一、背景
很多运营小giegie都需要根据录音的停顿进行音频剪辑,我们完全可以借助一些现成的软件解决。
但是,这个giegie给我提出的问题——如何用python批量切割音频??emmm…奈何老Amy并没有接触过阿~硬着头皮就是整!
二、老Amy花了1小时打开任督六脉
1.使用代码读取音频
首先,我得找到python 中最便于切割音频的库。于是在一顿检索中就发现pydub.silence.split_on_silence是可以利用语音停顿进行切分的。
于是看好pydub这个库,首先通过pip install pydub 进行安装。然后输入以下代码
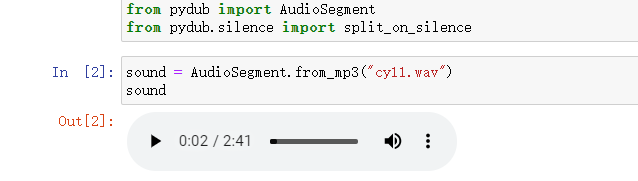
from pydub import AudioSegment
AudioSegment.from_mp3("cy11.wav")结果!就报错了,你敢想他竟然说的是"文本未找到"???路径我是写的一点问题也没有,这整的我是两脸懵逼~
2.解决报错——安装ffmpeg
于是我又开始解决错误,发现pydub 依赖于ffmpeg 这个库。所以我又通过pip install ffmpeg安装ffmpeg ,额滴神!运行代码还是报错。
经过一系列的搜索,发现ffmpeg 不是直接pip install 那么简单,需要操作如下:
- 1.需要到
ffmpeg官网下载 ,如:https://www.gyan.dev/ffmpeg/builds/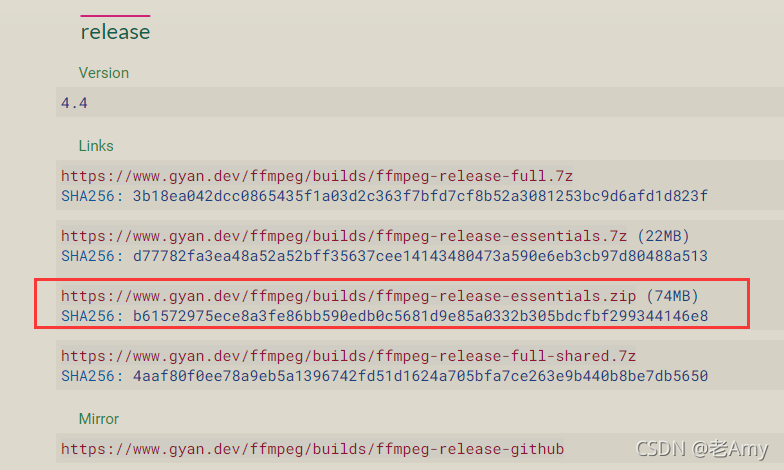
- 2.将刚刚下载的
ffmpeg下的bin配置到系统环境变量中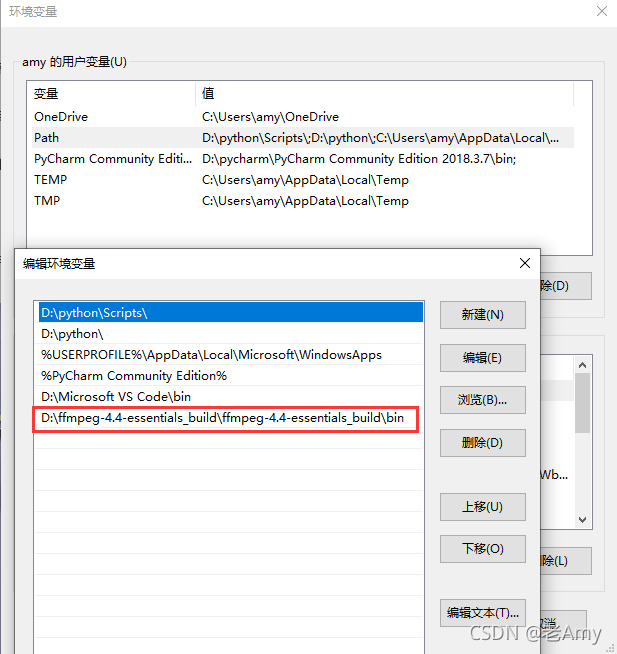
OK!此时我再重新运行代码。以为大功告成,谁知还是报错了~
我又开始漫长的搜索,看到有博主说将bin 下的三个程序添加到代码同级文件夹下。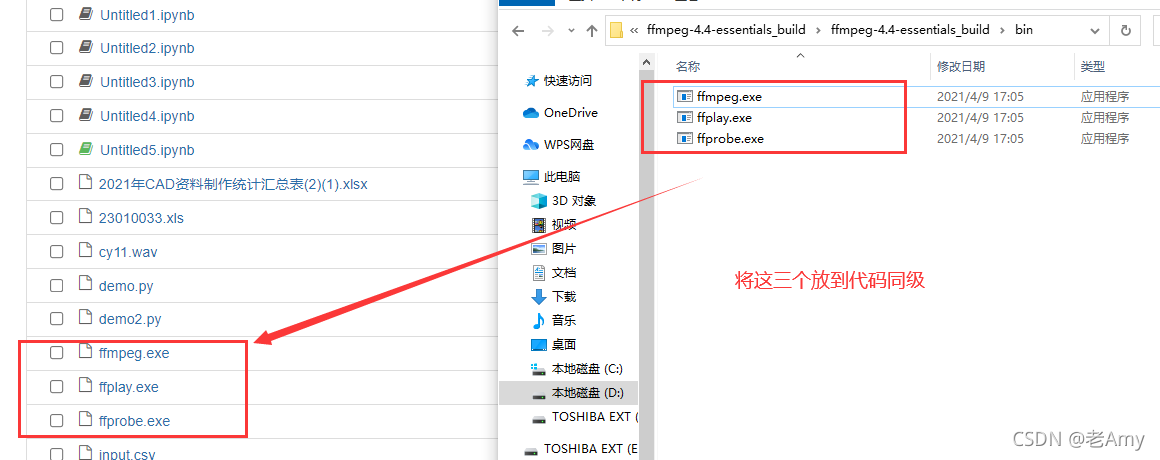
结果运行~奥耶!可以了。