多GPU并行训练介绍
常见的多GPU训练方法
这里给出了两种,当然不局限于这两种。
- 第一种:
model parallel: 当模型特别大的时候,由于使用的GPU显存不够,无法将一个网络放在一块GPU里面,这个时候我们就可以网络不同的模块放在不同的GPU上,这样的话,我们就可以去训练一个比较大型的网络了,这就是model parallel的训练方式。 - 第二种:
data parallel:我们把整个模型放在一块GPU里面,并且将模型复制到每块GPU设备上,然后让它同时进行正向传播以及反向的误差传播。这种常见的训练方法叫做data parallel。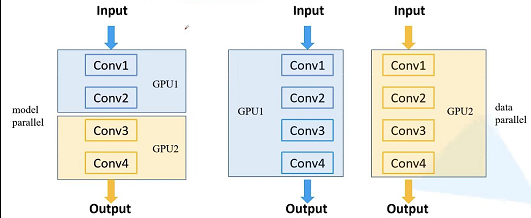
第二种方法由于我们能够同时并行输入样本进行训练,这就相当于增加了训练的batch size,这样的话我们训练速度就加快了。而第一种方法对我们训练速度是基本上没有提升的,但是它能够让我们将一个非常大的模型,放置在不同GPU设备上进行训练,使得以前无法训练的模型,现在可以训练了。
多GPU训练性能统计
下图,是基于多块GPU并行训练所统计的,数据是在测试过程中粗略统计得到,并不是精确的结果,仅供参考。