本篇文章我们主要来看看Map的相关内容。
需要学习Collection详解的可以查看我的另一篇文章:java集合之Collection
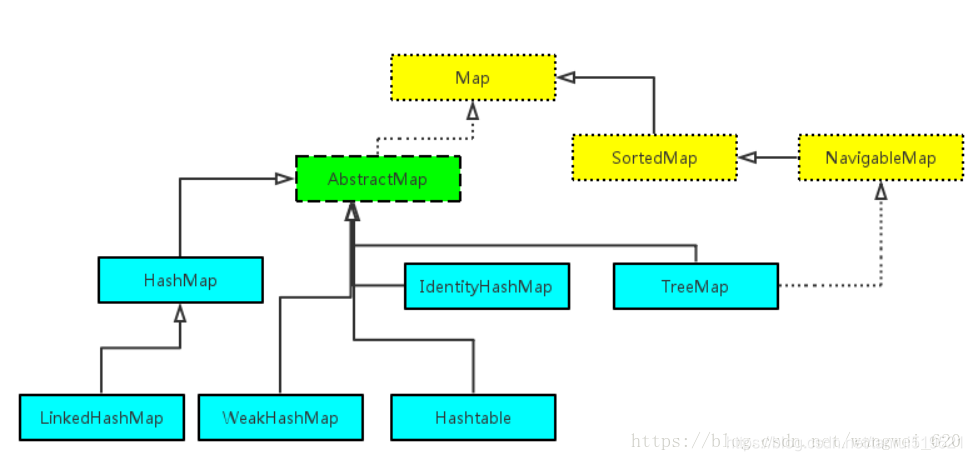
Map
1.1 Map 简介
什么是Map?
Map 是一种键-值对(key-value)集合,Map 集合中的每一个元素都包含一个键对象和一个值对象。其中,键对象不允许重复,而值对象可以重复,并且值对象还可以是 Map 类型的,就像数组中的元素还可以是数组一样。
特点:该集合存储键(key)值(value)对,一对一对往里存,而且要保证键(key)的唯一性。
什么时候使用Map集合:当数据之间存在映射关系时,优先考虑Map集合。
1.2 Map 框架示意图
1.3 Map常用方法
- V put(K key, V value):将指定的值与此映射中的指定键关联,添加键值对。
- void putAll(Map<? extends K,? extends V> m):从指定映射中将所有映射关系复制到此映射中,批量添加键值对。
- void clear():从此映射中移除所有映射关系,清空所有键值对。
- V remove(Object key):如果存在一个键的映射关系,则将其从此映射中移除,删除单个键值对。
- boolean containsKey(Object key):如果此映射包含指定键的映射关系(是否包含该键),则返回 true。
- boolean containsValue(Object value):如果此映射将一个或多个键映射到指定值(是否包含该值),则返回 true。
- boolean isEmpty():如果此映射未包含键-值映射关系,该map集合为空,则返回 true。
- V get(Object key):返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null。
- int size():返回此映射中的键-值映射关系(键值对)数
- Collection values():返回此映射中包含的值的 Collection 视图(集合)。
代码示例:
import java.util.*;publicclassMapDemo{publicstaticvoidmain(String[] args){
Map<Integer, Integer> map1=newHashMap<Integer, Integer>();
Map<Integer, Integer> map2=newHashMap<Integer, Integer>();
map1.put(1,100);
map1.put(2,200);
map1.put(3,300);
map2.put(11,1100);
map2.put(12,1200);
map2.put(13,1300);// 查看包含的元素个数
System.out.println(map1.size());
System.out.println(map1);// 存入新的key为1的数据,覆盖原(1,100)
map1.put(1,99);
System.out.println(map1);// 根据Key获取Value
System.out.println("map1 get key 2 is: "+map1.get(2));// 判断是否包含某个Key或则Value
System.out.println("map1中有key为4的元素? "+map1.containsKey(4));
System.out.println("map1中有Value为300的元素? "+map1.containsValue(300));// 将map2中的元素复制到map1中
map1.putAll(map2);
System.out.println("after copy, map1 now is: "+map1);
System.out.println("after copy, map2 now is: "+map2);// 从map2中移出一组键值对(通过key)
map2.remove(12);
System.out.println("After remove 12, map2 is: "+map2);// 清空map2
map2.clear();
System.out.println("After clear, map2 is: "+map2+" and size is: "+map2.size());}}运行结果:
3{1=100,2=200,3=300}{1=99,2=200,3=300}
map1 get key2 is:200
map1中有key为4的元素?false
map1中有Value为300的元素?true
after copy, map1 now is:{1=99,2=200,3=300,11=1100,12=1200,13=1300}
after copy, map2 now is:{11=1100,12=1200,13=1300}
After remove12, map2 is:{11=1100,13=1300}
After clear, map2 is:{} and size is:01.4 Map的两种取出方式:
Map集合的取出原理:将Map集合转成Set集合,再通过迭代器取出。
- Set keySet():返回此映射中包含的键的 Set 视图(集合)。
将map中所有的键存入到Set集合,因为set具备迭代器,所有迭代方式取出所有的键再根据get()方法 ,获取每一个键对应的值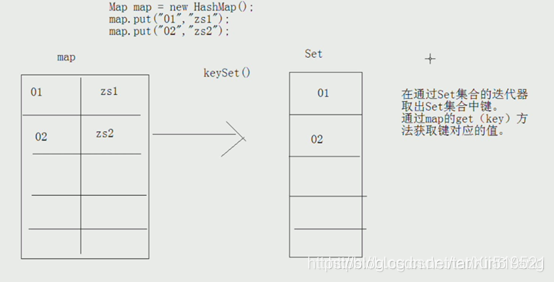
代码示例:
publicclassMapDemo2{publicstaticvoidmain(String[] args){
Map<String,String> map=newHashMap<String,String>();
map.put("01","zhangsan1");
map.put("02","zhangsan2");
map.put("03","zhangsan3");
map.put("04","zhangsan4");//先获取map集合的所有键的set集合,keySet();
Set<String> k= map.keySet();//Set<String>相当于返回值类型//有了Set集合,就可以获取其迭代器.(注意Set集合的类型要和迭代器保持一致)
Iterator<String> it= k.iterator();while(it.hasNext()){
String key= it.next();//有了键,就可以通过map集合的get方法获取对应的值
String value=map.get(key);
System.out.println("key:"+key+"---value:"+value);}}}运行结果:
key:01---value:zhangsan1
key:02---value:zhangsan2
key:03---value:zhangsan3
key:04---value:zhangsan4代码示例:
publicclassMapDemo3{publicstaticvoidmain(String[] args){
Hashtable<String, String> hashTable;
TreeMap<String, String> treeMap;
HashMap<String, String> hashMap;
LinkedHashMap<String, String> linkedHashMap;for(int i=0; i<10; i++){
hashTable.put(String.valueOf(i), i+""+ i);
treeMap.put(String.valueOf(i), i+""+ i);
hashMap.put(String.valueOf(i), i+""+ i);
linkedHashMap.put(String.valueOf(i), i+""+ i);}
System.out.println("Hashtable: "+ hashTable.keySet());
System.out.println("TreeMap: "+ treeMap.keySet());
System.out.println("HashMap: "+ hashMap.keySet());
System.out.println("LinkedHashMap: "+ linkedHashMap.keySet());}运行结果:
Hashtable:[9,8,7,6,5,4,3,2,1,0]
TreeMap:[0,1,2,3,4,5,6,7,8,9]
HashMap:[0,1,2,3,4,5,6,7,8,9]
LinkedHashMap:[0,1,2,3,4,5,6,7,8,9]- Set<Map.Entry<K,V>> entrySet():返回此映射中包含的映射关系的 Set 视图(集合)。
将Map集合中的映射关系存入到了Set集合中,而这个映射关系的数据类型就Map.Entry。
Map.Entry:其实Entry也是一个接口,它是Map接口中的一个内部接口,getKey()和getValue是接口Map.Entry<K,V>中的方法,返回对应的键和对应的值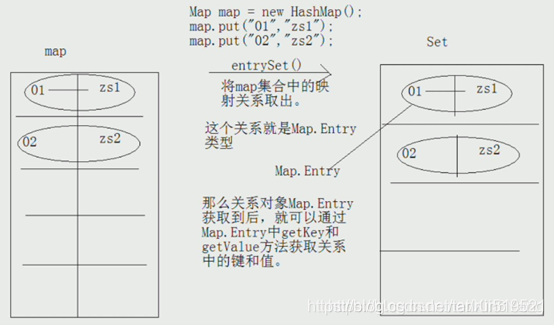
代码示例:
publicclassMapDemo4{publicstaticvoidmain(String[] args){
Map<String,String> map=newHashMap<String,String>();
map.put("02","zhangsan2");
map.put("03","zhangsan3");
map.put("01","zhangsan1");
map.put("04","zhangsan4");//将Map集合中的映射关系取出,出入到Set集合中
Set<Map.Entry<String,String>> es= map.entrySet();
Iterator<Map.Entry<String,String>> it= es.iterator();while(it.hasNext()){
Map.Entry<String, String> mey= it.next();//getKey()和getValue是接口Map.Entry<K,V>中的方法,返回对应的键和对应的值
String key= mey.getKey();
String value= mey.getValue();
System.out.println(key+":"+value);}}}运行结果:
04:zhangsan401:zhangsan102:zhangsan203:zhangsan3常见问题:
Entry是接口 ,但是为什么不定义定义在外面呢?
原因:
Entry代表的是映射关系,先有Map集合,才有的映射关系,所以它是Map集合内部的事物,因此将Entry定义为在Map的内部集合,可以直接访问Map集合中的元素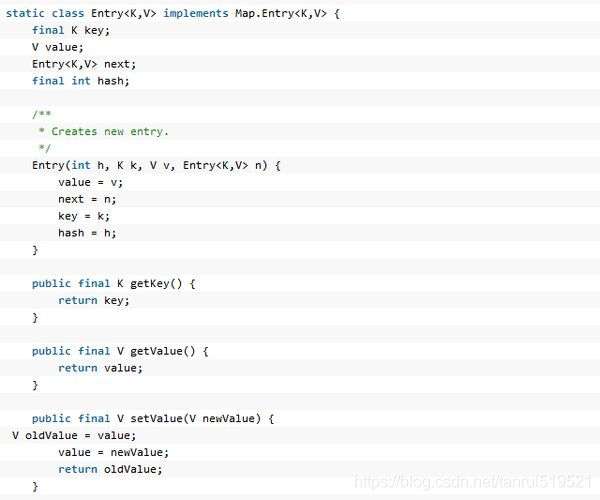
看到这里的时候大伙儿估计都明白了为什么HashMap为什么要选择Entry数组来存放key-value,因为Entry实现的Map.Entry接口里面定义了getKey(),getValue(),setKey(),setValue()等方法,对键值对进行了一个封装便于后面的操作。
HashMap
2.1 HashMap简介
HashMap是Map的常见实现类,也是Java中使用最频繁的储存键值对的结构,即散列表,它存储的是键值对(key-value)映射。HashMap 继承于AbstractMap。
2.2 HashMap的工作原理
Java中的数组在添加或者删除的时候,都会复制一个新数组,比较耗内存,但是数组遍历比较高效(寻址容易,插入和删除困难);然而,链表则是遍历比较慢,而添加和删除元素代价低(寻址困难,插入和删除容易)。HashMap则是巧妙的结合这两点——哈希表
HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry。这些键值对(Entry)分散存储在一个数组中,这个数组就是HashMap的主干。简单的来说HashMap是由数组+链表组成的。下面我们可以通过HashMap的结构图来看到它的基本结构。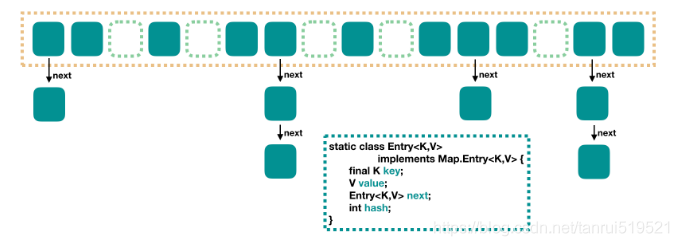
HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。
上图中,每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的next。我们存储的是key和value。其中hash通过key计算的hashcode值,next是指向下一个节点。由此可以理解存储原理了(详细看源码分析)。
2.3 HashMap的源码分析
2.3.1 重要属性
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4 : 默认的初始容量 (16)
static final int MAXIMUM_CAPACITY = 1 << 30 : 最大容量
static final float DEFAULT_LOAD_FACTOR = 0.75f : 负载因子:该属性是表示在扩容之前容量占有率的一个标尺。它控制数组存放Node是的疏密程度。loadFactor越趋近于1,那么数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,查找效率降低。loadFactor越小,也就是趋近于0,那么数组中存放的数据也就越稀。默认的0.75f是一个权衡后的值。
Entry[] table : Entry数组类型,HashMap的键值对都是存储在Entry数组中
int threshold; : 阈值。用于判断是否需要调整HashMap的容量。threshold = 容量 * 加载因子,当Size>=threshold的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是衡量数组是否需要扩增的一个标准。
static final int TREEIFY_THRESHOLD = 8:如果链表超过了这个值,则将单链表转变为红黑树。
2.3.2 构造函数
// 构造函数一publicHashMap(){this.loadFactor= DEFAULT_LOAD_FACTOR;
threshold=(int)(DEFAULT_INITIAL_CAPACITY* DEFAULT_LOAD_FACTOR);
table=newEntry[DEFAULT_INITIAL_CAPACITY];init();}// 构造函数二publicHashMap(int initialCapacity){this(initialCapacity, DEFAULT_LOAD_FACTOR);}// 构造函数三publicHashMap(int initialCapacity,float loadFactor){if(initialCapacity<0)thrownewIllegalArgumentException("Illegal initial capacity: "+
initialCapacity);if(initialCapacity> MAXIMUM_CAPACITY)
initialCapacity= MAXIMUM_CAPACITY;if(loadFactor<=0|| Float.isNaN(loadFactor))thrownewIllegalArgumentException("Illegal load factor: "+
loadFactor);this.loadFactor= loadFactor;this.threshold=tableSizeFor(initialCapacity);}// 构造函数四publicHashMap(Map<?extendsK,?extendsV> m){this.loadFactor= DEFAULT_LOAD_FACTOR;putMapEntries(m,false);}我们用的最多的就是第一个无参构造方法,默认的初始容量(16)和加载因子(0.75)。
构造函数二调用的构造函数三,手动设置初始容量大小。
构造函数三是手动设置初始容量和负载因子。
构造函数是将别的map映射到自己的map中。
2.3.3 存储数据put
public Vput(K key, V value){// 若“key为null”,则将该键值对添加到table[0]中。if(key== null)returnputForNullKey(value);// 若“key不为null”,则计算该key的哈希值,然后将其添加到该哈希值对应的链表中。int hash=hash(key.hashCode());//搜索指定hash值在对应table中的索引int i=indexFor(hash, table.length);// 循环遍历Entry数组,若“该key”对应的键值对已经存在,则用新的value取代旧的value。然后退出!for(Entry<K,V> e= table[i]; e!= null; e= e.next){
Object k;if(e.hash== hash&&((k= e.key)== key|| key.equals(k))){//如果key相同则覆盖并返回旧值
V oldValue= e.value;
e.value= value;
e.recordAccess(this);return oldValue;}}//修改次数+1
modCount++;//将key-value添加到table[i]处addEntry(hash, key, value, i);return null;}我们看看putForNullKey(value)方法:
private VputForNullKey(V value){for(Entry<K,V> e= table[0]; e!= null; e= e.next){if(e.key== null){//如果有key为null的对象存在,则覆盖掉
V oldValue= e.value;
e.value= value;
e.recordAccess(this);return oldValue;}}
modCount++;addEntry(0, null, value,0);//如果键为null的话,则hash值为0return null;}如果key为null的话,hash值为0,对象存储在数组中索引为0的位置。即table[0];
我们再看来一下如何通过key的hashCode值计算hash码:
staticinthash(int h){
h^=(h>>>20)^(h>>>12);return h^(h>>>7)^(h>>>4);}得到hash码之后就会通过hash码去计算出应该存储在数组中的索引,计算索引的函数如下:
static intindexFor(int h, int length){//根据hash值和数组长度算出索引值return h&(length-1);//这里不能随便算取,用hash&(length-1)是有原因的,这样可以确保算出来的索引是在数组大小范围内,不会超出,&运算时当同时为1,结果为1,否则为0}我们一般对哈希表的散列很自然地会想到用hash值对length取模(即除法散列法),Hashtable中也是这样实现的,这种方法基本能保证元素在哈希表中散列的比较均匀,但取模会用到除法运算,效率很低,HashMap中则通过h&(length-1)的方法来代替取模,同样实现了均匀的散列,但效率要高很多,这也是HashMap对Hashtable的一个改进。
根据上面 put 方法的源代码可以看出,当程序试图将一个key-value对放入HashMap中时,程序首先根据该 key 的 hashCode() 返回值决定该 Entry 的存储位置:
- 如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。
- 如果这两个 Entry 的 key通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有 Entry 的 value,但key不会覆盖。
- 如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部
addEntry() 方法:
voidaddEntry(int hash, K key, V value,int bucketIndex){
Entry<K,V> e= table[bucketIndex];//取得数组中索引为bucketIndex的Entry对象
table[bucketIndex]=newEntry<>(hash, key, value, e);//用hash、key、value构建一个新的Entry对象放到索引为bucketIndex的位置,并且将该位置原先的对象设置为新对象的next构成链表。if(size++>= threshold)//判断put后size是否达到了临界值threshold,如果达到了临界值就要进行扩容resize(2* table.length);//HashMap扩容是扩为原来的两倍。}2.3.4 数据读取 get
public Vget(Object key){if(key== null)returngetForNullKey();int hash=hash(key.hashCode());for(Entry<K,V> e= table[indexFor(hash, table.length)]