背景
之前做了一个功能,是对表的 CURD 操作,只是有点特殊,就是在插入/更新数据的时候因为做了批量导入。所以在插入的时候需要判断是否有相同记录存在,如果有的话则更新已经存在的数据,如果没有的话插入该条数据。
我最初设计的版本是首先查询该条记录,如果记录存在的话则更新该记录,反之则插入一条新纪录。
在单条插入/更新的时候这样做是没有问题的,但是在批量导入的环境下由于数据量过大所以这里出现里的严重的性能问题。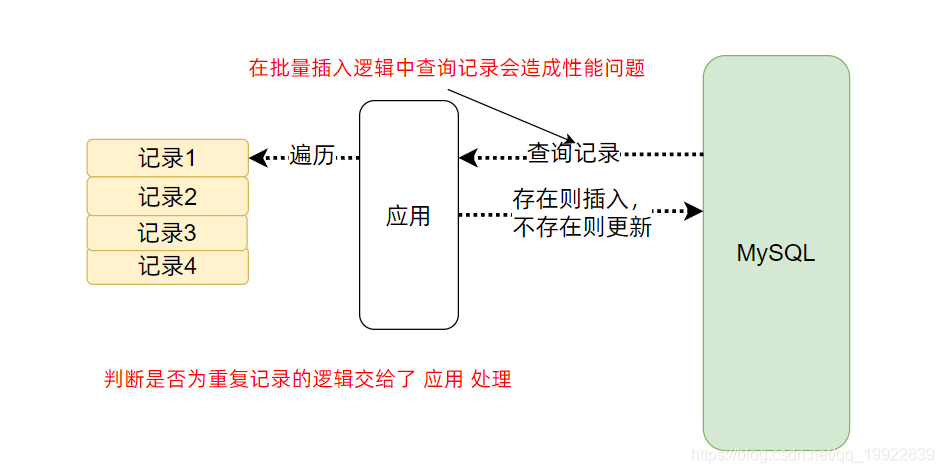
当我进行批量插入的时候,我需要对每条插入记录都要在数据库中判断是否存在相同记录,这样大大拉低了插入的性能。而为了满足存在并更新,记录是否存在这个判断又是必不可少的,那么这里怎么优化呢?
优化方案 “插入或更新”INSERT FOR UPDATE
存在则更新,不存在则插入
这里将如果存在则更新,不存在则插入的这个执行逻辑交给了 MySQL 去实现,这样我们的遍历查询插入的逻辑就统一成为了一条插入语句,无须进行判断。我们可以使用 MySQL 的条件插入语句INSERT FOR UPDATE 实现该逻辑。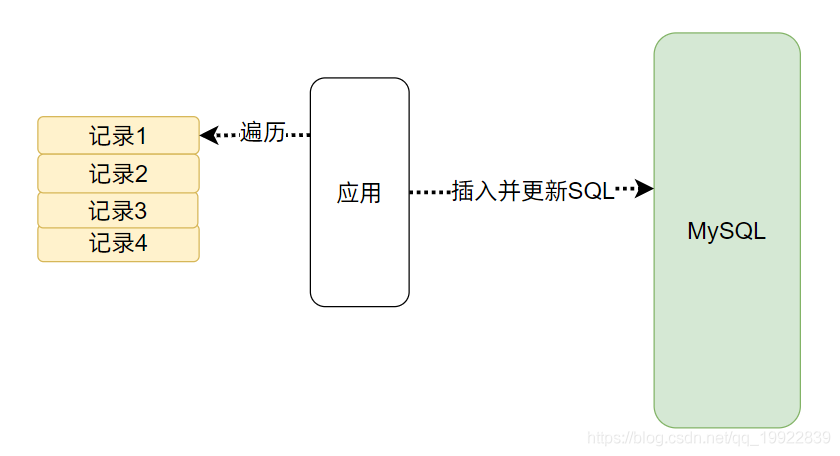
INSERT FOR UPDATE语法
INSERT[LOW_PRIORITY|DELAYED| HIGH_PRIORITY][IGNORE][INTO] tbl_name[(col_name[, col_name]...)]
{VALUES|VALUE}(value_list)[,(value_list)]...[ONDUPLICATEKEYUPDATE assignment_list]
INSERTwith anON DUPLICATE KEY UPDATEclause enables existing rows to be updated if a row to be
inserted would cause a duplicate value in a UNIQUE index or PRIMARY
KEY.
带有
ON DUPLICATE KEY UPDATE的INSERT语句允许当插入一行时由于唯一索引或者主键索引而产生的重复值情况时则对已经存在的行执行更新操作。
这个语法需要配合唯一索引实现,这里我们演示使用主键ID替代。
-- 这里我们新建一张简单的用户表用作演示CREATETABLEuser(
idint(11)notnullauto_incrementprimarykey,
namevarchar(255)notnull,
gendervarchar(32)notnulldefault'male',
ageint(11)notnulldefault0,
versionint(11)notnulldefault1,
create_timetimestampnotnulldefaultcurrent_timestamp,
update_timetimestampnotnulldefaultcurrent_timestamponupdatecurrent_timestamp)engine="InnoDB",charset="utf8mb4";-- 单条插入或更新的 SQL 可以这样写-- 注意这样实现的方式不支持批量,否则就有批量记录的所有 name 都更新成了张三,gender 更新成了 maleINSERTINTOuser(id,name,gender,age,version)VALUE(1,"张三","male",22,1)ONDUPLICATEKEYUPDATE name="张三",gender="male",age=22;-- 在批量插入或更新时我们的 UPDATE 可以通过 VALUES(field) 获取我们插入的对应记录的值-- 如 name = VALUES(name) 则表示将 name 更新成为我们输入的值-- 通过 VALUES() 函数获取在(VALUE|VALUES) 中映射的对应的值INSERTINTOuser(id,name,gender,age,version)VALUE(1,"张三","male",22,1)ONDUPLICATEKEYUPDATE name=VALUES(name),gender=VALUES(gender),age=VALUES(age);-- 这里的插入逻辑表示当存在id为1 的记录时则更新 name 为输入的name,gender 为输入的 gender ,age为输入的age当存在重复记录时只更新指定字段的值
上面的 INSERT 语句即可实现更新部分字段的要求。下面语句同样可以实现相同功能:
-- 这里当我们的记录发生重复的时候我们只更新 age 字段,同时将我们的 version 字段加1INSERTINTOuser(id,name,gender,age)VALUE(1,"张三","male",22)ONDUPLICATEKEYUPDATE age=VALUES(age),version=version+1;-- 这里当我们的记录发生重复的时候我们只更新 age 字段,-- 同时将我们的 version 字段加 1 ,这里我们又做了怪,把更新时间往后挪了一天INSERTINTOuser(id,name,gender,age)VALUE(1,"张三","male",22)ONDUPLICATEKEYUPDATE age=VALUES(age),
version=version+1,update_time=date_add(now(),interval1day);批量更新记录语句
下面我们写一个批量插入/更新的语句:
INSERTINTOuser(id,name,gender,age)VALUES(1,"张三","male",22),(2,"李四","female",18),(3,"王五","male",33),(4,"赵六","male",17)ONDUPLICATEKEYUPDATE
name=VALUES(name),gender=VALUES(gender),age=VALUES(age),version=version+1;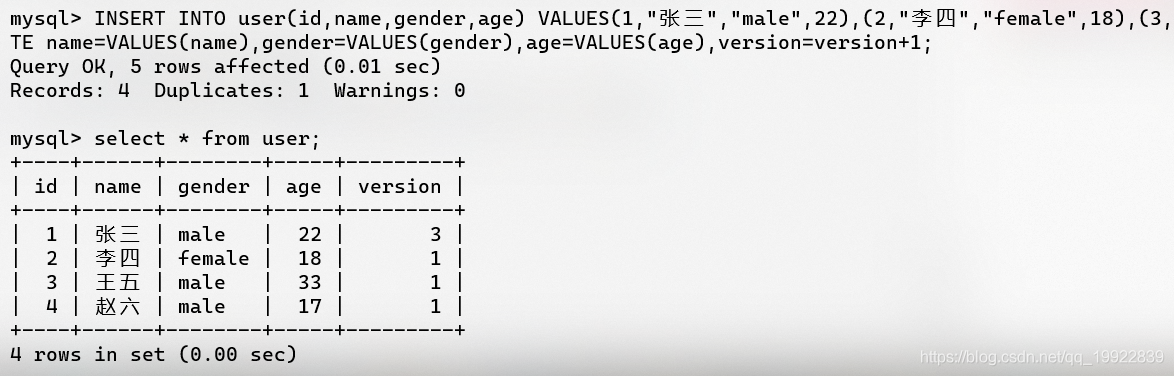
重复执行后会发现版本不断更新,但是不会报索引重复异常。
这里使用了主键索引做演示,实际应用中开发者可以根据实际场景在需要的字段上自定义唯一索引即可。
优化方案 “删除后插入”REPLACE INTO
存在则删除并插入,不存在则直接插入
上面的条件插入或更新其实已经能够满足大部分时候的需求了,这里我们介绍另外一种实现方式。通过过删除原有的数据然后执行插入操作。
REPLACE INTO 语法
REPLACE[LOW_PRIORITY|DELAYED][INTO] tbl_name[PARTITION(partition_name[, partition_name]...)][(col_name[, col_name]...)]
{VALUES|VALUE}(value_list)[,(value_list)]...REPLACE INTO 的语法其实和INSERT INTO 的语法已经很像了,不同的是REPLACE INTO 在遇到由于主键或唯一键导致的重复记录时,它会首先删除已经存在的记录,然后再插入新的记录。做法有些暴力,但是却很有效。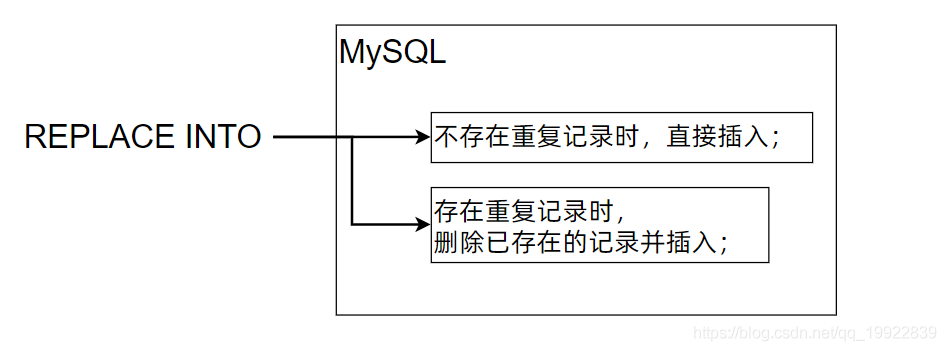
-- 当 id=1 的记录存在时,会删除原有记录,然后插入我们给出的记录REPLACEINTOuser(id,name,gender,age)VALUES(1,"张三","male",22);可以看到REPLACE INTO相较于INSERT FOR UPDATE 代码要简单的很多,相对应的功能也简化了。简单带来的好处是对于重复记录的处理只需要将INSERT 修改成REPLACE 即可,无须做其他复杂的条件处理。由于新的记录与原有记录逻辑上来讲完全相同,删除并插入记录一般情况下也能够满足大多数场景。
参考资料
INSERT FOR UPDATE 用法
Mysql 存在既更新,不存在就添加
MySQL 当记录不存在时insert,当记录存在时update