01 前言
刚换了新工作,用了两周时间准备,在 3 天之内拿了 5 个 offer,最后选择了广州某互联网行业独角兽 offer,昨天刚入职。这几天刚好整理下在面试中被问到有意思的问题,也借此机会跟大家分享下。
这家企业的面试官有点意思,一面是个同龄小哥,一起聊了两个小时(聊到我嘴都干了)。二面是个从阿里出来的架构师,视频面试,我做完自我介绍之后,他一开场就问我:
对 MySQL 熟悉吗?
我一愣,随之意识到这是个坑。他肯定想问我某方面的原理了,恰好我研究过索引。就回答:
对索引比较熟悉。
他:
order by 是怎么实现排序的?
还好我又复习,基本上排序缓冲区、怎么优化之类的都答到点子上。今天也跟大家盘一盘 order by,我将从原理讲到最终优化,给大家聊聊 order by,希望对你有所帮助。
国际惯例,先上思维导图。PS:文末有福利
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mVhFUz0d-1626411356236)(https://gitee.com/turodog/awesome_image/raw/master/images/order%20by%20%E6%80%8E%E4%B9%88%E4%BC%98%E5%8C%96%EF%BC%9F%20(1)].png)
1.1 往期精彩
1.2 先举个栗子
现在有一张订单表,结构是这样的:
CREATETABLE`order`(
idINT(11)NOTNULLAUTO_INCREMENTCOMMENT'主键',
user_codeVARCHAR(16)NOTNULLCOMMENT'用户编号',
goods_nameVARCHAR(64)NOTNULLCOMMENT'商品名称',
order_dateTIMESTAMPNULLDEFAULTCURRENT_TIMESTAMPCOMMENT'下单时间',
cityVARCHAR(16)DEFAULTNULLCOMMENT'下单城市',
order_numINT(10)NOTNULLCOMMENT'订单号数量',PRIMARYKEY(`id`))ENGINE=INNODBAUTO_INCREMENT=100DEFAULTCHARSET= utf8COMMENT='商品订单表';造点数据:
// 第一步:创建函数delimiter//DROPPROCEDUREIFEXISTS proc_buildata;CREATEPROCEDURE proc_buildata(IN loop_timesINT)BEGINDECLARE varINTDEFAULT0;WHILE
var< loop_timesDOSET var= var+1;INSERTINTO`order`(`id`,`user_code`,`goods_name`,`order_date`,`city`,`order_num`)VALUES( var, var+1,'有线耳机','2021-06-20 16:46:00','杭州',1);ENDWHILE;END// delimiter;// 第二步:调用上面生成的函数,即可插入数据,建议大家造点随机的数据。比如改改城市和订单数量CALL proc_buildata(4000);我生成的数据是这样的:
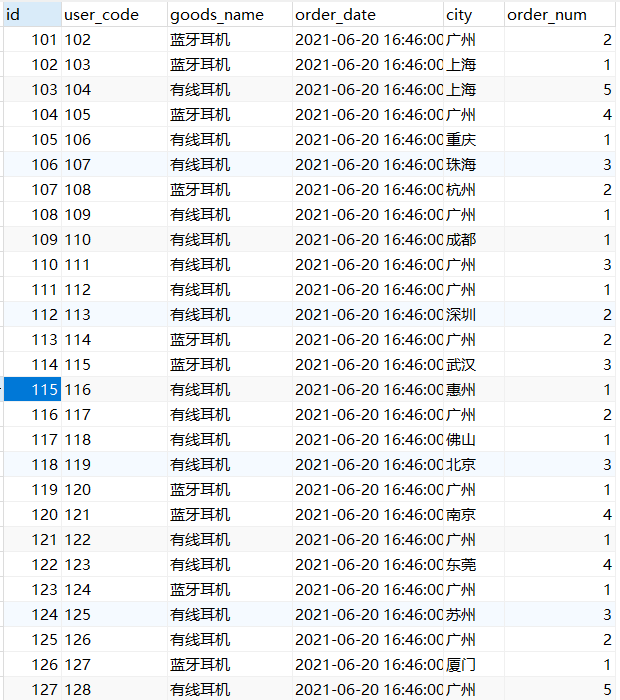
现有需求:查出 618 期间,广州的小伙伴的订单数量和用户编号,并按照订单数量升序,只要 1000 条。
根据需求可以得出以下 SQL,相信小伙伴都很熟悉了。
select city, order_num, user_codefrom`order`where city='广州'orderby order_numlimit1000;那这个语句是怎么执行的呢?有什么参数可以影响它的行为吗?
02 全字段排序
得到这个需求,我第一反应是先给 city 字段加上索引,避免全表扫描:
ALTERTABLE`order`ADDINDEX city_index(`city`);用 explain 看看执行情况

注意到最后一个 extra 字段的结果是:Using filesort,表示需要排序。其实 MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。
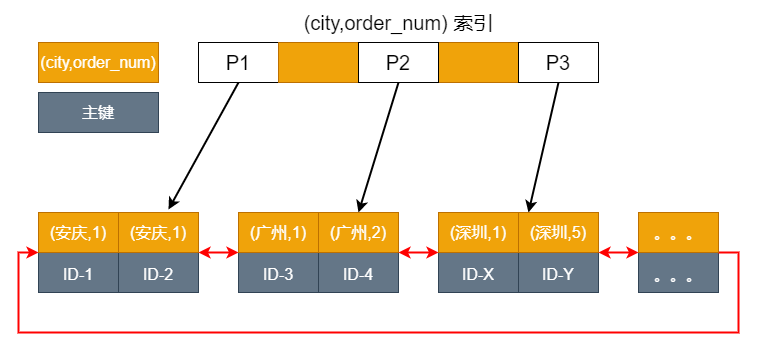
为了更直观了解排序的执行流程,我粗略画了个 city 索引的图示:
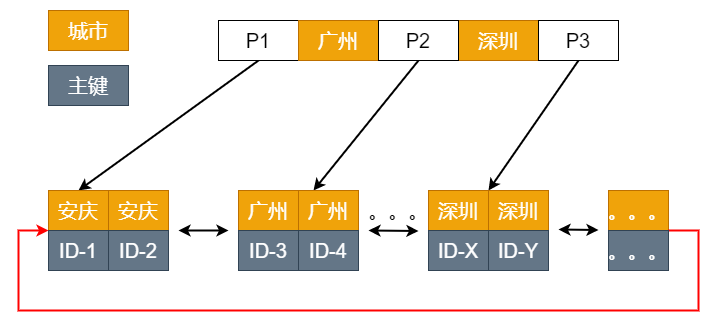
可见,现在满足 sql 条件的就是 ID-3 到 ID-X 这一段数据。sql 的整个流程是这样的:
- 1、初始化 sort_buffer,放入 city、order_num、user_code 这三个字段;
- 2、从索引 city 找到第一个满足 city=’ 广州’条件的主键 id,也就是图中的 ID_3;
- 3、到主键 id 索引取出整行,取 city、order_num、user_code 三个字段的值,存入 sort_buffer 中;
- 4、从索引 city 取下一个记录的主键 id;
- 5、重复步骤 3、4 直到 city 的值不满足查询条件为止,对应的主键 id 也就是图中的 ID_X;
- 6、对 sort_buffer 中的数据按照字段 order_num 做快速排序;
- 7、按照排序结果取前 1000 行返回给客户端。
这个过程称之为全字段排序,画个图,长这样:
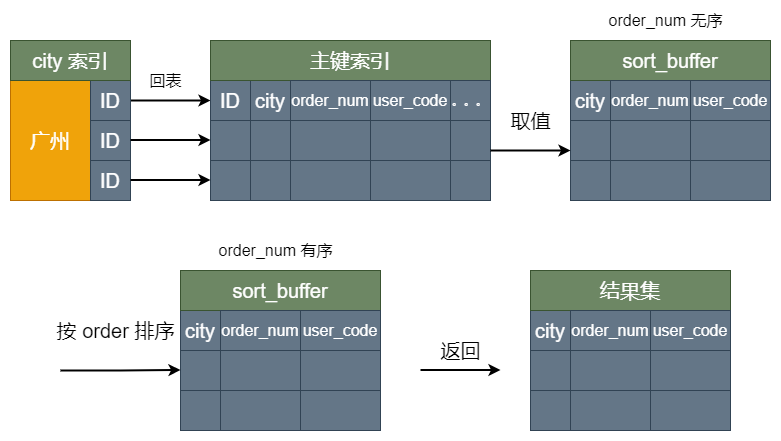
其中,按 order_num 排序这个步骤,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数sort_buffer_size。
也就是 MySQL 为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存顶不住,就得磁盘临时文件辅助排序。
当然,在 MySQL5.7 以上版本可以用下面介绍的检测方法(后面都有用到),来查看一个排序语句是否使用了临时文件。PS:这里的语句直接复制到 navicat 执行即可,要一起执行(都复制进去,点下执行)
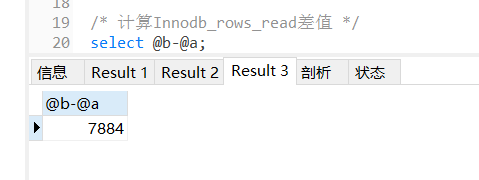
/* 打开optimizer_trace,只对本线程有效 */SET optimizer_trace='enabled=on';/* @a保存Innodb_rows_read的初始值 */select VARIABLE_VALUEinto@afrom performance_schema.session_statuswhere variable_name='Innodb_rows_read';/* 执行语句 */select city, order_num, user_codefrom`order`where city='广州'orderby order_numlimit1000;/* 查看 OPTIMIZER_TRACE 输出 */SELECT*FROM`information_schema`.`OPTIMIZER_TRACE`;/* @b保存Innodb_rows_read的当前值 */select VARIABLE_VALUEinto@bfrom performance_schema.session_statuswhere variable_name='Innodb_rows_read';/* 计算Innodb_rows_read差值 */select@b-@a;执行完之后,可从 OPTIMIZER_TRACE 表的 TRACE 字段得到以下结果:
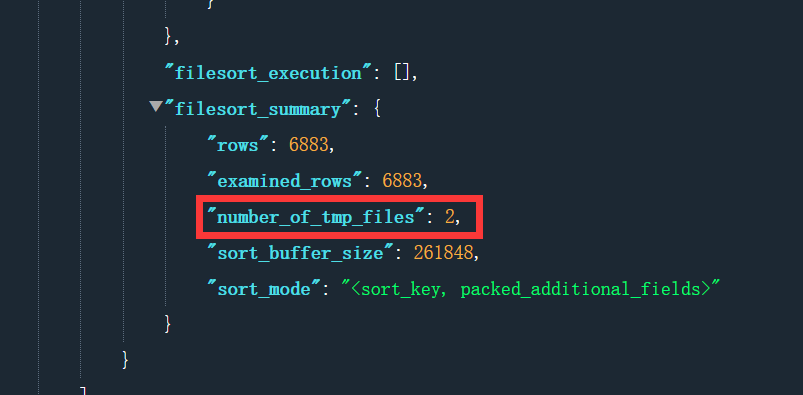
其中 examined_rows 表示需要排序的行数 6883;sort_buffer_size 就是排序缓冲区的大小;sort_buffer_size 就是我 MySQL 的排序缓冲区大小 256 KB。
另外,sort_mode 的值是 packed_additional_fields,它表示排序过程对数据做了优化,也就是数据占用多少就算多少内存。举个栗子:不存在数据定义长度 16,就按这个长度算,如果数据只占 2,只会按长度 2 分配内存。
number_of_tmp_files 代表的是用了几个外部文件来辅助排序。我这里是用了两个,内存放不下时,就使用外部排序,外部排序一般使用归并排序算法。可以这么简单理解,MySQL 将需要排序的数据分成 2 份,每一份单独排序后存在这些临时文件中。然后把这 2 个有序文件再合并成一个有序的大文件。
最后一个查询语句,select @b-@a 的值是 6884,表示整个过程只扫描了 6883 行,为啥显示 6884?
因为查询 OPTIMIZER_TRACE 表时,需用到临时表;而 InnDB 引擎把数据从临时表取出时,Inndb_rows_read 值会加 1。
所以,把 internal_tmp_disk_storage_engine 设置为 MyISAM 可解决此问题。
03 rowid 排序
上面的全字段排序其实会有很大的问题,你可能发现了。我们需要查询的字段都要放到 sort_buffer 中,如果查询的字段多了起来,内存占用升高,就会很容易打满 sort_buffer 。
这时,就要用很多的临时文件辅助排序,导致性能降低。
那问题来了:
我们思考的方向应该是降低排序的单行长度,哪有没有方法能做到呢?
肯定是有的,MySQL 之所以走全字段排序是由 max_length_for_sort_data 控制的,它的 默认值是 1024。
show variableslike'max_length_for_sort_data';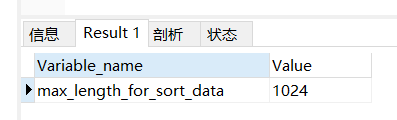
因为本文示例中 city,order_num,user_code 长度 = 16+4+16 =36 < 1024, 所以走的是全字段排序。我们来改下这个参数,改小一点,
SET max_length_for_sort_data=16;当单行的长度超过这个值,MySQL 就认为单行太大,要换一个算法。原来 city、user_code、order_num 占用的长度是 36,显然放不下全部查询字段了。这时就要换算法:sort_buffer 只存 order_num 和 id 字段。
这时的流程应该是这样的:
- 1、初始化 sort_buffer,确定放入两个字段,即 order_num 和 id;
- 2、从索引 city 找到第一个满足 city=’ 广州’条件的主键 id,也就是图中的 ID_3;
- 3、回表,取 order_num、id 这两个字段,存入 sort_buffer 中;
- 4、从索引 city 取下一个记录的主键 id;
- 5、重复步骤 3、4 直到不满足 city=’ 广州’条件为止,也就是图中的 ID_X;
- 6、对 sort_buffer 中的数据按照字段 order_num 进行排序;
- 7、遍历排序结果,取前 1000 行,再次回表取出 city、order_num 和 user_code 三个字段返回给客户端。
图示:由图可见,这种方式其实多了一次回表操作、但 sort_buffer_size 占用却变小了。
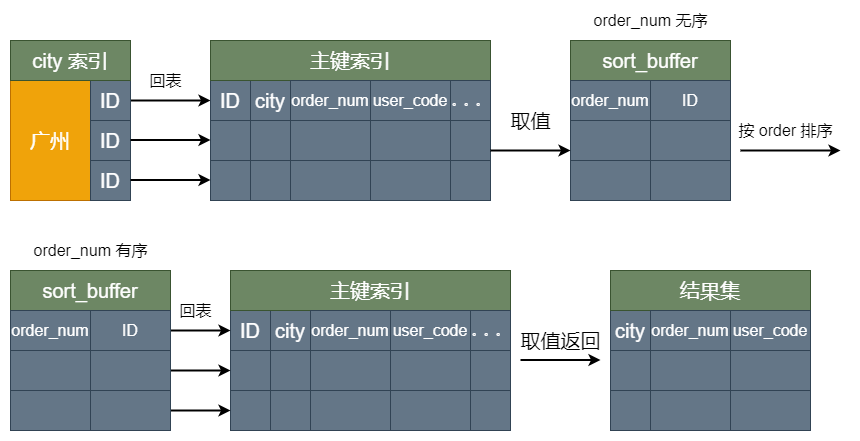
此时,执行上面的检测方法,可以发现 OPTIMIZER_TRACE 表中的信息变了。
- sort_mode 变成了 <sort_key, rowid>,表示参与排序的只有 order_num 和 id 这两个字段。
- number_of_tmp_files 变成 0 了,是因为这时参与排序的行数虽然仍然是 6883 行,但是每一行都变小了,因此需要排序的总数据量就变小了,sort_buffer_size 能满足排序用的内存,所以临时文件就不需要了。
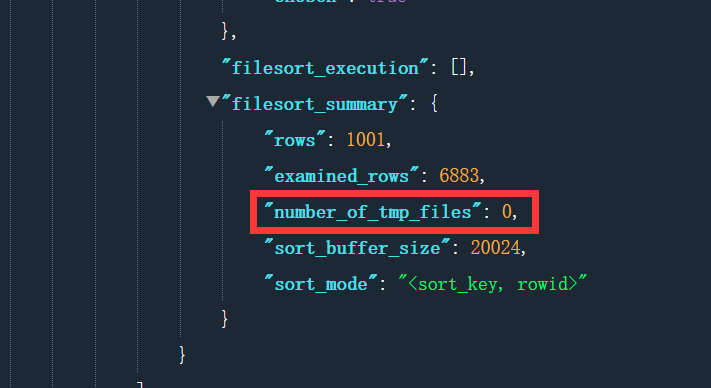
examined_rows 的值还是 6883,表示用于排序的数据是 6883 行。但是 select @b-@a 这个语句的值变成 7884 了。因为这时候除了排序过程外,在排序完成后,还要回表一次。由于语句是 limit 1000,所以会多读 1000 行。
3.1 做个小结
rowid 排序中,排序过程一次可以排序更多行,但是需要回表取数据。
如果内存足够大,MySQL 会优先选择全字段排序,把需要的字段都放到 sort_buffer 中,这样排序后就会直接从内存返回查询结果了,不用回表。
这也就体现了 MySQL 的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。
对于 InnoDB 表来说,rowid 排序会要求回表多造成磁盘读,因此不会被优先选择。
这两种都是因为数据本身是无序的,才要放到 sort_buffer 并生成临时文件才能做排序。
哪有没有办法,让数据本身就有序呢?回想下,我们学过的索引就是有序的。
04 索引优化
这时,要是我把 city、order_num 建一个组合索引,得出的数据是不是就是天然有序的了?比如:
altertable`order`addindex city_order_num_index(city, order_num);此时,order 表的索引长这样:
文章开头的 sql 执行语句。执行流程长这样:
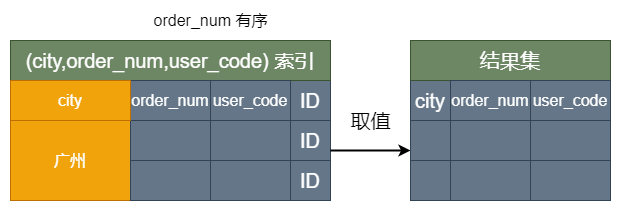
- 1、从索引 (city,order_num) 找到第一个满足 city=’ 广州’条件的主键 id;
- 2、回表,取 city、order_num、user_code 三个字段的值,作为结果集的一部分直接返回;
- 3、从索引 (city,order_num) 取下一个记录主键 id;
- 4、重复步骤 2、3,直到查到第 1000 条记录,或者是不满足 city=’ 广州’条件时循环结束。

用 explain 看下,这个过程不需要排序,更不需要临时表。只需要一次回表:

从图中可以看到,Extra 字段中没有 Using filesort 了,也就是不需要排序了。而且由于 (city,order_num) 这个联合索引本身有序,只要找到满足条件的前 1000 条记录就可以退出了,再回表一次。也就是说,只需要扫描 2000 次。
问题来了,还有没有更优解呢?
05 终极优化
上面的方法,还是有一次回表,主要是因为索引中不包括 user_code。回顾下我们之前学过的 sql 优化,是怎么避免回表的?
查询字段,加到组合索引中呀,对应到这张表,就是把 user_code 也加到组合索引中:
altertable`order`addindex city_order_num_user_code_index(city, order_num, user_code);此时的流程长这样,直接取数据就完事了:
explain 看下执行情况:

从图中可知,Extra 字段中多了 Using index 了,也就是使用了索引覆盖。连回表都不需要了,只需扫描 1000 次。
完美~
5.1 参数调优
除此以外,还可以通过调整参数优化 order by 的执行。比如调整 sort_buffer_size 尽量大点,因为 sort_buffer 太小,排序数据量大的话,会借助磁盘临时文件排序。如果 MySQL 服务器配置高的话,可以稍微调大点。
再比如把 max_length_for_sort_data 的值调大点。如果该值过小,则会增加回表次数、降低查询性能。
06 order by 常见面试题
1、查询语句有 in 多个属性时,SQL 执行是否有排序过程?
假设现在有联合索引 (city,order_num,user_code),执行以下 SQL 语句:
select city, order_num, user_codefrom`order`where cityin('广州')orderby order_numlimit1000in 单个条件,毫无疑问是不需要排序的。explain 一下:

但是,in 多个条件时;就会有排序过程,比如执行以下语句
select city, order_num, user_codefrom`order`where cityin('广州','深圳')orderby order_numlimit1000explain 以下,看到最后有 Using filesort 就说明有排序过程。这是为啥呢?

因为 order_num 本来就是组合索引,满足 “city=广州” 只有一个条件时,它是有序的。满足 “city=深圳” 时,它也是有序的。但是两者加到一起就不能保证 order_num 还是有序的了。
2、分页 limit 过大,导致大量排序。咋办?
select*from`user`orderby agelimit100000,10- 可以记录上一页最后的 id,下一页查询时,查询条件带上 id,如:where id > 上一页最后 id limit 10。
- 也可以在业务允许的情况下,限制页数。
3、索引存储顺序与 order by 不一致,如何优化?
假设有联合索引 (age,name), 我们需求修改为这样:查询前 10 个学生的姓名、年龄,并且按照年龄小到大排序,如果年龄相同,则按姓名降序排。对应的 SQL 语句应该是:
select name, agefrom studentorderby age, namedesclimit10;explain 一下,extra 的值是 Using filesort,走了排序过程:

这是因为,(age,name) 索引树中,age 从小到大排序,如果 age 相同,再按 name 从小到大排序。而 order by 中,是按 age 从小到大排序,如果 age 相同,再按 name 从大到小排序。也就是说,索引存储顺序与 order by 不一致。
我们怎么优化呢?如果 MySQL 是 8.0 版本,支持Descending Indexes,可以这样修改索引:
CREATETABLE`student`(`id`bigint(11)NOTNULLAUTO_INCREMENTCOMMENT'主键id',`student_id`varchar(20)NOTNULLCOMMENT'学号',`name`varchar(64)NOTNULLCOMMENT'姓名',`age`int(4)NOTNULLCOMMENT'年龄',`city`varchar(64)NOTNULLCOMMENT'城市',PRIMARYKEY(`id`),KEY`idx_age_name`(`age`,`name`desc)USINGBTREE)ENGINE=InnoDBAUTO_INCREMENT=15DEFAULTCHARSET=utf8COMMENT='学生表';4、没有 where 条件,order by 字段需要加索引吗
日常开发中,可能会遇到没有 where 条件的 order by,这时候 order by 后面的字段是否需要加索引呢。如有这么一个 SQL,create_time 是否需要加索引:
select*from studentorderby create_time;无条件查询的话,即使 create_time 上有索引,也不会使用到。因为 MySQL 优化器认为走普通二级索引,再去回表成本比全表扫描排序更高。所以选择走全表扫描,然后根据全字段排序或者 rowid 排序来进行。
如果查询 SQL 修改一下:
select*from studentorderby create_timelimit m;无条件查询,如果 m 值较小,是可以走索引的。因为 MySQL 优化器认为,根据索引有序性去回表查数据,然后得到 m 条数据,就可以终止循环,那么成本比全表扫描小,则选择走二级索引。
07 总结
这篇文章跟你聊了聊 order by 的执行流程,以及全字段排序和 rowid 排序的区别,从而得知,MySQL 更愿意用内存去换取性能上的提升。
与此同时,通过组合索引的索引覆盖小技巧,我们还可以减少回表的次数。以后设计索引的时候如果业务有涉及排序的字段,尽量加到索引中,并且把业务中其余的查询字段(比如文中的 city、user_code)加到组合索引中,更好地实现索引覆盖。
当然,索引也有缺点。它占空间,有维护的代价。所以大家设计的时候还是需要根据自己的实际业务去考虑。
最后,我还跟你探讨了关于 order by 的四个经典面试题,希望对你有帮助。
7.1 参考
- blog.csdn.net/weixin_28917279/article/details/113424610
- https://time.geekbang.org/column/article/73479
- https://zhuanlan.zhihu.com/p/380671457
08 idea 激活
09 大厂面试题 & 电子书
如果看到这里,喜欢这篇文章的话,请帮点个好看。
初次见面,也不知道送你们啥。干脆就送几百本电子书和2021最新面试资料吧。微信搜索JavaFish回复电子书送你 1000+ 本编程电子书;回复面试送点面试题;回复1024送你一套完整的 java 视频教程。
面试题都是有答案的,详细如下所示:有需要的就来拿吧,绝对免费,无套路获取。