文章目录
一、框架说明
Pytorch具体的APi操作详见Pytorch官方Api文档,torchvision具体Api操作详见torchvision官方Api,下面介绍一下常用的包
torch:张量的常见运算。如创建、索引、连接、转置、加减乘除、切片等torch.nn: 包含搭建神经网络层的模块(Modules)和一系列loss函数。如全连接、卷积、BN批处理、dropout、CrossEntryLoss、MSELoss等torch.nn.functional:常用的激活函数relu、leaky_relu、sigmoid等torch.autograd:提供Tensor所有操作的自动求导方法torch.cuda:提供对CUDA张量类型的支持,可以让模型使用gpu运行torch.optim:各种参数优化方法,例如SGD、AdaGrad、Adam、RMSProp等torch.utils.data:用于加载数据torch.nn.init:可以用它更改nn.Module的默认参数初始化方式torchvision.datasets:常用数据集。MNIST、COCO、CIFAR10、Imagenet等torchvision.modules:常用模型。AlexNet、VGG、ResNet、DenseNet等torchvision.transforms:图片相关处理。裁剪、尺寸缩放、归一化等torchvision.utils:将给定的Tensor保存成image文件
二、GPU相关
运行需要成功安装CUDA和CUDNN,同时要保证显卡驱动以及CUDA、CUDNN版本相匹配。对于CUDA的安装网上有很多教程
#True表示可以进行gpu加速
torch.cuda.is_available()#打印gpu数量
torch.cuda.device_count()#显示gpu名字,序号从0开始,例如我的是GeForce GTX 1050
torch.cuda.get_device_name(0)#输出当前GPU序号,从0开始
torch.cuda.current_device()在程序中可以如以下操作
#如果机器不存在gpu就使用cpu,存在就使用0号gpu,序号可以按自己需求修改
device= torch.device('cuda:0'if torch.cuda.is_available()else'cpu')#还需要将模型(神经网络)与数据转移到相应的设备上,model代表模型,data代表张量
model= model.to(device)#model = model.cuda()
data= data.to(device)#data = data.cuda()三、前置知识学习
Pytorch的一些入门常用操作,以及Numpy的入门常用操作。Numpy可以看菜鸟教程
深度学习入门可以浏览:
https://apachecn.gitee.io/ailearning/#/README
https://tangshusen.me/Dive-into-DL-PyTorch/#/
对于网络模型的优化,可以加入Dropout和BN批量归一化
四、搭建第一个神经网络(回归)
第一步生成数据
#导包import torchimport torch.nn.functionalas Fimport matplotlib.pyplotas plt# reproducible
torch.manual_seed(1)#这里linspace函数是从-1到1均分成100份,unsqueeze表示在第1轴增加一个维度,原本是一维,现在变成(100,1)维度,即100个数据1个特征。同理squeeze表示减少一个维度
x= torch.unsqueeze(torch.linspace(-1,1,100),dim=1)#增加随机噪声
y=pow(x,2)+ torch.randn(x.size())*0.1
plt.scatter(x,y)
plt.show()
第二步,建立神经网络,这里定义了一个隐藏层,并使用ReLu激活函数。
# 继承 torch 的 ModuleclassNet(torch.nn.Module):def__init__(self,n_feature,n_hidden,n_outpit):# 继承 __init__ 功能,必须要有,定义网络的时候进行初始化super(Net,self).__init__()
self.hidden=torch.nn.Linear(n_feature,n_hidden)
self.output=torch.nn.Linear(n_hidden,n_outpit)# 这同时也是 Module 中的 forward 功能,会自动进行前向计算defforward(self,x):
x=F.relu(self.hidden(x))
x=self.output(x)return x# to(device)选择在'cpu'或'cuda'上运行
net= Net(1,10,1)#net = Net(1,10,1).to(device)#打印一下网络信息print(net)第三步选择损失函数和优化器
#回归常用MSE,而分类常用Cross Entropy
loss= torch.nn.MSELoss()#pytorch根据当前当属更新参数值,学习率在这里取0.5
optimizer= torch.optim.SGD(net.parameters,lr=0.5)#查看参数值#list(net.parameters())[0]#list(net.parameters())[0]第四步模型的训练及其结果
epochs=100for iinrange(epochs):#训练给模型的数据,net(x)即net.forward(x)
prediction= net(x)#计算损失函数
loss= loss_fn(prediction,y)#优化器梯度清理,方便下一次梯度下降
optimizer.zero_grad()#反向传播求导
loss.backward()#优化器更新神经网络参数加到 net 的 parameters 上
optimizer.step()if i%10==0:
plt.cla()
plt.scatter(x.data.numpy(),y.data.numpy())
plt.plot(x.data.numpy(),prediction.data.numpy())
plt.text(0.5,0,'Loss=%.4f'% loss, fontdict={'size':16,'color':'red'})
plt.pause(0.1)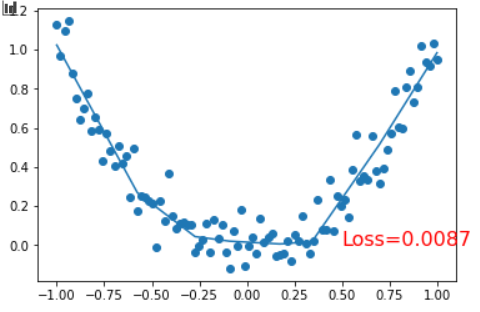
第五步模型的保存和加载
#保存整个模型
torch.save(net,"mynet.pkl")
net=torch.load("mynet.pkl")#保存模型参数,占用内存小,速度快
torch.save(net.state_dict(),"mynet.pkl")
net.load_state_dict("mynet.pkl")五、CNN卷积神经网络实现MNIST数据集
手写数字集识别的可视化网站:
https://www.cs.ryerson.ca/~aharley/vis/conv/
首先导入第三方库
import torchimport matplotlib.pyplotas pltimport torchvisionimport torch.utils.dataas Dataimport torch.nnas nn#设置随机种子以便复现
torch.manual_seed(1)训练集和测试集的获取,若本机有cuda环境,也可以运行cuda注释代码
EPOCH=1
BATCH_SIZE=32
LR=0.001#如果已经下载好改为False
DOWNLOAD_MINIST=False#获取手写数字训练集
train_data= torchvision.datasets.MNIST(# 保存地点
root="./minist/",# 是否是训练集
train=True,# 转换 PIL.Image or numpy.ndarray 成torch.FloatTensor (C,H,W), 训练的时候 normalize 成 [0.0, 1.0]区间
transform=torchvision.transforms.ToTensor(),# 是否下载
download=DOWNLOAD_MINIST)# 可视化查看一下数据图片
train,label= train_data[0]
plt.imshow(train.squeeze())
plt.show()
test_data= torchvision.datasets.MNIST(# 保存地点
root="./minist/",# 是否是训练集
train=False)# 批训练(32,1,28,28)
train_loader= Data.DataLoader(dataset=train_data,batch_size=BATCH_SIZE,shuffle=True)# 由原来的(60000,28,28)变为(60000,1,28,28)
test_x= torch.unsqueeze(test_data.data, dim=1).type(torch.FloatTensor)[:2000]/255.
test_y= test_data.targets[:2000]# 若存在cuda环境,即可使用注释代码# test_x = test_x.cuda()# test_y = test_y.cuda()CNN网络配置,输出大小为[(n - k + 2p) / s] + 1,n代表输入大小,k为核大小,p为填充,s为步幅
classCNN(nn.Module):def__init__(self):super(CNN,self).__init__()#输入形状为(1,28,28),输出形状为(16,14,14)
self.conv1= nn.Sequential(
nn.Conv2d(in_channels=1,# 输入通道
out_channels=16,# 输出通道
kernel_size=5,# 卷积核大小
stride=1,# 步幅
padding=2),# 填充# 此时输出形状为(16,28,28)
nn.ReLU(),# 激活函数# 最大池化,核大小为2,此时输出形状(16,14,14)
nn.MaxPool2d(kernel_size=2))
self.conv2= nn.Sequential(
nn.Conv2d(16,32,5,1,2),# 输出形状(32,14,14)
nn.ReLU(),
nn.MaxPool2d(2)#输出形状(32,7,7))#全连接网络,输出10个类别
self.out= nn.Linear(32*7*7,10)defforward(self,x):
x= self.conv1(x)
x= self.conv2(x)# 将卷积层展平,才能输入全连接网络
x= x.view(x.size(0),-1)
output= self.out(x)return output训练与测试
cnn= CNN()# 若存在cuda环境,即可使用注释代码# cnn = cnn.cuda()# 优化器
optimizer= torch.optim.Adam(cnn.parameters(),lr=LR)# 损失函数,分类问题
loss_fn= nn.CrossEntropyLoss()for epochinrange(EPOCH):# 迭代运行for step,(x, y)inenumerate(train_loader):# x = x.cuda()# y = y.cuda()
output= cnn(x)
loss= loss_fn(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()if(step%50==0):# 可以单独进行模型的测试
test_output= cnn(test_x)# 1代表索引列,因为刚好匹配到0-9,获取概率高的
pre_y= torch.max(test_output,1)[1].data.squeeze()# pre_y = torch.max(test_output, 1)[1].cuda().data.squeeze()# 获取准确率
accurary=float((pre_y== test_y).sum())/float(test_y.size(0))print('Epoch: ',epoch,'| train loss: %.4f'% loss.data,'| test accurary: %.2f'% accurary)# 最后可以模型保存六、RNN循环神经网络实现MNIST数据集
之前的操作与CNN类似,RNN循环神经网络部分如下
classLSTM(nn.Module):def__init__(self, input_size=28, hidden_size=64, num_layers=1, output_size=10):super(LSTM, self).__init__()# 使用LSTM比RNN效果好
self.rnn= nn.LSTM(# 输入数据特征数,这里28个28维度的数据输入
input_size= input_size,# 隐藏层特征数
hidden_size= hidden_size,# LSTM层数
num_layers= num_layers,# 如果是第一次输入,需要将batch_size与seq_length这两个维度调换
batch_first=True)# 输出10个类别
self.output= nn.Linear(hidden_size,output_size)defforward(self,x):# x shape (batch, time_step, input_size)# r_out shape (batch, time_step, output_size)# h_n shape (n_layers, batch, hidden_size) LSTM 有两个 hidden states, h_n 是分线, h_c 是主线# h_c shape (n_layers, batch, hidden_size)
r_out,(h_n, h_c)= self.rnn(x,None)# 选取最后一个时间点的 r_out 输出
output= self.output(r_out[:,-1,:])return output
lstm= LSTM()# 优化器
optimizer= torch.optim.Adam(lstm.parameters(),lr=LR)# 损失函数,分类问题
loss_fn= nn.CrossEntropyLoss()for epochinrange(EPOCH):# 迭代运行for step,(x, y)inenumerate(train_loader):# 输入输入需要变换形状
output= lstm(x.view(-1,28,28))
loss= loss_fn(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()if(step%50==0):# 可以单独进行模型的测试
test_output= lstm(test_x.view(-1,28,28))# 1代表索引列,因为刚好匹配到0-9,获取概率高的
pre_y= torch.max(test_output,1)[1].data.squeeze()# 获取准确率
accurary=float((pre_y== test_y).sum())/float(test_y.size(0))print('Epoch: ',epoch,'| train loss: %.4f'% loss.data,'| test accurary: %.2f'% accurary)# 最后可以模型保存七、AutoEncoder自编码
首先获取数据集
import torchimport matplotlib.pyplotas pltimport torchvisionimport torch.utils.dataas Dataimport torch.nnas nn#设置随机种子以便复现
torch.manual_seed(1)
EPOCH=1
BATCH_SIZE=32
LR=0.001#如果已经下载好改为False
DOWNLOAD_MINIST=False#获取手写数字训练集
train_data= torchvision.datasets.MNIST(# 保存地点
root="./minist/",# 是否是训练集
train=True,# 转换 PIL.Image or numpy.ndarray 成torch.FloatTensor (C,H,W), 训练的时候 normalize 成 [0.0, 1.0]区间
transform=torchvision.transforms.ToTensor(),# 是否下载
download=DOWNLOAD_MINIST)# 批训练(32,1,28,28)
train_loader= Data.DataLoader(dataset=train_data,batch_size=BATCH_SIZE,shuffle=True)网络的设置与训练,AutoEncoder是先将图片压缩后还原,用还原后的图片与原图片进行评估并梯度下降
# AutoEncoder 形式很简单, 分别是 encoder 和 decoder , 压缩和解压, 压缩后得到压缩的特征值, 再从压缩的特征值解压成原图片classAutoEncoder(nn.Module):def__init__(self):super(AutoEncoder, self).__init__()# 压缩
self.encoder= nn.Sequential(
nn.Linear(28*28,128),
nn.Tanh(),
nn.Linear(128,64),
nn.Tanh(),
nn.Linear(64,12),
nn.Tanh(),
nn.Linear(12,3),# 压缩成3个特征, 进行 3D 图像可视化)# 解压
self.decoder= nn.Sequential(
nn.Linear(3,12),
nn.Tanh(),
nn.Linear(12,64),
nn.Tanh(),
nn.Linear(64,128),
nn.Tanh(),
nn.Linear(128,28*28),
nn.Sigmoid(),# 激励函数让输出值在 (0, 1))defforward(self, x):
encoded= self.encoder(x)
decoded= self.decoder(encoded)return encoded, decoded
autoencoder= AutoEncoder()
optimizer= torch.optim.Adam(autoencoder.parameters(),lr=LR)
loss_fn= nn.MSELoss()for epochinrange(EPOCH):for step,(x, y)inenumerate(train_loader):
train_x= x.view(-1,28*28)
train_y= x.view(-1,28*28)
encoded, decoded= autoencoder(train_x)
loss= loss_fn(decoded, train_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()if(step%50==0):print('Epoch: ',epoch,'| train loss: %.4f'% loss.data)3D展示图,可以进行旋转观看
import matplotlib.pyplotas pltfrom mpl_toolkits.mplot3dimport Axes3Dfrom matplotlibimport cm# 要观看的数据
view_data= train_data.data[:200].view(-1,28*28).type(torch.FloatTensor)/255.
encoded_data, _= autoencoder(view_data)# 提取压缩的特征值
fig= plt.figure(2)
ax= Axes3D(fig)# 3D 图# x, y, z 的数据值
X= encoded_data.data[:,0].numpy()
Y= encoded_data.data[:,1].numpy()
Z= encoded_data.data[:,2].numpy()
values= train_data.targets[:200].numpy()# 标签值for x, y, z, sinzip(X, Y, Z, values):
c= cm.rainbow(int(255*s/9))# 上色
ax.text(x, y, z, s, backgroundcolor=c)# 标位子
ax.set_xlim(X