对于分类模型,在建立好模型后,我们想对模型进行评价,常见的指标有混淆矩阵、KS曲线、ROC曲线、AUC面积等。也可以自己定义函数,把模型结果分割成n(100)份,计算top1的准确率、覆盖率。
本文详细阐述混淆矩阵的原理和Python实现实例,其它指标会在后续文章中详尽阐述,敬请期待。
文章目录
一、什么是混淆矩阵
混淆矩阵是用于评价分类模型效果的NxN矩阵,其中N是目标类别的数目。矩阵将实际类别和模型预测类别进行比较,评价模型的预测效果。比如样本的实际类别是狗,若模型预测类别也是狗,则说明对于该样本模型预测对了。若模型预测类别为猫,则说明对于该样本模型预测错了。对全部样本数据进行统计,可以判断模型预测对了的样本数量和预测错了的样本数量,从而可以衡量模型的预测效果。
二、混淆矩阵有关的三级指标
1 一级指标
以分类模型中最简单的二分类为例。假如我们有一批顾客是否买某种产品的样本数据,顾客买了产品我们标记为positive,没买标记为negative。现在通过分类模型训练这批样本,根据模型结果可以知道模型认为哪些顾客会买(预测的positive),哪些顾客不会买(预测的negative)。因此我们可以得到以下四个一级指标:
TP(True Positive):真实值是positive,模型认为是positive的数量,即模型预测正确的正例数量。
FN(False Negative):真实值是positive,模型认为是negative的数量,即模型预测错误的正例数量,这是统计学上的第二类错误(Type II Error)。
FP(False Positive):真实值是negative,模型认为是positive的数量,即模型预测错误的负例数量,这是统计学上的第一类错误(Type I Error)。
TN(True Negative):真实值是negative,模型认为是negative的数量,即模型预测正确的负例数量。
将这四个指标统计到一个矩阵表格中,就得到了混淆矩阵(Confusion Matrix)。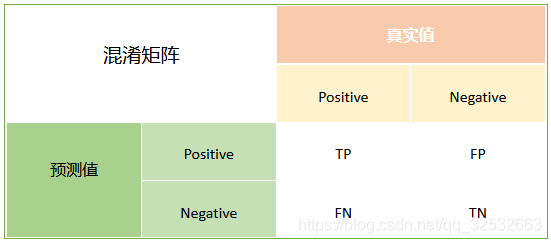
为了便于大家记忆,可以把混淆矩阵中的P和N看成模型的预测结果positive和negative,这里的positive和negative不表示好和坏,只表示模型的类别1(positive)和0(negative)。T和F看成模型预测是否正确,模型预测正确标记为T,预测错误标记为F。比如TP表示模型预测为positive,且模型预测正确的样本数量,即样本实际类别为positive,模型预测类别为positive的样本数量。FP表示模型预测为positive,且模型预测错误的样本数量,即样本实际类别为negative,模型错误地预测成了positive的样本数量。
2 二级指标
对于预测性分类模型,我们希望模型的预测结果越准越好,即混淆矩阵中TP、TN的值越大越好,相应FP、FN的值越小越好。但是,混淆矩阵里统计的是数量,在数据量很大的情况下很难一眼判断出模型的优劣。因此,在混淆矩阵的基本统计结果上又衍生了如下4个指标(可以理解为二级指标,类似于特征工程里的衍生变量):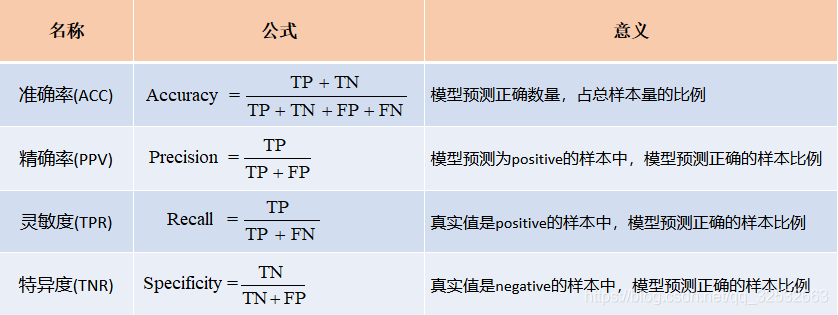
通过上面的四个二级指标,可以将混淆矩阵中的数量结果转化为0-1之间的比率,便于我们直观地对模型进行评价。在这四个指标的基础上进行衍生,还可产生一个三级指标。
3 三级指标
这个三级指标就是统计学中F1-Score,计算公式如下: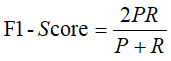
其中,P表示精确率(Presicion),R表示召回率(Recall),即灵敏度。F1-Score的取值范围(0~1),越接近1说明模型预测效果越好。
三、计算混淆矩阵的实例
当分类问题是多分类时,只要把其中一类当成一组,另外的所有类当成另一组,就可以转化成二分类问题,接下来讲一个二分类计算混淆矩阵三级指标的具体实例。假设我们模型的目的是预测一批顾客是否会购买某种产品,我们的结果如下: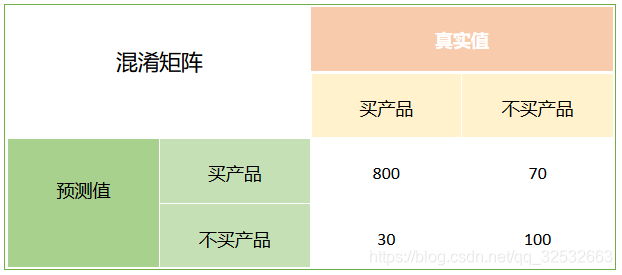
1 一级指标
TP(True Positive):真实值是买产品,模型认为是买产品的顾客数量,即模型预测正确的正例数量,在该例中值为800。
FN(False Negative):真实值是买产品,模型认为是不买产品的顾客数量,即模型预测错误的正例数量,在该例中值为30。
FP(False Positive):真实值是不买产品,模型认为是买产品的顾客数量,即模型预测错误的负例数量,在该例中值为70。
TN(True Negative):真实值是不买产品,模型认为是不买产品的数量,即模型预测正确的负例数量,在该例中值为100。
2 二级指标
准确率(Accuracy):总共1000个顾客,我们一共预测对了800+100=900个样本,所以准确率为90%。
精确率(Precision):模型结果告诉我们,1000个顾客里有870个顾客会买产品,但其实这870个顾客里只有800个顾客实际买了产品,70个顾客没有买产品。所以,精确率为800/870=91.95%。
灵敏度/召回率(Recall):在830个实际购买了产品的顾客中,模型认为有800个顾客会购买产品,30个顾客不会购买产品,所以召回率为800/830=96.38%。
特异度(Specificity):在170个实际不买产品的顾客中,模型认为有100个不会购买产品,70个会购买产品,所以特异度为100/170=58.82%。
3 三级指标
通过公式,可以计算出F1-Score=(2*91.95%*96.38%)/(91.95%+96.38%)=0.94
四、用Python计算混淆矩阵并图形展示
接下来展示模型判断一批商户是否存在赌博风险的数据,利用这批数据绘制混淆矩阵。flag列是真实标签,1代表商户存在赌博行为,0代表商户不存在赌博行为。pred列是模型预测标签,1代表模型预测商户存在赌博行为,0代表模型预测商户不存在赌博行为。
1 加载包
import pandasas pdimport matplotlib.pyplotas pltimport numpyas npfrom sklearn.linear_modelimport LogisticRegressionfrom sklearn.model_selectionimport KFold, cross_val_scorefrom sklearn.metricsimport confusion_matrix, recall_score, classification_report2 加载数据
#加载数据%matplotlib inline
date= pd.read_csv("data.csv", encoding="gbk")打印数据前几行,得到如下结果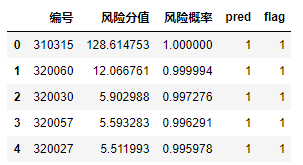
注:如需上述数据实现本文代码,可在公众号中回复“混淆矩阵”,即可免费获取。
我们可以根据模型的风险概率(prob)和想要的准确率、覆盖率,人为确定当风险概率大于某个值时模型认为该商户存在赌博风险,当风险概率小于该值时模型认为该商户不存在赌博风险。很多情况下,这个阈值划定为0.5,即模型认为风险概率大于0.5的商户存在赌博风险,小于0.5的商户不存在赌博风险。
一般要根据行业和风险类别确定这个阈值,本文pred划定的阈值为0.7,即当风险概率值大于0.7时模型认为该商户存在赌博风险并标记为1,小于0.7时模型认为该商户不存在赌博风险并标记为0。
3 定义绘制混淆矩阵的函数
defplot_confusion_matrix(cm, classes,normalize=False,title='Confusion matrix',cmap=plt.cm.Blues):"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""if normalize:
cm= cm.astype('float')/ cm.sum(axis=1)[:, np.newaxis]print("Normalized confusion matrix")else:print('Confusion matrix, without normalization')print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks= np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt='.2f'if normalizeelse'd'
thresh= cm.max()/2.for i, jin itertools.product(range(cm.shape[0]),range(cm.shape[1])):
plt.text(j, i,format(cm[i, j], fmt),
horizontalalignment="center",
color="white"if cm[i, j]> threshelse"black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')4 绘制单个混淆矩阵
import itertools
cnf_matrix= confusion_matrix(date.flag, date.pred)#计算混淆矩阵
class_names=[0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix, classes= class_names, title='Confusion matrix')#绘制混淆矩阵
np.set_printoptions(precision=2)print('Accary:',(cnf_matrix[1,1]+cnf_matrix[0,0])/(cnf_matrix[1,1]+cnf_matrix[0,1]+cnf_matrix[0,0]+cnf_matrix[1,0]))print('Recall:', cnf_matrix[1,1]/(cnf_matrix[1,1]+cnf_matrix[1,0]))print('Precision:', cnf_matrix[1,1]/(cnf_matrix[1,1]+cnf_matrix[0,1]))print('Specificity:', cnf_matrix[0,0]/(cnf_matrix[0,1]+cnf_matrix[0,0]))
plt.show()得到结果如下: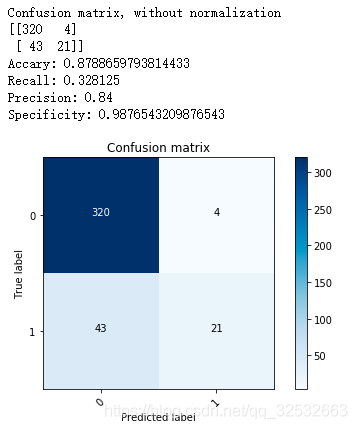
5 设定不同的阈值一次绘制多个混淆矩阵
我把阈值设定成了0.1、0.2一直到0.9,可以看下不同阈值对应的模型准确率、召回率等指标。通过指标数值推测未来排查名单的概率阈值。
import itertools
thresholds=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]#设定不同的阈值
plt.figure(figsize=(10,10))
j=1for iin thresholds:
y_pred= date['风险概率']>i#把风险概率prob和阈值进行比较
plt.subplot(3,3,j)#Compute confusion matrix
j+=1
cnf_matrix= confusion_matrix(date.flag, y_pred)#计算混淆矩阵
np.set_printoptions(precision=2)#Print degree2 indexprint('Accary:',(cnf_matrix[1,1]+cnf_matrix[0,0])/(cnf_matrix[1,1]+cnf_matrix[0,1]+cnf_matrix[0,0]+cnf_matrix[1,0]))print('Recall:', cnf_matrix[1,1]/(cnf_matrix[1,1]+cnf_matrix[1,0]))print('Precision:', cnf_matrix[1,1]/(cnf_matrix[1,1]+cnf_matrix[0,1]))print('Specificity:', cnf_matrix[0,0]/(cnf_matrix[0,1]+cnf_matrix[0,0]))#Plot non-normalized confusion matrix
class_names=[0,1]
plot_confusion_matrix(cnf_matrix, classes= class_names, title='Threshold>=%s'%i)得到结果如下: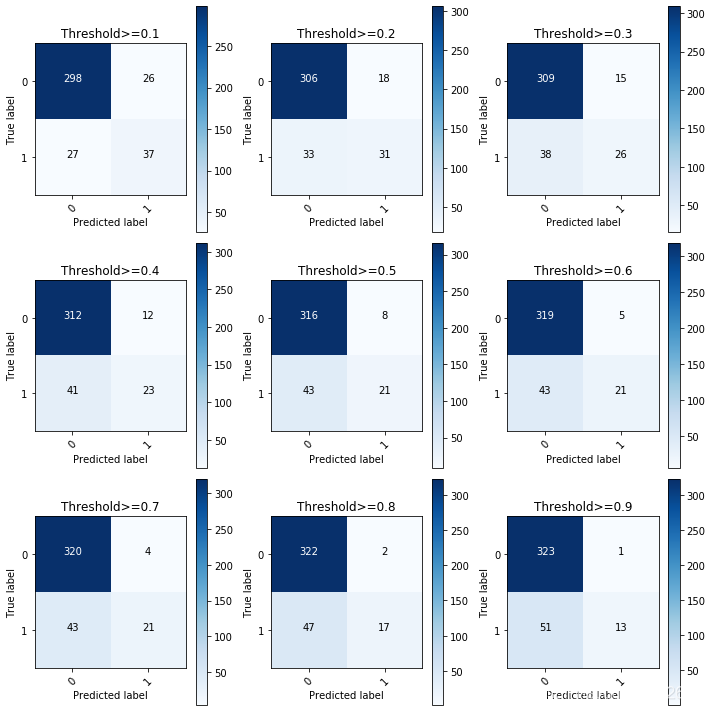
至此混淆矩阵的内容讲解全部结束,如有疑问可以在公众号中私信我。
参考文献
https://zhuanlan.zhihu.com/p/30116307
https://zhuanlan.zhihu.com/p/43492827
https://zhuanlan.zhihu.com/p/59137998
https://zhuanlan.zhihu.com/p/111260930
https://baijiahao.baidu.com/s?id=1639202882632470513&wfr=spider&for=pc
你可能感兴趣:
用Python绘制皮卡丘
用Python绘制词云图
Python画好看的星空图(唯美的背景)
用Python中的py2neo库操作neo4j,搭建关联图谱
Python浪漫表白源码合集(爱心、玫瑰花、照片墙、星空下的告白)