JAVA并发编程-2-线程并发工具类
上一章:看这里JAVA并发编程-1-线程基础
本章主要介绍java.util.concurrent下给我们提供的线程并发工具类的作用和使用场景。
一、Fork/Join
1、分而治之与工作密取
Fork/Join框架体现了分而治之的思想,就是在必要的情况下,将一个大任务进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个小任务运算的结果进行join汇总。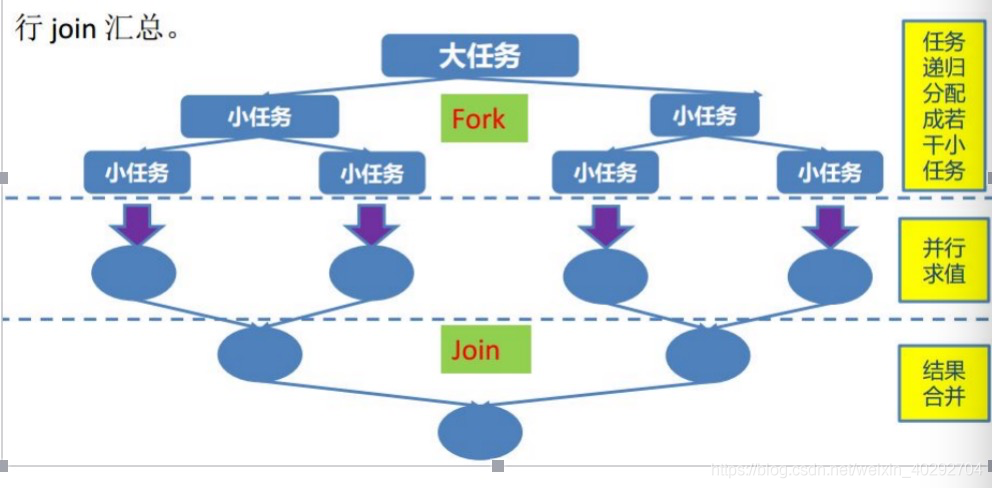
二叉查找树、快速排序算法,Hadoop中的map-reduce都是典型的分而治之思想,相信大家也并不难理解。
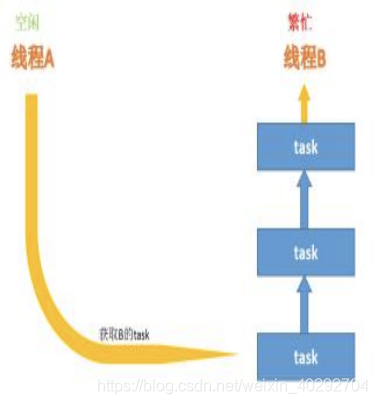
分完之后的结果可以交给不同的线程去执行,并且平均分配。但是并不能保证每个线程分到的任务都同时执行完,也就是说有的线程执行的快,有的执行的慢,而我们期望最终同时得到的是一个join后的结果,所以让执行的快的线程去执行的慢的线程的任务队列的尾部“偷”一个任务来帮它执行,执行的结果还是交给原线程来join,这种机制就是工作密取。
2、使用标准范式
abstract class ForkJoinTask< V> 是forkjoin的基础Task类,他有两个实现:用于同步方法的有返回值的RecursiveTask< V> 和用于异步方法的没有返回值的 RecursiveAction,我们自己的方法要继承自它们,实现对应的compute()方法。
使用流程如下: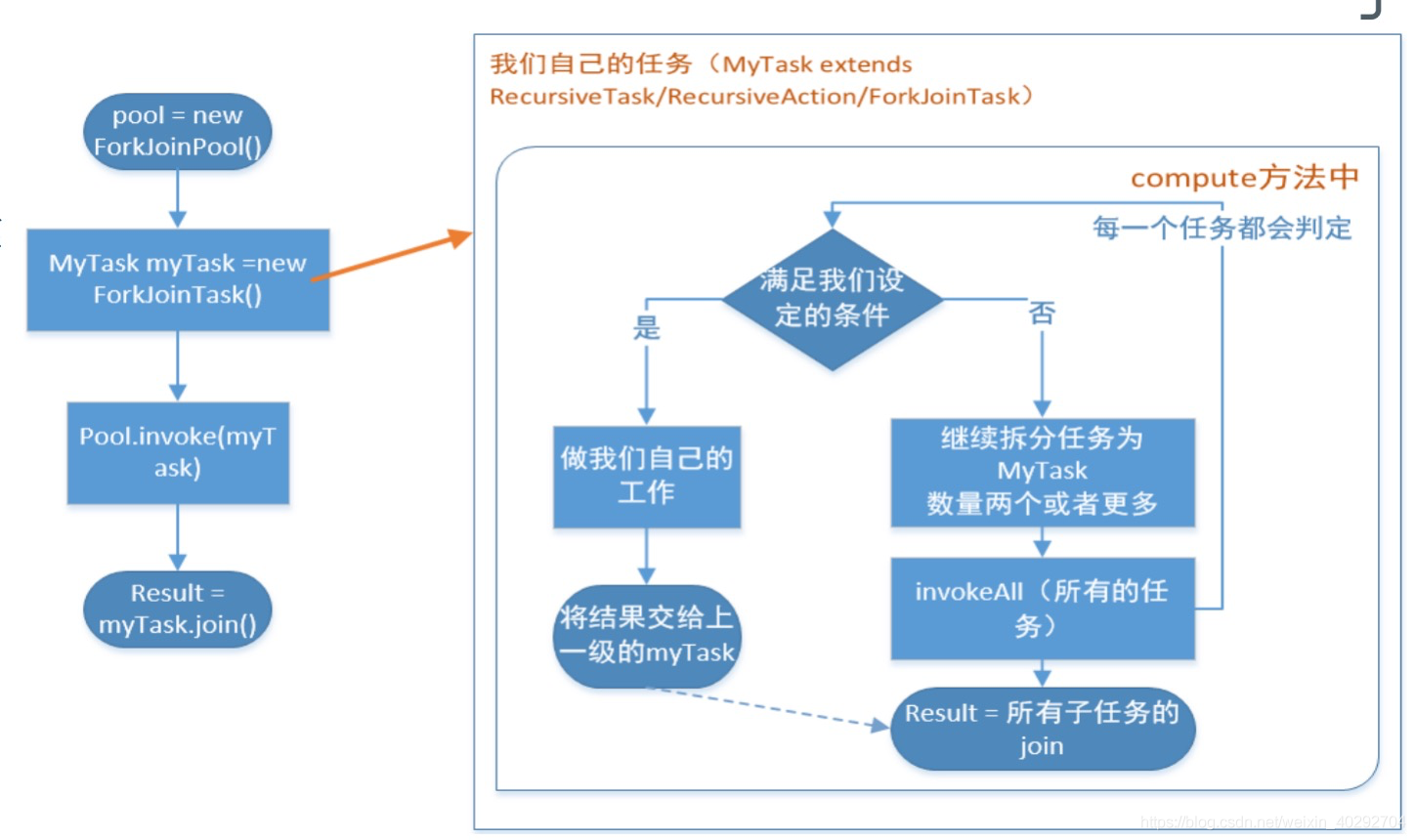
3、Fork/Join的同步用法
下面我们用Fork/Join框架来将10000个数相加,做到每个最终任务只加1000个数,通过Fork/Join体会一下用法。
publicclassSumArray1{publicstaticclassMakeArray{//数组长度publicstaticfinalint ARRAY_LENGTH=10000;publicstaticint[]makeArray(){//new一个随机数发生器
Random r=newRandom();int[] result=newint[ARRAY_LENGTH];for(int i=0; i< ARRAY_LENGTH; i++){//用随机数填充数组
result[i]= r.nextInt(ARRAY_LENGTH*3);}return result;}}publicstaticclassSumTaskextendsRecursiveTask<Integer>{//定义我们最终拆分的任务的数组的最大长度privatefinalstaticint THRESHOLD= MakeArray.ARRAY_LENGTH/10;privateint[] nums;private Integer fromIndex;private Integer endIndex;publicSumTask(int[] nums, Integer fromIndex, Integer endIndex){this.nums= nums;this.fromIndex= fromIndex;this.endIndex= endIndex;}@Overrideprotected Integercompute(){//小于最大限制,说明已经是最终任务,就去执行相加逻辑if(endIndex- fromIndex<= THRESHOLD){int count=0;for(int i= fromIndex; i<= endIndex; i++){//模拟1ms,因为实际执行太快了
SleepTools.ms(1);
count= count+ nums[i];}return count;}else{//如果没达到,就要继续拆分int mid=(endIndex- endIndex)/2;
SumTask left=newSumTask(nums, fromIndex, mid);
SumTask right=newSumTask(nums, fromIndex, mid);invokeAll(left, right);return left.join()+ right.join();}}}publicstaticvoidmain(String[] args){
ForkJoinPool pool=newForkJoinPool();int[] nums= MakeArray.makeArray();
SumTask sumTask=newSumTask(nums,0, nums.length-1);long start= System.currentTimeMillis();
pool.invoke(sumTask);
System.out.println("Task is Running.....");
System.out.println("The count is "+ sumTask.join()+" spend time:"+(System.currentTimeMillis()- start)+"ms");}}在计算的过程中,我们sleep了一秒,主要是为了模拟较复杂的计算过程。因为实际上你会发现,如果单纯的加10000个数,单线程for循环是非常的快的。这个很好理解,一直强调的是,多线程开发是有本身的线程上下文切换等的资源消耗要考虑的,甚至本身消耗的资源和时间是比执行的任务占用的资源和时间还要大,这个时候多线程的执行并不能带来性能上的提升。所以我们在使用多线程进行开发时一定要分析清楚实际的情况,再决定是否要使用多线程。
4、Fork/Join的异步用法
异步方法很好理解,就是不需要子线程的返回值或者子线程执行过程中需要主线程去完成其它的工作。
假设我们要寻找磁盘D上的所有.txt文件并且将文件名输出到控制台,不言而喻的是,一个文件夹下既会有若干文件,又会有文件夹,文件就直接校验它的后缀名,文件夹时将任务再拆分。来看一下具体实现:
publicclassFindDirsFilesextendsRecursiveAction{private File path;//当前任务需要搜寻的目录publicFindDirsFiles(File path){this.path= path;}publicstaticvoidmain(String[] args){try{// 用一个 ForkJoinPool 实例调度总任务
ForkJoinPool pool=newForkJoinPool();
FindDirsFiles task=newFindDirsFiles(newFile("D:/"));
pool.execute(task);//异步调用
System.out.println("Task is Running......");
Thread.sleep(1);int otherWork=0;for(int i=0; i<100; i++){
otherWork= otherWork+ i;}
System.out.println("Main Thread done sth......,otherWork="+ otherWork);
task.join();//阻塞的方法
System.out.println("Task end");}catch(Exception e){
e.printStackTrace();}}@Overrideprotectedvoidcompute(){
List<FindDirsFiles> subTasks=newArrayList<>();
File[] files= path.listFiles();if(files!= null){for(File file: files){if(file.isDirectory()){//文件夹需要再拆分
subTasks.add(newFindDirsFiles(file));}else{//遇到文件,检查if(file.getAbsolutePath().endsWith("txt")){
System.out.println("文件:"+ file.getAbsolutePath());}}}if(!subTasks.isEmpty()){//<T extends ForkJoinTask<?>> Collection<T> invokeAll(Collection<T> tasks)for(FindDirsFiles subTask:invokeAll(subTasks)){
subTask.join();//等待子任务执行完成}}}}}在主线程中调用了join方法进行等待,如果主线程太快执行完就看不到子线程执行结果了。
二、CountDownLatch
作用:一组线程等待其他的线程完成工作以后再执行,加强版join。
怎么理解呢?
首先简单来说它就是一个计数器
最主要的就三个方法
构造方法:public CountDownLatch(int count) 创建一个计数器,参数是计数器初始值
减数值方法:countDown() 给计数器的值减1
等待方法:await() 调用后开始等待,直到计数器值减为0接着执行
看一个例子,略复杂:
/**
* 类说明:演示CountDownLatch,有5个初始化的线程,6个扣除点,
* 扣除完毕以后,主线程和业务线程才能继续自己的工作
*/publicclassUseCountDownLatch{static CountDownLatch latch=newCountDownLatch(6);//初始化线程(只有一步,有4个)privatestaticclassInitThreadimplementsRunnable{@Overridepublicvoidrun(){
System.out.println("Thread_"+ Thread.currentThread().getId()+" ready init work......");
latch.countDown();//初始化线程完成工作了,countDown方法只扣减一次;for(int i=0; i<2; i++){
System.out.println("Thread_"+ Thread.currentThread().getId()+" ........continue do its work");}}}//业务线程privatestaticclassBusiThreadimplementsRunnable{@Overridepublicvoidrun(){try{
latch.await();}catch(InterruptedException e){
e.printStackTrace();}for(int i=0; i<3; i++){
System.out.println("BusiThread_"+ Thread.currentThread().getId()+" do business-----");}}}publicstaticvoidmain(String[] args)throws InterruptedException{//单独的初始化线程,初始化分为2步,需要扣减两次
Thread thread1=newThread(newRunnable(){@Overridepublicvoidrun(){
SleepTools.ms(1);
System.out.println("Thread_"+ Thread.currentThread().getId()+" ready init work step 1st......");
latch.countDown();//每完成一步初始化工作,扣减一次
System.out.println("begin step 2nd.......");
SleepTools.ms(1);
System.out.println("Thread_"+ Thread.currentThread().getId()+" ready init work step 2nd......");
latch.countDown();//每完成一步初始化工作,扣减一次}});
thread1.start();
Thread thread2=newThread(newBusiThread());
thread2.start();for(int i=0; i<=3; i++){
Thread thread=newThread(newInitThread());
thread.start();}
latch.await();
System.out.println("Main do ites work........");}}在上面的代码中创建了CountDownLatch(6)的初始值为6
thread2和main线程都调用了latch.await() 方法
for循环中创建了4个线程,每个线程调用一次countDown()方法
thread1线程中调用了2次countDown()方法
期望的执行流程:main和thread2等待其它5个线程执行6次countDown()将值减为0后接着执行
值得注意的几点:
1,一个线程中可以执行多次countDown()方法
2,所有的一组等待线程是靠另外的线程控制是否继续执行的
3,另外有await(long timeout, TimeUnit unit)方法可以等待某个时间后不再等待
三、CyclicBarrier
作用:让一组线程达到某个屏障,被阻塞,一直到组内最后一个线程达到屏障时,屏障开放,所有被阻塞的线程会继续运行
同样作为一个计数器
只有两个方法:
构造方法:CyclicBarrier(int parties) 传入计数器初始值
等待方法:await() 执行到此对初始值减1并等待,直到初始值为0,接着执行
CyclicBarrier跟CountDownLatch最大的不同是,它是一组线程内的屏障或者计数器,不能被该组线程外的其他线程的执行影响到
构造方法CyclicBarrier(int parties, Runnable barrierAction),屏障开放或者说计数器减为0,barrierAction定义的任务会执行
来看例子:
publicclassUseCyclicBarrier{privatestatic CyclicBarrier barrier=newCyclicBarrier(5,newCollectThread());privatestatic ConcurrentHashMap<String, Long> resultMap=newConcurrentHashMap<>();//存放子线程工作结果的容器publicstaticvoidmain(String[] args){for(int i=0; i<=4; i++){
Thread thread=newThread(newSubThread());
thread.start();}}//负责屏障开放以后的工作privatestaticclassCollectThreadimplementsRunnable{@Overridepublicvoidrun(){
StringBuilder result=newStringBuilder();for(Map.Entry<String, Long> workResult: resultMap.entrySet()){
result.append("["+ workResult.getValue()+"]");}
System.out.println(" the result = "+ result);
System.out.println("do other business........");}}//工作线程privatestaticclassSubThreadimplementsRunnable{@Overridepublicvoidrun(){long id= Thread.currentThread().getId();//线程本身的处理结果
resultMap.put(Thread.currentThread().getId()+"", id);
Random r=newRandom();//随机决定工作线程的是否睡眠try{if(r.nextBoolean()){
Thread.sleep(2000+ id);
System.out.println("Thread_"+ id+" ....do something ");}
System.out.println(id+"....is await");
barrier.await();
Thread.sleep(1000+ id);
System.out.println("Thread_"+ id+" ....do its business ");}catch(Exception e){
e.printStackTrace();}}}}new CyclicBarrier(5, new CollectThread()创建了一个CyclicBarrier,for循环中创建了5个SubThread,每个线程执行到 barrier.await()时会将CyclicBarrier的值减1并等待,减到0后会执行CollectThread任务和各个线程后面的任务
四、Semaphore信号量
作用:控制同时访问某个特定资源的线程数量,用在流量控制
用一个获取线程池连接的例子来感受下用法:
ublicclassDBPoolSemaphore{privatefinalstaticint POOL_SIZE=10;privatefinal Semaphore useful;//useful表示可用的数据库连接,useless表示已用的数据库连接publicDBPoolSemaphore(){this.useful=newSemaphore(POOL_SIZE);}//存放数据库连接的容器privatestatic LinkedList<Connection> pool=newLinkedList<Connection>();//初始化池static{for(int i=0; i< POOL_SIZE; i++){
pool.addLast(SqlConnectImpl.fetchConnection());}}/*归还连接*/publicvoidreturnConnect(Connection connection)throws InterruptedException{if(connection!= null){
System.out.println("当前有"+ useful.getQueueLength()+"个线程等待数据库连接!!"+"可用连接数:"+ useful.availablePermits());synchronized(pool){
pool.addLast(connection);}
useful.release();}}/*从池子拿连接*/public ConnectiontakeConnect()throws InterruptedException{//如果拿不到,会阻塞,直到拿到为止
useful.acquire();
Connection conn;synchronized(pool){
conn= pool.removeFirst();}return conn;}privatestatic DBPoolSemaphore dbPool=newDBPoolSemaphore();//业务线程privatestaticclassBusiThreadextendsThread{@Overridepublicvoidrun