前言
主要记录自己pandas处理数据遇到的一些困难,基础非常薄弱,希望能越来越熟练
Next:set_index与reindex的区别
问题描述
经常会遇到
- 更改
index - 将某一个
column的信息设置为index(例如股票数据处理中,经常会遇到某一个column为日期) - 按照指定的
index重新拍累dataframe
问题解决
-
pd.set_index能够将DataFrame中的某一column设置为索引。如果传入的是column列表,则设置多层索引。 -
pd.reindex的作用是根据new_index重新排列DataFrame,且如果新的new_index中含有原index未含有的索引,则会创建新的行,且对应的行的值全部是Nan,当然,可以选择在reindex( )传入method参数来解决这一点,例如:method='ffill'
注意,set_index, reindex, sort_index的区别
-
set_index是将原本就存在的某一列或者某几列设置为索引,以构建索引(或者多层索引) -
reindex是将原来的DataFrame按照现如今新给出的index进行排序,可能会造成df数据的扩充,也可能会造成缺失值,需要进行处理 -
sort_index是不改变现有的index,只是将他们按照升序或者降序,重新排列数据,但如果数据不是升序或者降序,而是特殊的序列,则需要用reindex进行排序了
Next: 读入DataFrame时的数据类型问题
1. 指定读取csv文件时的数据类型
问题描述
在通过pd.read_csv( )方法读入csv数据时,如果未指定data_type,那么该方法会按照默认设置读入数据,有时候会将string字符串形式保存的数字读成float或者int的数据类型。
例如,我的trade_date是以字符串形式保存的,但是读入的时候默认变成了整数形,从而导致我按照字符串的index来reindex时,整个DataFrame的数据全部变为了Nan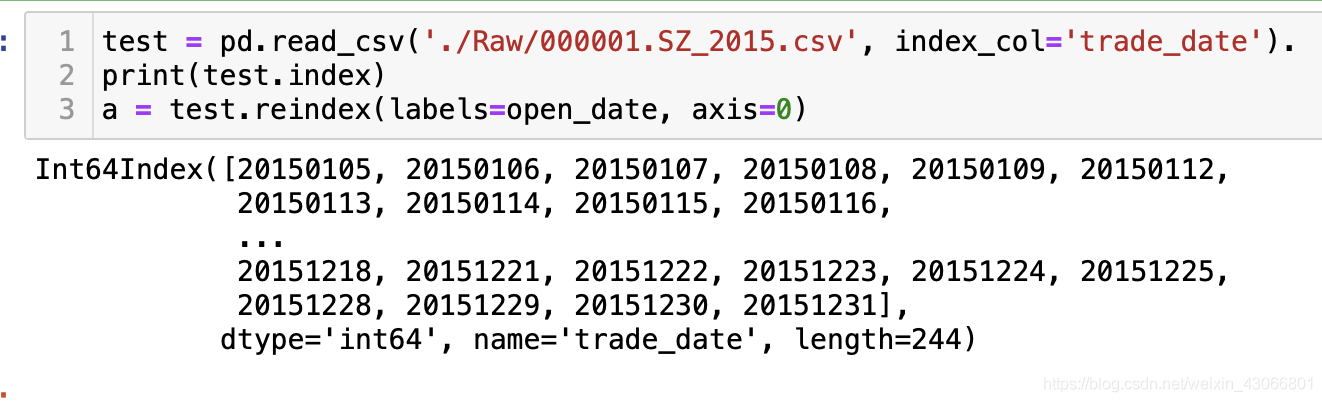
解决方法
在读入数据的时候,通过pd.read_csv( )设置参数 dtype={'trade_date' : 'string'},就可以了;当然,如果要以数值的形式读入,设置dtype={'trade_date' : 'value'},更改之后效果如下:
2.读取csv文件时,指定作为index的列
设置index_col=column_name即可,当设置为0时,默认不读取任何一列作为index
pd.read_csv(index_col=column_name)
Next: 读写DataFrame时的参数问题
1. 写入DataFrame时
- header:这代表将DataFrame的第n行作为表头,设置为False代表无表头
df = pd.DataFrame()
df.to_csv(header=None or 0~len(index))
- index:设置为True时,python会自动创造一个index,再次读入的时候,则会出现一个名称为unnamed的column,此column就是之前创造的,设置为False时,则不会创造此index
注意:如果之前读入DataFrame的时候,通过index_col=设置了index,则再次存入的时候,不要设置index=False,否则这会导致index的信息缺失!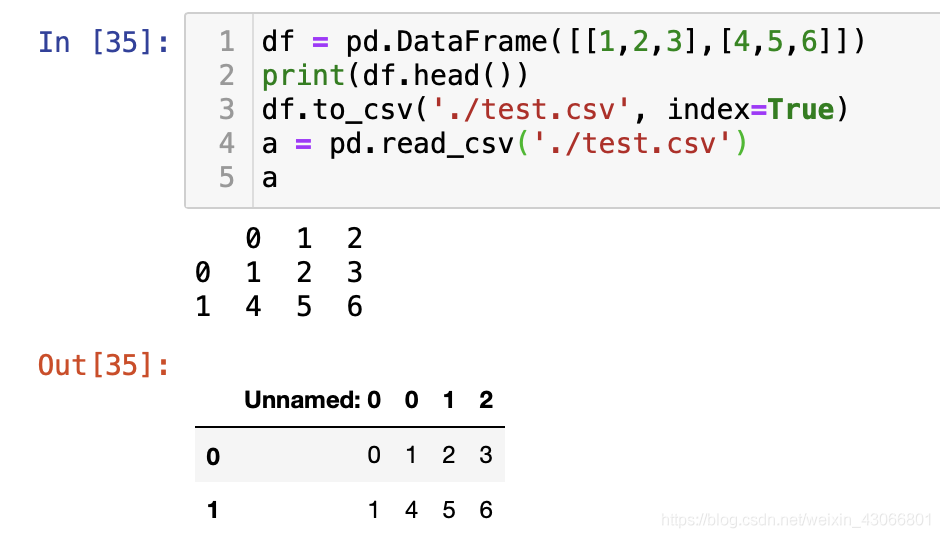
- index_label:设置index的名称,可以用df.index.name进行访问,如果没有设置,则会出现unnamed:0的情况
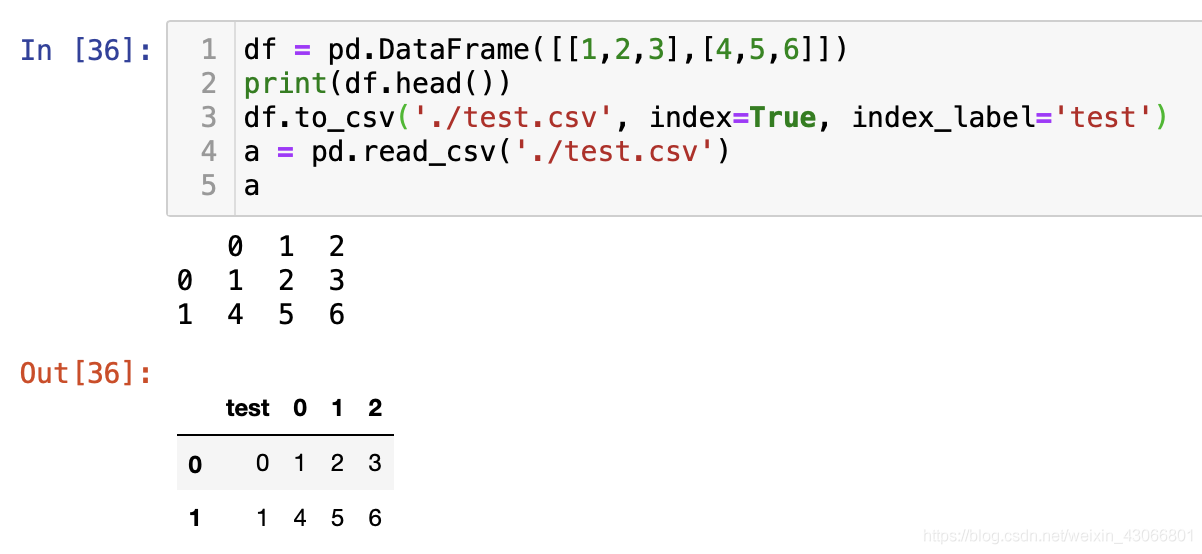
Next: DataFrame的合并,pd.merge()
问题描述
当通过tushare两个不同的接口获得了股票数据,pro.daily_basic获得了一些技术指标信息,pro.daily获得了每日股价信息,这两个dataframe中有重复的column,想把他们合并成一个dataframe,但同时合并相同的列,保留不同的列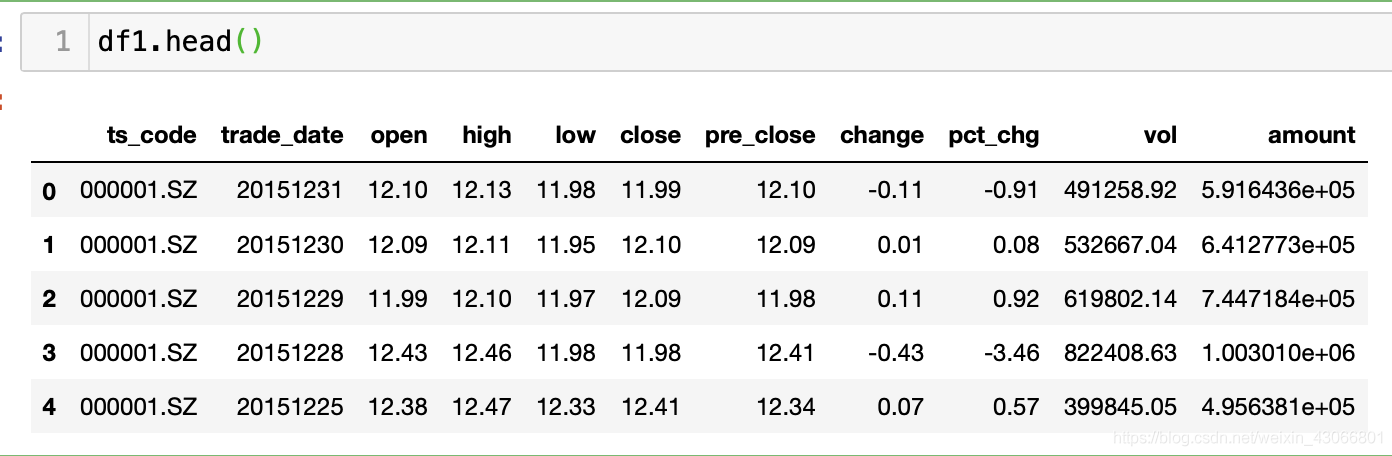
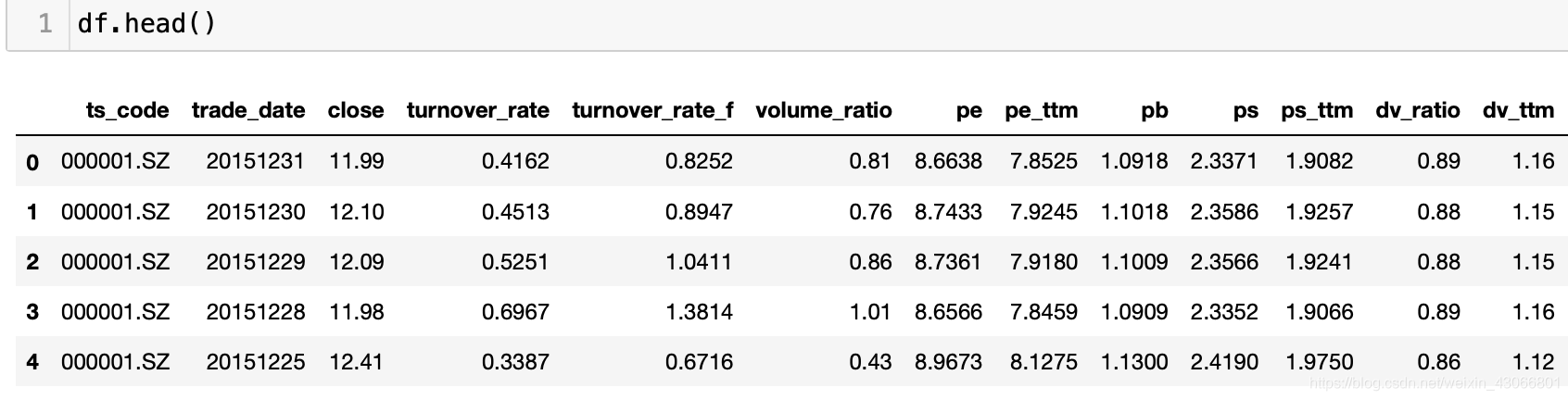
可以看到,二者是含有共同的column的,例如trade_date, ts_code。
问题解决
直接使用pd.merge(df1, df2)即可,因为on参数在默认的设置下,其会自动根据两个dataframe相同的列数(值也要相同)来进行合并,因此,上述的trade_date, ts_code, close就全部被合并了,合并后的columns如下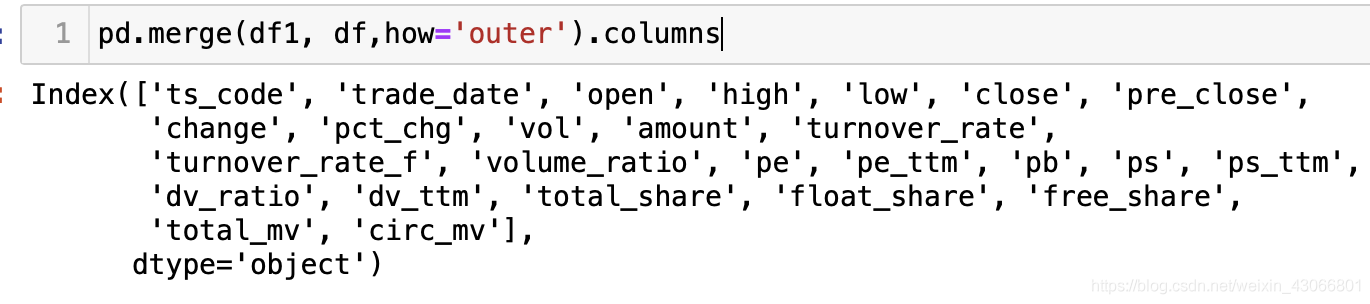
可以看到,相同的column已经合并了,不同的column也得以保留
Next: Pandas追加写入Excel数据
问题描述
通过Excel追加写入文件的时候,创建writer = pd.ExcelWriter(path, mode='a'),但是却产生了如下报错:
ValueError: Append mode is note supported with xlsxwriter
问题解决
产生这样问题的主要原因是因为:现在已有的的写入excel模块包含openpyxl和xlsxwriter,pd.ExcelWriter方法中默认的模块是xlsxwriter,但此模块不支持append追加操作,因此我们只需要更改pd.ExcelWriter方法中的默认模块即可:
# 写法1
with pd.ExcelWriter(path, mode='a', engine='openpyxl') as writer:
df1.to_excel(writer, sheet_name='this is the first')
df2.to_excel(writer, sheet_name='this is the second')
# 写法2
writer = pd.ExcelWriter(path, mode='a', engine='openpyxl')
df1.to_excel(wirter, sheet_name)
writer.save()
writer.close()
具体,可以参照这篇博文
Next:获取Pandas的行
问题描述
调取Pandas的某一行
问题解决
一般来说有三种解决方式
# 方法1:一个一个调用
df.loc[index, column]
# 方法2:iloc
df.iloc[index_num, column]
# 方法3:这样的方法可以调用DataFrame的行,但是不能够对列进行选择,因此默认是调用了所有的列
df[index_range]
注意:loc和iloc方法都可以批量调用,传入的是list, ndarray都是可以的
df.loc[a_list, :]
df.loc[index_list, column_list]
Next:对DataFrame进行批量操作
问题描述
想对DataFrame的行进行批量数量操作
问题解决
如果操作都是 同质化 的话,那么可以直接通过loc,iloc批量定位元素,然后统一进行操作
a = pd.DataFrame([[1,1,1],[1,1,1]], index=['a','b'], columns=['a','b','c'])
a
# 输出
a b c
a 1 1 1
b 1 1 1
批量操作,选中的元素统一加1
a.loc[['a','b'],['c','b']] += 1
a
# 输出
a b c
a 1 2 2
b 1 2 2
Next:Pandas的逻辑索引
Pandas的逻辑索引是通过
- 元素的标量运算
- Pandas的广播机制,将标量运算扩展到所有元素上
- 逻辑索引得到的结果为对应位置上的True(满足条件)或者False(不满足条件)
所以,如果逻辑运算不是针对标量运算的,那么将会报错,比如下面这样
# df如下
index_code con_code in_date out_date industry_name
0 801780.SI 601998.SH 20140221 NaN 银行
1 801780.SI 601838.SH 20180207 NaN 银行
2 801780.SI 002958.SZ 20190402 NaN 银行
3 801780.SI 601860.SH 20190110 NaN 银行
4 801780.SI 601577.SH 20181010 NaN 银行
# 本意:筛选出符合条件的股票代码
df[df.con_code==['601998.SH','601838.SH']]
# 报错如下
Lengths must match to compare
Lengths must match to compare这是因为,con_codea这一栏的元素都是字符串,但是逻辑运算对比的是list列表和string,所以会出现长度不匹配的问题
同样,Pandas的逻辑索引中,可以支持多个逻辑判断关系,但是这些判断关系也是必须针对元素级别的对比,也就是被对比的元素都必须是同种类型的。
多个逻辑判断必须符合以下的代码语法
# 多个逻辑的索引
df[(condition1) | (condition2)]
# 注意:|代表或,如果有多个条件都满足则全部返回,如果只有一个条件满足则返回一个
df[(df.con_code=='601998.SH') | (df.con_code=='601838.SH')]
df[(df.con_code=='601998.SH') | (df.con_code=='SH')]
# out
index_code con_code in_date out_date industry_name
0 801780.SI 601998.SH 20140221 NaN 银行
1 801780.SI 601838.SH 20180207 NaN 银行
index_code con_code in_date out_date industry_name
0 801780.SI 601998.SH 20140221 NaN 银行
Next:pd.drop删除元素
问题解决
和np.delete类似,Pandas也有删除元素的方法,为pd.drop,其使用方法和numpy几乎是一样的,同样有axis等参数
注意:pd.drop的删除只能够是沿着 轴 产生的。当为DataFrame时,其一次只能够删除列,或者单独删除行。而当Series时,其能够直接对元素进行删除(因为在Series中,一列/行就是一个元素)
Next:Pandas的索引
有时候会弄混Pandas的索引,需要整理一下,总的来说,Pandas拥有三大类索引方式
- 标签索引,
loc,通过输入loc[index, column]的方式进行索引 - 位置索引,
iloc,通过输入iloc[row_index, col_index的方式进行索引 - 布尔索引,通过类似
df[condition]的方式进行索引 - 其他索引
- 切片索引,通过
df[slice]的方式进行索引,用这种方式进行索引时,如果df.index为数值,则可能会产生一定的歧义。如果为非整数索引,例如index=['a','b','c']则不会产生歧义。例如:df[0:4]则是访问数据的前4行 - 键索引,用于访问列,通过
df[column_name]的方式进行索引,但是这种方式严格意义来说是访问列的。可以访问单列,也可以访问数个列。对于没有的列,会返回KeyError的错误。列名可以为字符串形式,例如df['stock_code']
- 切片索引,通过
Next:Pandas的赋值操作
描述Pandas中有一种非常灵活,好用的赋值方式,其实质是运用了pandas的布尔索引方法,然后定位到True的位置并赋值,其语法操作为df[condition] = value
a = np.arange(12).reshape(4,3)
df = pd.DataFrame(a)
df.iloc[1,1] = np.nan
print(df)
# output
0 1 2
0 0 1.0 2
1 3 NaN 5
2 6 7.0 8
3 9 10.0 11
通过df.isna()定位缺失值,然后通过布尔索引赋值
df[df.isna()] = 1
print(df)
# output
0 1 2
0 0 1.0 2
1 3 1.0 5
2 6 7.0 8
3 9 10.0 11
通过condition逻辑运算定位元素,然后通过布尔索引赋值,这里使得值大于4的全部重新设置为10086
0 1 2
0 0 1.0 2
1 3 1.0 10086
2 10086 10086.0 10086
3 10086 10086.0 10086
Next:Pandas的对齐机制
问题描述
在将两个df进行运算操作时,其合总后的DataFrame包含的行、列是两个df的并集。缺失的值会显示为np.ana,这个时候为了保证操作的正确无误,有两种方式进行弥补
- 在运算操作后通过
np.where(.isna())进行检查,检查是否产生了nan值 - 将
nan进行补足-
df.fillna(),直接进行补足 - 通过
灵活算数方法进行算数运算,这些方法都是df对象的方法,其参数中可以设置对nan的填充值,例如:df1.add(df2, fill_value=10086)
-
Next:Pandas的排序
问题描述
有时候需要根据索引进行排序,例如处理股票时间序列的时候。有时候需要根据值进行排序。
问题解决
- 对于索引值排序,可以使用
pd.sort_index方法,该方法也支持对象方法
a = pd.DataFrame(np.random.randint(0,2,(4,3)), index=['a','b','c','d'], columns=['hch','hqz','ls'])
print(a)
# output
hch hqz ls
a 0 0 1
b 0 1 1
c 0 1 1
d 1 1 0
设置按照column进行排序,axis=0 or 1对应的是行或列,ascending 设置升序降序
a.sort_index(axis=1, ascending=True)
# output
hch hqz ls
a 0 0 1
b 0 1 1
c 0 1 1
d 1 1 0
- 对值进行排序,通过
pd.sort_values方法,该方法最重要的是by参数,其能够根据某个列的值进行排序。当然by=list输入多个列也是可行的,对于前一个列中相等的元素,其会继续根据下一个列进行排序
a.sort_values(by=['hch', 'hqz'])
# output
# 可以看到,再hch和hqz的列中,元素值大大小都是按照升序进行排列的
hch hqz ls
a 0 0 1
b 0 1 1
c 0 1 1
d 1 1 0
Next:统计Pandas中的数量信息
问题描述
有时候会遇到如下问题:
- 统计pandas中究竟有哪些数,集合是什么
- 统计pandas中数出现的频率,需要画出分布图
- 需要统计一些数据是否存在于
dataframe中,如果存在的话,又是在哪里
问题解决
其实pandas有很好的函数可以解决这些问题,分别是
-
unique函数,用于返回dataframe值的集合,返回Series -
values_count函数,用于统计每个数值究竟出现了多少次 -
isin函数,用于统计特定的数值是否出现在了了df之中,除此之外,isin函数还可以用来生成mask矩阵,例如在训练的时候,那些为nan的值则不需要贡献loss
案例1:从前,如果要统计函数值的集合,不知道这个方法时,我的做法很笨拙,如下
a = pd.DataFrame(np.random.randint(0,2,(4,3)))
0 1 2
0 1 1 1
1 0 1 0
2 0 0 0
3 1 1 1
# 首先将其dataframe的 值 转换为Series
values = a.values.reshape(-1)
values = a.values.ravel()
unique_val = set(values) # 转换为集合
count = dict() # 构建字典
for value in unique_val:
count[value] = np.count_nonzero(values==value) # 统计频次
print(count)
# output
{0: 4, 1: 8}
可以看到,这种方法真的非常的笨拙,现在的方法两步就可以做成,但需要注意:pd.values_count方法只能够对1维数组进行操作,所以在进行操作前需要先转换维度
values = np.unique(a) # 获得数值的集合
count = pd.value_counts(a.values.ravel()) # 统计频率
print(count, type(count))
# output
# count是一个Sereis,键是数值,值是数值出现的频率
1 8
0 4
dtype: int64 <class 'pandas.core.series.Series'>
可以看到,这种方法明显简单很多很多
案例2:查看数据是否存在于数组dataframe之中,如果存在,具体在什么位置,可以运用isin的方法,这种方法的好处是能够同时查找多个值是否在dataframe之中!!
a = pd.DataFrame(np.random.randint(0,4,(4,3)))
print(a)
# output
0 1 2
0 3 2 2
1 0 2 2
2 0 3 3
3 0 3 1
# 运用isin方法进行查找
values = [1,2] # 待查找元素
bull_mat = a.isin(values) # 进行查找,返回的是一个布尔值矩阵,如果对应位置的元素是需要被查找的元素,则返回True
loc = np.where(bull_mat) # 获得定位!
print(bull_mat)
print(loc)
# output
0 1 2
0 False True True
1 False True True
2 False False False
3 False False True # 布尔矩阵,是否为待查找目标值
(array([0, 0, 1, 1, 3]), array([1, 2, 1, 2, 2])) # 位置
当然,如果只是为了查找单个元素的话,完全可以通过np.where[condition]的方法进行查找。np.where[a==1]就是获得了元素为1的位置
当然,isin方法的作用还不止于此,例如其还可以获得mask矩阵(本质就是多值查找)
a = pd.Series(np.arange(12,).reshape(-1))
a
# output
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
dtype: int64
# 通过isin获得布尔值矩阵
a.isin([1,2]) # 1,2的位置,True定位
# output
0 False
1 True
2 True
3 False
4 False
5 False
6 False
7 False
8 False
9 False
10 False
11 False
dtype: bool
# 转换为数值
a.isin([1,2]) + 0
# output
0 0
1 1
2 1
3 0
4 0
5 0
6 0
7 0
dtype: int64
这样,我们就找到了数值的定位
Next:apply与applymap操作
问题描述
之前不了解,当要执行同一种性质的操作的时候,傻傻的用for循环去循环dataframe,依次执行,这样子效率比较低
问题解决Pandas提供了apply, applymap操作,支持灵活的对每一行/列,甚至每个元素执行操作。当然,在DataFrame进行一些比较基本的数值运算时,用此方法可能显得有些多此一举,因为我们完全可以通过numpy中的数值操作,但是如果是一些其他类型的元素操作,字符串操作,那么这种方法就会很方便
- 面对数值操作时,比如下面,对每一行求
min_max_norm
a = np.arange(12).reshape(3,4)
a
# output
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
# min_max_norm
diff = lambda x: (x - x.min())/(x.max()-x.min()) # 标准化
a.apply(diff, axis=1) # 对每一行进行标准化
# output
0 1 2 3
0 0.0 0.333333 0.666667 1.0
1 0.0 0.333333 0.666667 1.0
2 0.0 0.333333 0.666667 1.0
当然,完全也可以这样
data = (data-data.min(axis=1))/(data.max(axis=1)-data.min(axis=1))
- 如果是对非数值元素进行运算,那么
applymap的优势就体现出来了,例如在下面,我想知道每个元素的字符串长度都是多少
a = pd.DataFrame([['hch', 'hqz']]*2)
a
len_is = lambda x: len(x)
a.applymap(len_is)
add = lambda x: x+'loves each other'
a.apply(add, axis=0)
# output
0 1
0 hch hqz
1 hch hqz
0 1
0 3 3
1 3 3
0 1
0 hch loves each other hqz loves each other
1 hch loves each other hqz loves each other
真的非常好用啊!
当然,要注意,apply, applymap仅仅只是dataframe的映射操作,而Index, Series这两个对象也有对应的映射操作方法,其语法都是map,这个的话以后遇到会慢慢说
-
Series的map操作除了接受匿名函数,还接受字典作为输入,当以字典为输入时,输出的就是键值对对应的值
Next:缺失值的填充fillna, dropna, isna系列
Next:重复值的操作,duplicate, drop_duplicates
Next:替代值操作,replace
问题描述
不用再继续用data[condtion] = value,这样非常笨拙,应该用data.replace(values, new_values)操作
Next:归一化
问题描述
数据的归一化
问题解决
以min max norm为例,如果是对每一列作归一化,方法如下:
df
norm_df = (df - df.min(axis=0))/(df.max(axis=0)-df.min(axis=0))
但是,如果是对每一行做min max norm归一化,这种方法就会错误,因为他违反了numpy的广播机制。df.max(axis=1)最后产生的是一个形状为(rows, )的一维素组,根据广播机制
- 不满足后缘维度相同
- 后缘维度不为1
因此无法进行广播机制,会产生报错,这个时候有两种做法
- 扩充维度,将变形后的df维度变为二维,且最后一个维度为1
- 用
apply函数
df
# method 1
min_ = df.min(axis=1).reshape(-1,1)
max_ = df.max(axis=1).reshape(-1.1)
df - min_ / max_ - min_
# method 2
norm = lambda x: x.min() / x.max() - x.min()
df.apply(norm, 1, df)
以上,问题完美解决