文章目录
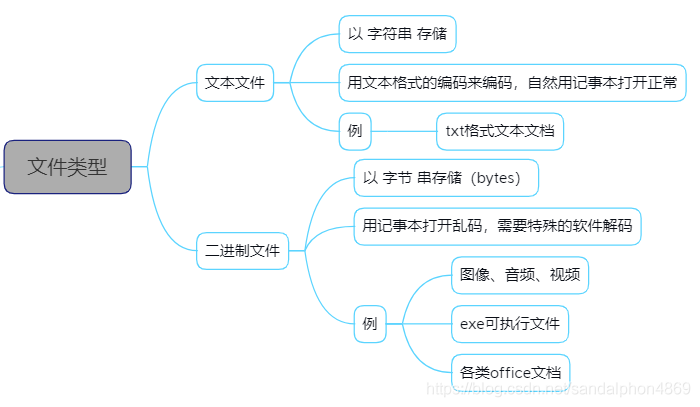
一、文件类型
二、常用操作
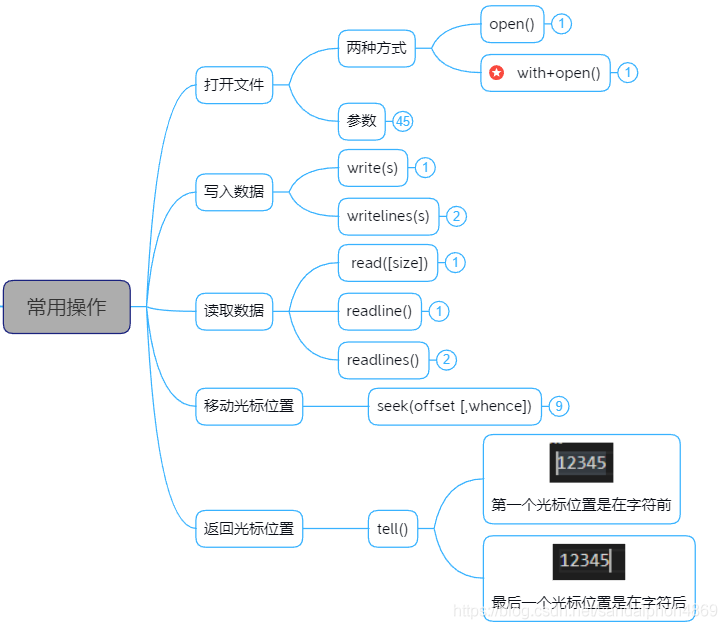
1.打开文件
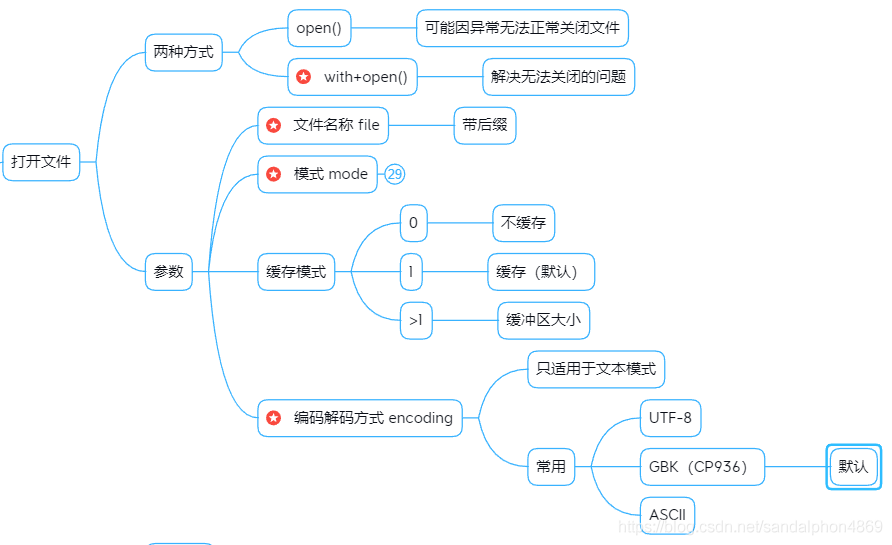
1.1open函数
open(file, mode='r', buffering=-1, encoding=None,
errors=None, newline=None, closefd=True, opener=None)- file:文件名称
- mode:文件处理方式
- buffering:读写文件的缓存模式。
- encoding:对文本进行编码和解码的方式
1.2参数:模式 mode
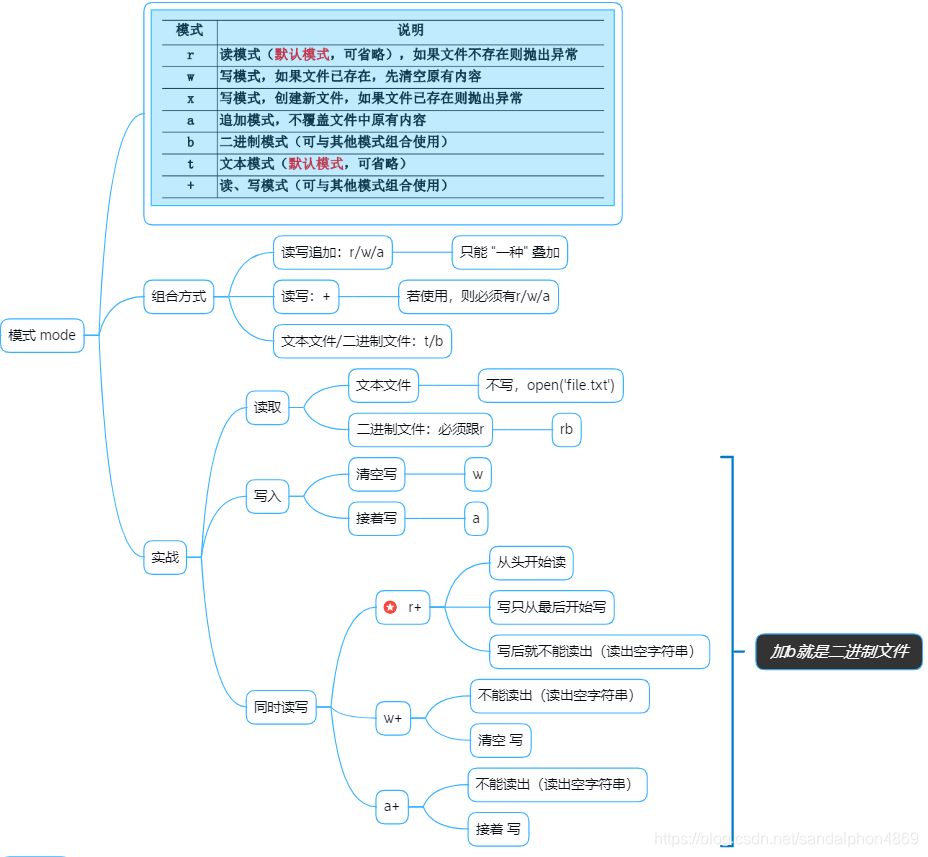
文件内容:
12345# 同时读写之r+ : 写后就不能读出(读出空字符串)withopen('file.txt','r+', encoding="utf-8")as fp:
str1= fp.read(4)print(str1)
fp.write('hello')
str2= fp.read(4)print(str2)
fp.write('world')"""
1234
"""2.写入数据
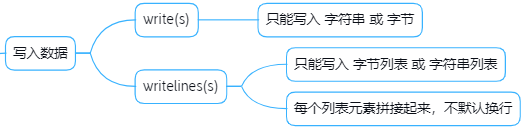
# 写入数据之writelines(s) : 每个列表元素拼接起来,不默认换行withopen('file.txt','w')as fp:
p=['123','456']
fp.writelines(p)
q=['abc\n','cde']
fp.writelines(q)"""
123456abc
cde
"""# str to bytes
s_to_b=str.encode(s)# bytes to str
b_to_s=bytes.decode(b)3.读取数据
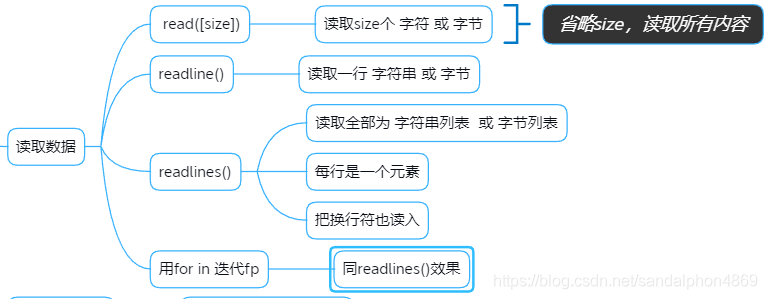
# readlines() : 读入换行符"""
12345
1234
"""withopen('file.txt','r')as fp:for linein fp.readlines():print(line)"""
12345
1234
"""# 用for in 迭代fp"""
12345
1234
"""withopen('file.txt','r')as fp:for linein fp:print(line)"""
12345
1234
"""4.移动光标位置
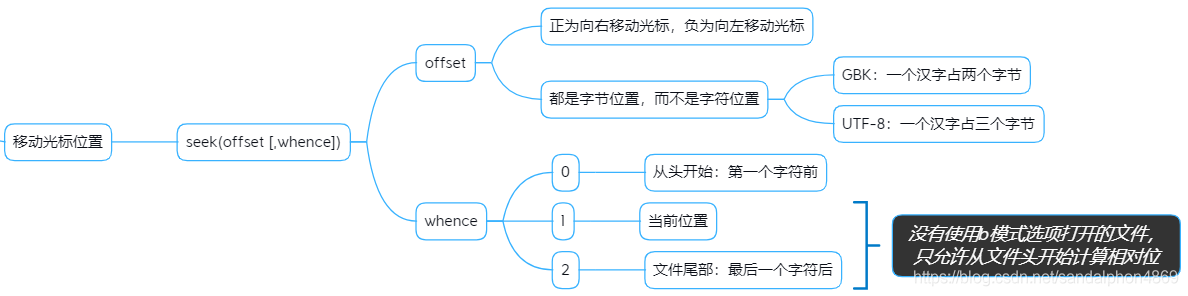
# 倒着读"""
12345
"""# 倒着读得用b模式withopen('file.txt','rb')as fp:
fp.seek(-3,2)# 这是字节串
b= fp.readline()# 解码为字符串
s= b.decode()print(s)"""
345
"""5.返回光标位置
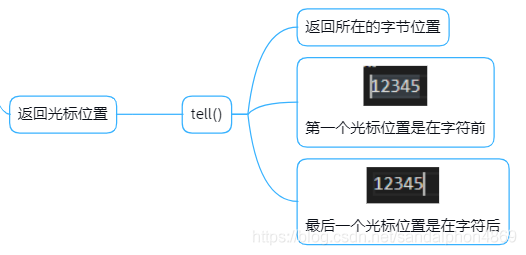
# GBK:一个汉字占两个字节"""
中国馆
"""withopen('file.txt','r')as fp:print(fp.read(1))print(fp.tell())print(fp.read(1))print(fp.tell())print(fp.read(1))print(fp.tell())"""
中
2
国
4
馆
6
"""# UTF-8:一个汉字占三个字节"""
中国馆
"""withopen('file.txt','r', encoding='utf-8')as fp:print(fp.read(1))print(fp.tell())print(fp.read(1))print(fp.tell())print(fp.read(1))print(fp.tell())"""
中
3
国
6
馆
9
"""# 读取(r)文件(file.txt)withopen('file.txt','r', encoding="utf-8")as fp:# 以列表形式储存每一行,包括带着换行符'\n'
lines= fp.readlines()# 共有多上行
file_lines=len(lines)
lines=[# index从0开始,我们要的行号从1开始str(index+1)+':'+ line# 获得每一行的下标和列表元素(即每行内容)for index, lineinenumerate(lines)]# 写入新文件(w)withopen('file_new.txt','w', encoding="utf-8")as fp:# 第一行的内容:总共多少行再加上换行
fp.write(str(file_lines)+'\n')
fp.writelines(lines)# 写入数据 : 每个列表元素拼接起来,不默认换行withopen('file.txt','rb')as fp:
fp.seek(-2,2)print(fp.read(1))"""
b'4'
"""三、序列化模块:针对二进制文件
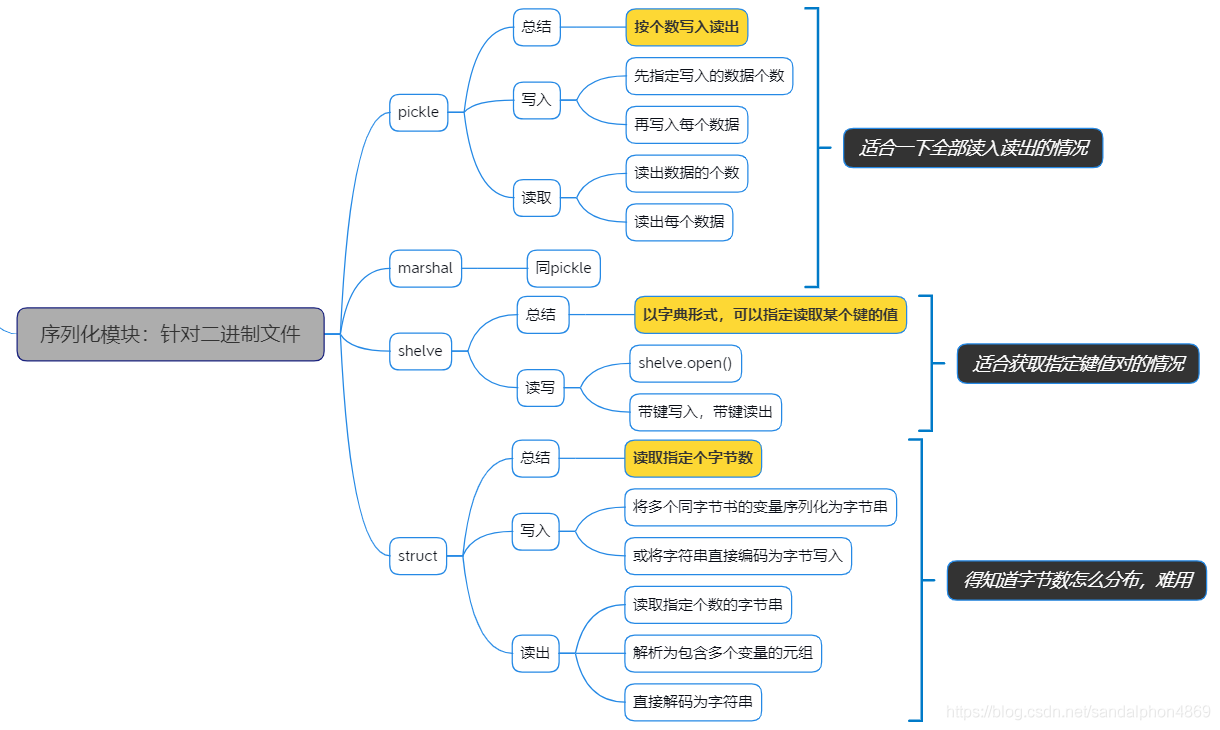
1.pickle
import pickle# 各种类型的数据
i=13000000
a=99.056
s='中国人民123abc'
lst=[[1,2,3],[4,5,6],[7,8,9]]
tu=(-5,10,8)
coll={4,5,6}
dic={'a':'apple','b':'banana','g':'grape','o':'orange'}# 将不同类型的数据放入到列表中
data=[i, a, s, lst, tu, coll, dic]# 用二进制形式(b)写入(w)文件(sample_pickle.dat)withopen('sample_pickle.dat','wb')as f:try:# 表示后面将要写入的数据个数
pickle.dump(len(data), f)for itemin data:# 写入每个数据内容
pickle.dump(item, f)except:print('写文件异常!')#如果写文件异常则跳到此处执行# 用二进制形式(b)读取(r)文件(sample_pickle.dat)withopen('sample_pickle.dat','rb')as f:
n= pickle.load(f)#读出文件的数据个数for iinrange(n):# 读取每个数据内容
x= pickle.load(f)print(x)"""
13000000
99.056
中国人民123abc
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
(-5, 10, 8)
{4, 5, 6}
{'a': 'apple', 'b': 'banana', 'g': 'grape', 'o': 'orange'}
"""2.marshal
import marshal#导入模块# 待序列化的对象
x1=30
x2=5.0
x3=[1,2,3]
x4=(4,5,6)
x5={'a':1,'b':2,'c':3}
x6={7,8,9}# 将这些都整合成一个列表
x=[eval('x'+str(i))for iinrange(1,7)]# 用二进制形式(b)写入(w)文件(marshal_test.dat)withopen('marshal_test.dat','wb')as fp:
marshal.dump(len(x), fp)#先写入对象个数for itemin x:
marshal.dump(item, fp)# 用二进制形式(b)读取(r)文件(marshal_test.dat)withopen('marshal_test.dat','rb')as fp:
n= marshal.load(fp)#获取对象个数for _inrange(n):print(marshal.load(fp))#反序列化,输出结果"""
30
5.0
[1, 2, 3]
(4, 5, 6)
{'a': 1, 'b': 2, 'c': 3}
{8, 9, 7}
"""3.shelve
import shelve# 字典
zhangsan={'age':38,'sex':'Male','address':'SDIBT'}
a=123# 注意是用shelve.open,而不是open。flag打开数据存储文件的参数也不一样。# 会直接生成三个文件:.bak、.dat、.dirwith shelve.open('shelve_test.dat')as fp:# 像操作字典一样把数据写入文件
fp['zhangsan']= zhangsan
fp['a']= a# 注意也是用shelve.open,而不是open。with shelve.open('shelve_test.dat')as fp:# 像操作字典一样读取并显示文件内容# 读取字典zhangsanprint(fp['zhangsan'])print(fp['zhangsan']['age'])# 读取变量aprint(fp['a'])"""
{'age': 38, 'sex': 'Male', 'address': 'SDIBT'}
38
123
"""4.struct
import struct
n=1300000000
x=96.45
b=True# 按UTF-8的形式,一个汉字3个字节
s='中国@qq.com'# 序列化
sn= struct.pack('if?', n, x, b)# 用二进制形式(b)写入(w)文件(sample_struct.dat)withopen('sample_struct.dat','wb')as fp:# 写入字节串
fp.write(sn)# 字符串直接编码为字节串写入
fp.write(s.encode())# 用二进制形式(b)读取(r)文件(sample_struct.dat)withopen('sample_struct.dat','rb')as fp:# 读取9个字节
sn= fp.read(9)# 元组形式
tu= struct.unpack('if?', sn)print(tu)# 解析元组
n, x, bl= tuprint('n=', n)print('x=', x)print('bl=', bl)# 读取9个字节串,解析为字符串
s= fp.read(13).decode()print('s=', s)"""
(1300000000, 96.44999694824219, True)
n= 1300000000
x= 96.44999694824219
bl= True
s= 中国@qq.com
"""Reference
utf-8 和 cp936的区别
使用seek()方法报错:“io.UnsupportedOperation: can’t do nonzero cur-relative seeks”错误的原因
ur2i