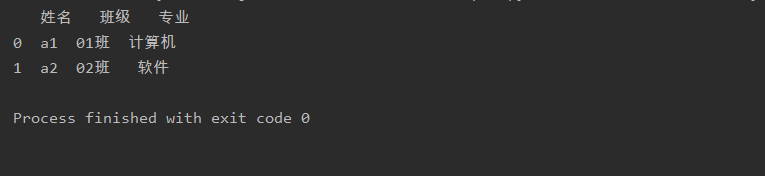
读取Excel工作簿数据
import pandasas pd
a= pd.read_excel('test.xlsx',sheet_name=0)print(a) sheet_name指定从哪个工作表中读取数据
sheet_name指定从哪个工作表中读取数据
注意:演示为工作簿于代码文件在同一个文件夹下如果两者的文件路径不同,则需要将第1个参数设置为绝对路径,
如'D:\\Excel\\text.xlsx'。
指定读取数据的列标签
通过设置参数header来指定使用数据表的第几行(从0开始计数)的内容作为列标签。
import pandasas pd
a= pd.read_excel('test.xlsx',sheet_name=0,header=0)print(a)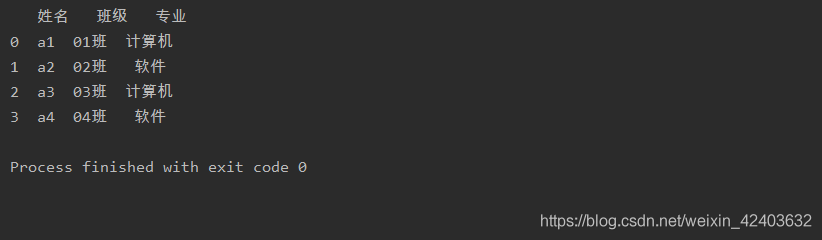
如果将参数header的值设置为1,则使用数据表第2行的内容作为列标签。
import pandasas pd
a= pd.read_excel('test.xlsx',sheet_name=0,header=1)print(a)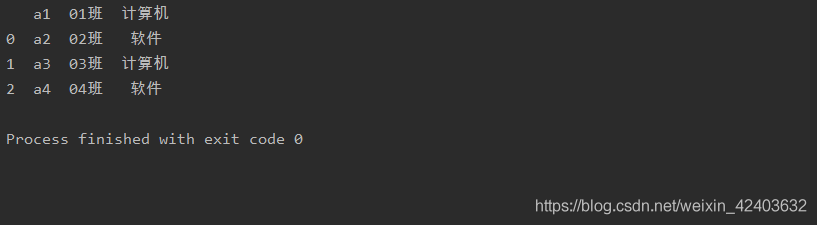
将参数header设置为None,则列标签为从0开始的数字序列
import pandasas pd
a= pd.read_excel('test.xlsx',sheet_name=0,header=None)print(a)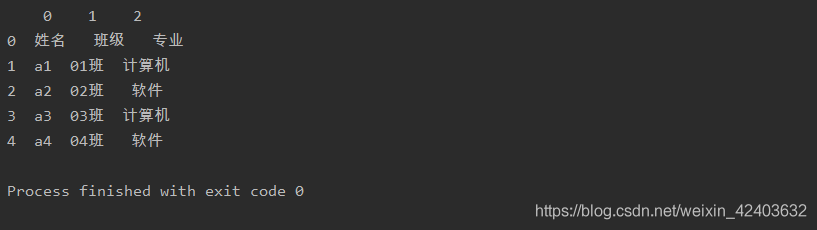
指定读取数据的行标签
index_col用于指定使用数据表的第几列(同样是从0开始计数)的内容作为行标签
import pandasas pd
a= pd.read_excel('test.xlsx',sheet_name=0,index_col=1)print(a)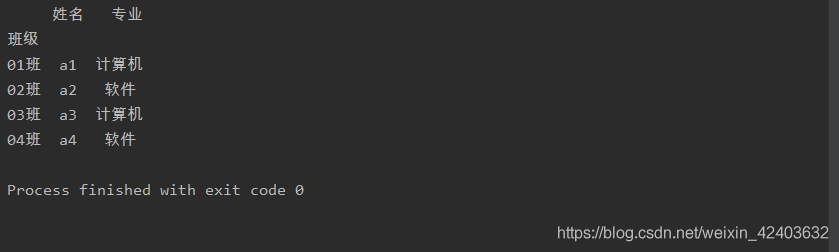
读取指定列
usecols指定要读取的列
import pandasas pd
a= pd.read_excel('test.xlsx',sheet_name=0,usecols=[0])print(a)
读取多列
import pandasas pd
a= pd.read_excel('test.xlsx',sheet_name=0,usecols=[0,2])print(a)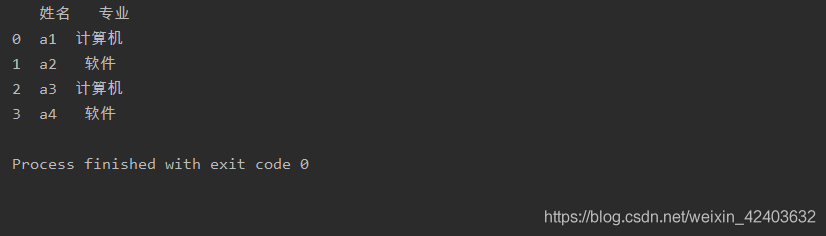
读取指定行数
nrows控制读取数据的行数
import pandasas pd
a= pd.read_excel('test.xlsx',sheet_name=0,nrows=2)print(a)