
return false;
}
}
return true;
}
最后,也是最复杂的情况,路径后半部分也匹配到了 **,且不是开头匹配到的 **,则需要对两个 ** 之间的部分再进行匹配,而且中间部分还可能存在 **。
while (pattIdxStart != pattIdxEnd && pathIdxStart <= pathIdxEnd) {
int patIdxTmp = -1;
// 两个 ** 之间还有没有 **
for (int i = pattIdxStart + 1; i <= pattIdxEnd; i++) {
if (pattDirs[i].equals("**")) {
patIdxTmp = i;
break;
}
}
// 对 **/** 进行去重
if (patIdxTmp == pattIdxStart + 1) {
pattIdxStart++;
continue;
}
// 对两个 ** 之间的路径进行匹配
int patLength = (patIdxTmp - pattIdxStart - 1);
int strLength = (pathIdxEnd - pathIdxStart + 1);
int foundIdx = -1;
strLoop:
for (int i = 0; i <= strLength - patLength; i++) {
for (int j = 0; j < patLength; j++) {
String subPat = pattDirs[pattIdxStart + j + 1];
String subStr = pathDirs[pathIdxStart + i + j];
if (!matchStrings(subPat, subStr, uriTemplateVariables)) {
continue strLoop;
}
}
foundIdx = pathIdxStart + i;
break;
}
// 匹配不成功
if (foundIdx == -1) {
return false;
}
// 匹配成功,继续匹配下一个 ** 之间的路径
pattIdxStart = patIdxTmp;
pathIdxStart = foundIdx + patLength;
}
for (int i = pattIdxStart; i <= pattIdxEnd; i++) {
if (!pattDirs[i].equals("**")) {
return false;
}
}
return true;
匹配结果收集:
| 模式 | 路径 | 匹配结果 | 说明 |
|---|---|---|---|
| /root/aaa | /root/aaa | true | |
| /root/* | /root/aaa | true | |
| /root/*/ | /root/aaa/ | true | 都以 / 结束 |
| /root/*/ | /root/aaa | false | 结束符不一致 |
| /root/aaa/* | /root/aaa/ | true | / 匹配 /* |
| /root/aaa/** | /root/aaa/ | true | / 匹配 /** |
| /root/aaa/*/bbb | /root/aaa/ | false | / 不匹配 /*/bbb |
| /root/aaa/**/bbb | /root/aaa/ | false | / 不匹配 /**/bbb |