学习致谢
https://www.bilibili.com/video/BV1Xz4y1m7cv?p=65
代码实现
(1)pom文件导入spark-hive依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>2.3.2</version></dependency>(2)注意:需要先启动Hive的metastore
nohup /export/server/hive/bin/hive --service metastore&(3)编写代码
packagesqlimportorg.apache.spark.sql.expressions.UserDefinedFunctionimportorg.apache.spark.sql.{Dataset, SparkSession}/**
* Author itcast
* Desc 演示spark-SQL-使用SparkSQL-UDF将数据转为大写
* */object Demo09_Hive{def main(args: Array[String]):Unit={//TODO 0.准备环境---需要增加参数配置和开启hivesql语法支持val spark= SparkSession.builder().appName("sparksql").master("local[*]").config("spark.sql.shuffle.partitions","4").config("spark.sql.warehouse.dir","hdfs://node1:8020/user/hive/warehouse")//指定Hive数据库在HDFS上的位置.config("hive.metastore.uris","thrift://node2:9083").enableHiveSupport()//开启对Hive语法的支持.getOrCreate()//本次测试时分区数设置小一点,实际开发中可以根据集群规模设置大小val sc= spark.sparkContext
sc.setLogLevel("WARN")importspark.implicits._//TODO 1.操作Hive
spark.sql( sqlText="show databases").show( truncate=false)
spark.sql( sqlText="show tables").show( truncate=false)
spark.sql(sqlText="CREATE TABLE person4(id int,name string, age int)row format delimited fields terminated by ' '")
spark.sql( sqlText="LOAD DATA LOCAL INPATH 'file:///D:/person.txt’ INTO TABLE person4")
spark.sql( sqlText="show tables").show( truncate=false)
spark.sql( sqlText="select * from person4").show( truncate=false)
spark.close()}}演示
(1)运行代码之前查看hdfs hive中的表只有三个,如图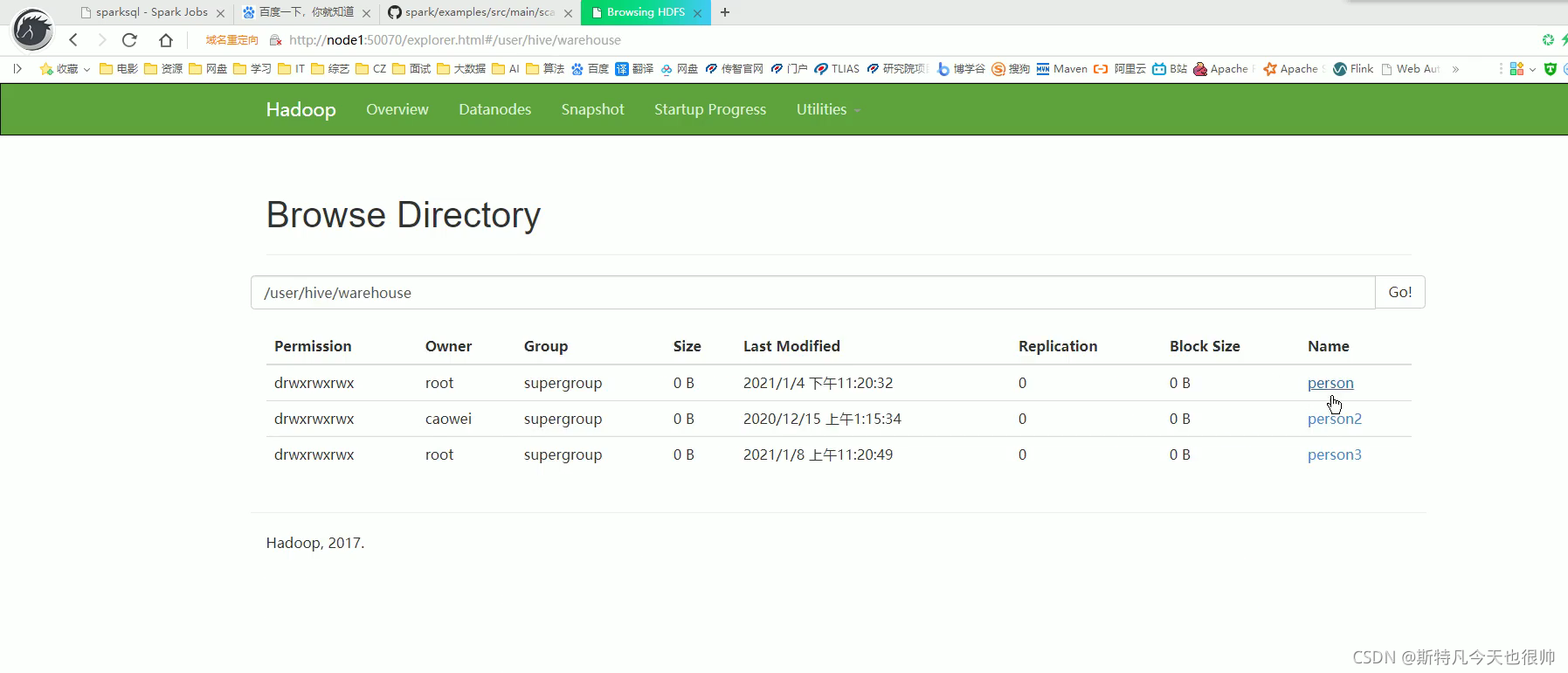
(2)运行程序
可以依次看到hivesql的执行结果
查看数据库和表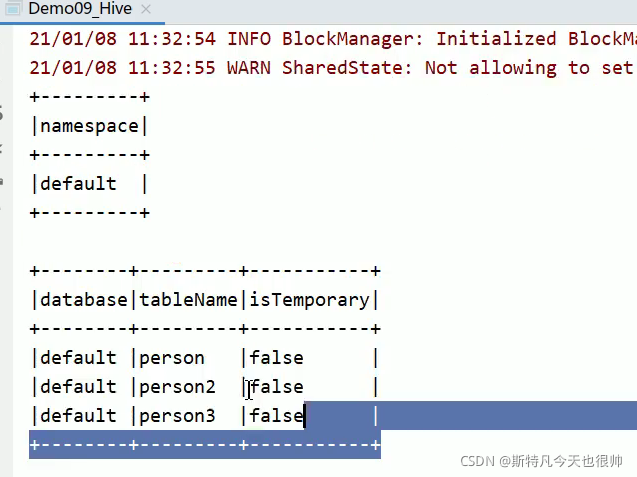
新建表person4并查看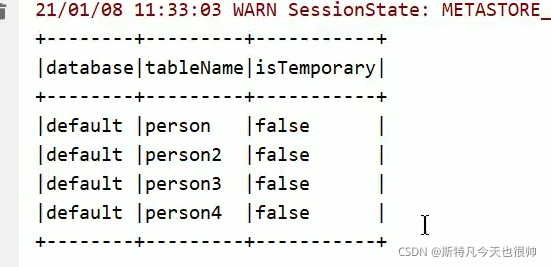
插入数据并查询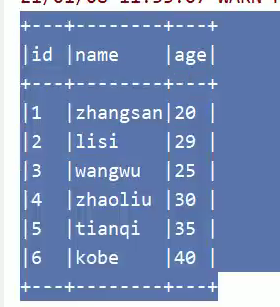
(3)在HDFS端 查看hive中的表,可以看到已经新增表person4