基于PyTorch的YoloV5目标检测平台
参考:
文章转载记录来自
Bubbliiiing大佬博客
Bubbliiiing大佬GIthub地址
Bubbliiiing大佬B站视频讲解
20系列及以下显卡环境配置pytorch代码对应的pytorch版本为1.2,配置方法地址
30系显卡由于框架更新不可使用上述环境配置教程。 配置如下: pytorch代码对应的pytorch版本为1.7.0,cuda为11.0,cudnn为8.0.5
江大白知乎、博客等
pytorch深度学习框架
YoloV5目标检测算法
YoloV5l版本
YoloV5改进的部分改进
1、主干部分:使用了Focus网络结构,具体操作是在一张图片中**每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。**该结构在YoloV5第5版之前有所应用,最新版本中未使用(后面改为了6*6的卷积,效果更好)。
2、数据增强:Mosaic数据增强、Mosaic利用了四张图片进行拼接实现数据中增强,根据论文所说其拥有一个巨大的优点是丰富检测物体的背景!且在BN计算的时候一下子会计算四张图片的数据!
3、多正样本匹配:在之前的Yolo系列里面,在训练时每一个真实框对应一个正样本,即在训练时,每一个真实框仅由一个先验框负责预测。YoloV5中为了加快模型的训练效率,增加了正样本的数量,在训练时,每一个真实框可以由多个先验框负责预测。
- 输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
- 基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
- Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
- Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
YoloV5思路
一、 整体结构
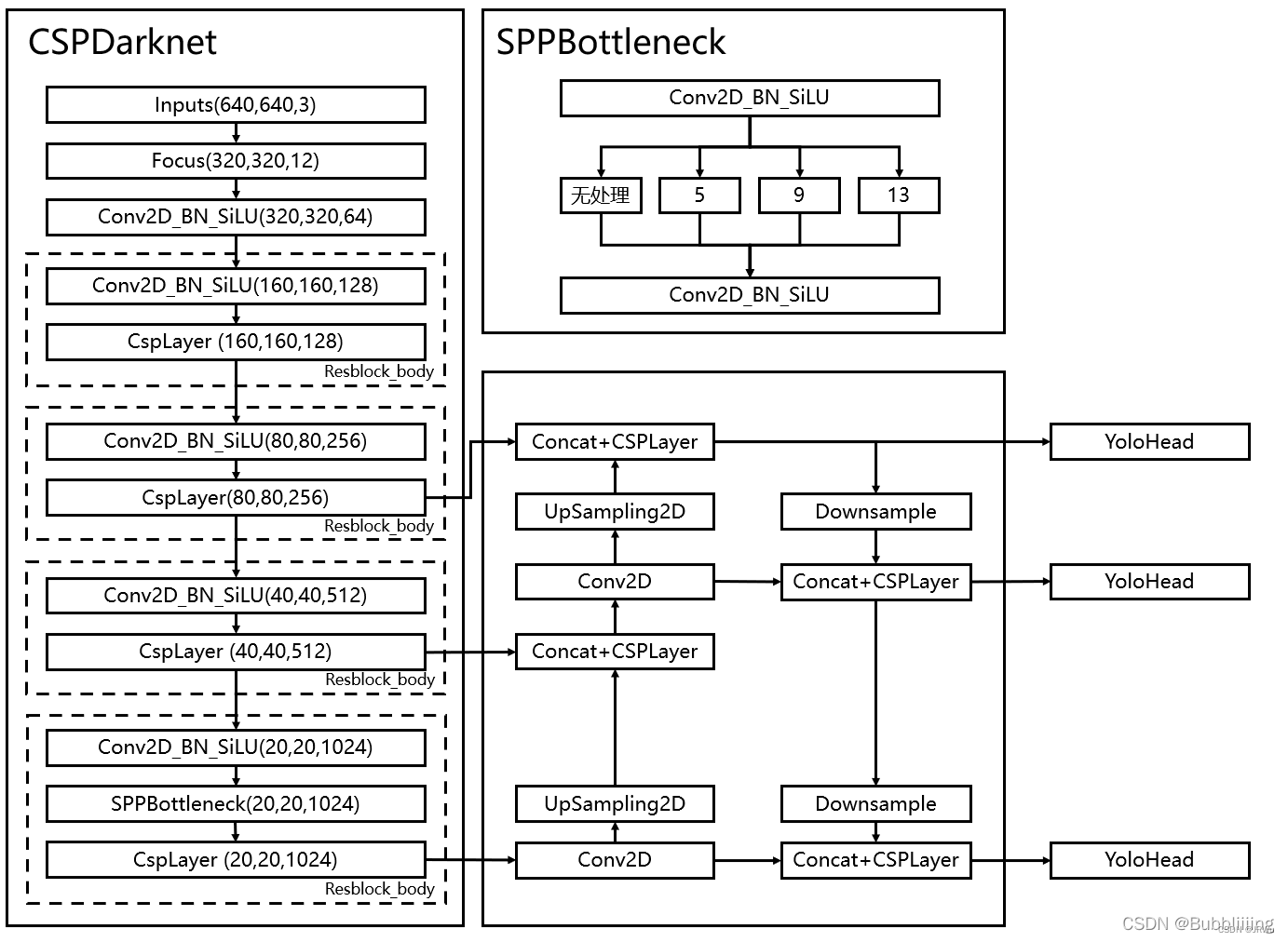
和之前版本的Yolo类似,整个YoloV5可以依然可以分为三个部分,分别是Backbone,FPN以及Yolo Head。
Backbone可以被称作YoloV5的主干特征提取网络,根据它的结构以及之前Yolo主干的叫法,我一般叫它CSPDarknet(Cross Stage Partial),输入的图片首先会在CSPDarknet里面进行特征提取,提取到的特征可以被称作特征层,是输入图片的特征集合。在主干部分,我们获取了三个特征层进行下一步网络的构建,这三个特征层我称它为有效特征层。
FPN+PAN:FPN可以被称作YoloV5的加强特征提取网络(特征金字塔),在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的有效特征层被用于继续提取特征。在YoloV5里依然使用到了Panet(基于提议的实例分割框架下的路径聚合网络Path Aggregation Network)的结构,我们不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。
PANet(Path Aggregation Network)最大的贡献是提出了一个自顶向下和自底向上的双向融合骨干网络,同时在最底层和最高层之间添加了一条**“short-cut”**,用于缩短层之间的路径。
PANet还提出了自适应特征池化和全连接融合两个模块。
其中自适应特征池化可以用于聚合不同层之间的特征,保证特征的完整性和多样性,而通过全连接融合可以得到更加准确的预测mask。
Yolo Head是YoloV5的分类器与回归器(分类:离散变量预测如天气晴或阴,回归:连续变量预测如气温几度),通过CSPDarknet和FPN,我们已经可以获得三个加强过的有效特征层。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每一个特征点都有通道数个特征。Yolo Head实际上所做的工作就是对特征点进行判断,判断特征点是否有物体与其对应。与以前版本的Yolo一样,YoloV5所用的解耦头是一起的,也就是分类和回归在一个1X1卷积里实现。
因此,整个YoloV5网络所作的工作就是特征提取-特征加强-预测特征点对应的物体情况。
二、网络结构分析
(1)输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构
(4)Prediction:GIOU_Loss
1、主干网络Backbone(即CSPDarknet)
YoloV5使用的Backbone(主干特征提取网络)为CSPDarknet,五个重要特点:
1、使用了残差网络Residual,CSPDarknet中的残差卷积可以分为两个部分,主干部分是一次1X1的卷积和一次3X3的卷积;残差边部分不做任何处理,直接将主干的输入与输出结合。整个YoloV5的主干部分都由残差卷积构成:
# 使用了残差网络Residual,CSPDarknet中的残差卷积可以分为两个部分,主干部分是一次1X1的卷积和一次3X3的卷积;# 残差边部分不做任何处理,直接将主干的输入与输出结合。整个YoloV5的主干部分都由残差卷积构成:# 残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,# 缓解了在深度神经网络中增加深度带来的梯度消失问题。classBottleneck(nn.Module):# Standard bottleneckdef__init__(self, c1, c2, shortcut=True, g=1, e=0.5):# ch_in, ch_out, shortcut, groups, expansionsuper(Bottleneck, self).__init__()
c_=int(c2* e)# hidden channels
self.cv1= Conv(c1, c_,1,1)
self.cv2= Conv(c_, c2,3,1, g=g)
self.add= shortcutand c1== c2defforward(self, x):return x+ self.cv2(self.cv1(x))if self.addelse self.cv2(self.cv1(x))#卷积完成之后直接将主干的输入与输出结合残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
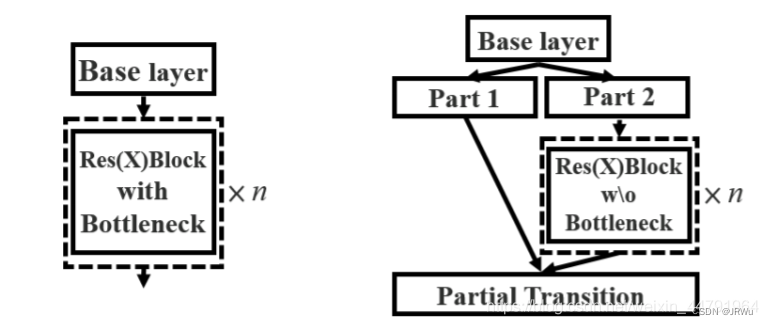
2、使用**CSPnet(Cross Stage Partial Network)**网络结构(每层是CSPlayer),CSPnet结构并不算复杂,就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:主干部分继续进行原来的残差块的堆叠;另一部分则像一个残差边一样,经过少量处理直接连接到最后。因此可以认为CSP中存在一个大的残差边。
引出一个大的残差边,跳过特征提取过程,将大结构块的输入和输出直接相接
在 CSPResNe(X)t 结构中,输入特征图在通道维度被分为两个部分,第一部分被保留下来,第二部分则经过多个残差块向后传递,最后将两者在 CSPNet 结构的末端进行合并,这样跨阶段拆分与合并的网络构造有效降低了梯度信息重复的可能性,增加了梯度组合的多样性,有利于提高模型的学习能力,并且降低了网络中的数据传递量与计算量。
# 使用CSPnet网络结构,CSPnet结构并不算复杂,就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:主干部分继续进行原来的残差块的堆叠;# 另一部分则像一个残差边一样,经过少量处理直接连接到最后。因此可以认为CSP中存在一个大的残差边。classC3(nn.Module):# CSP Bottleneck with 3 convolutionsdef__init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):# ch_in, ch_out, number, shortcut, groups, expansionsuper(C3, self).__init__()
c_=int(c2* e)# hidden channels# 卷积1
self.cv1= Conv(c1, c_,1,1)
self.cv2= Conv(c1, c_,1,1)
self.cv3= Conv(2* c_, c2,1)# act=FReLU(c2)
self.m= nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0)for _inrange(n)])# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])defforward(self, x):return self.cv3(torch.cat((
self.m(self.cv1(x)),#CSPlayer的主干部分,利用卷积1进行简单的通道数调整后,不断利用残差结构进行特征提取
self.cv2(x)), dim=1))3、使用了Focus网络结构,这个网络结构是在YoloV5里面使用到比较有趣的网络结构,具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。拼接起来的特征层相对于原先的三通道变成了十二个通道,下图很好的展示了Focus结构,一看就能明白。(高宽压缩通道扩张)(新的YoloV5用6*6的卷积替代了Focus,更快)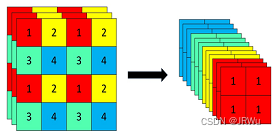
# focus网络构建 具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,# 此时宽高信息就集中到了通道信息,输入通道扩充了四倍。拼接起来的特征层相对于原先的三通道变成了十二个通道(高宽压缩通道扩张)classFocus(nn.Module):def__init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):# ch_in, ch_out, kernel, stride, padding, groupssuper(Focus, self).__init__()# 卷积标准化加激活函数
self.conv= Conv(c1*4, c2, k, s, p, g, act)defforward(self, x):# 320, 320, 12 (卷积 标准化加激活函数变成)=> 320, 320, 64(设置的输出通道数是64)return self.conv(# 640, 640, 3 => 320, 320, 12# 每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,
torch.cat([
x[...,::2,::2],
x[...,1::2,::2],
x[...,::2,1::2],
x[...,1::2,1::2]],1))4、使用了SiLU激活函数,SiLU是Sigmoid和ReLU的改进版。SiLU具备无上界有下界、平滑、非单调的特性。SiLU在深层模型上的效果优于 ReLU。可以看做是平滑的ReLU激活函数。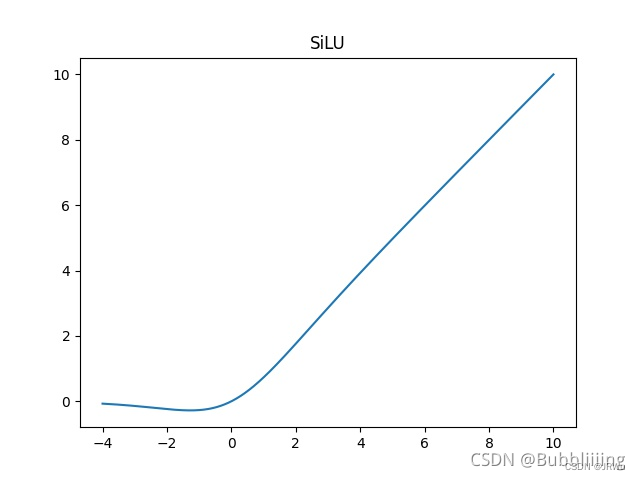
# 使用了SiLU激活函数,SiLU是Sigmoid和ReLU的改进版。SiLU具备无上界有下界、平滑、非单调的特性。# SiLU在深层模型上的效果优于 ReLU。可以看做是平滑的ReLU激活函数。classSiLU(nn.Module):@staticmethoddefforward(x):return x* torch.sigmoid(x)ReLU激活函数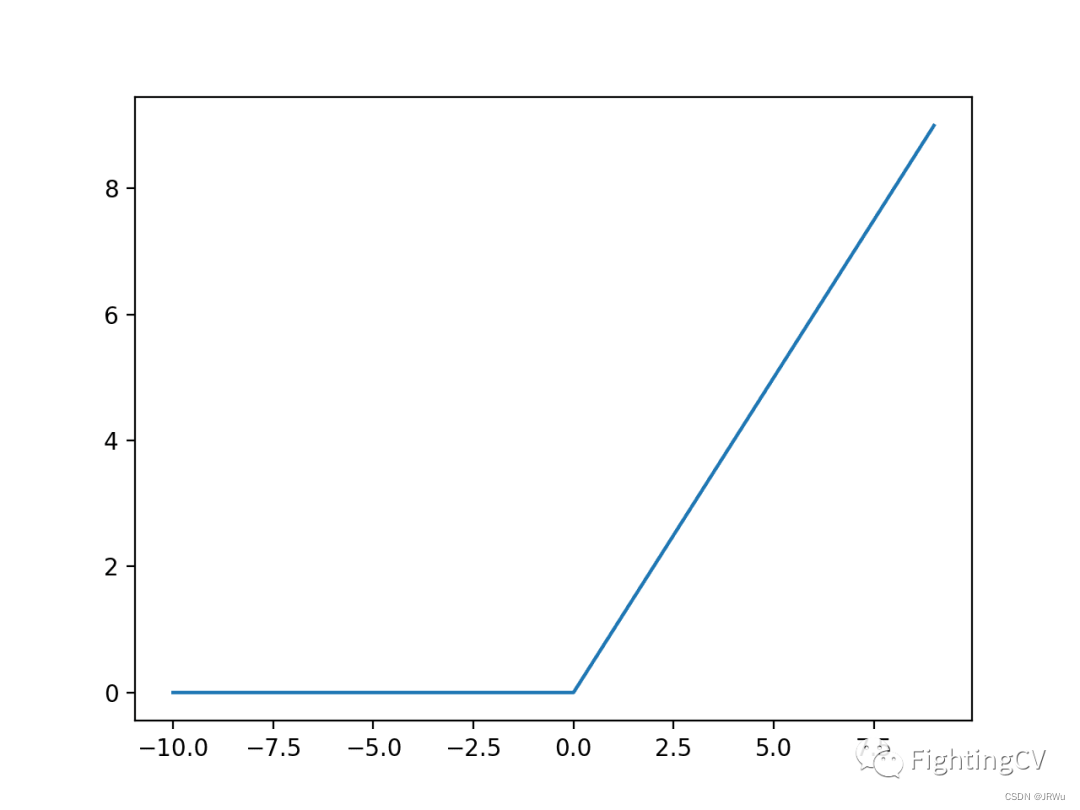
5、使用了SPP结构,通过不同池化核大小的最大池化进行特征提取,提高网络的感受野。在YoloV4中,SPP是用在FPN里面的,在YoloV5中,SPP模块被用在了主干特征提取网络中。
SPP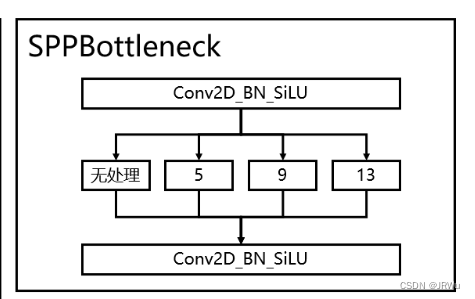
卷积调整通道数之后利用不同池化核的最大池化核(5 9 13 )来进行特征提取 除了5 9 13 还有一个没有处理的
四个部分堆叠然后卷积标准化加激活函数进行通道数的调整
# 使用了SPP结构,通过不同池化核大小的最大池化进行特征提取,提高网络的感受野。# 在YoloV4中,SPP是用在FPN里面的,在YoloV5中,SPP模块被用在了主干特征提取网络中。classSPP(nn.Module):# Spatial pyramid pooling layer used in YOLOv3-SPPdef__init__(self, c1, c2, k=(5,9,13)):super(SPP, self).__init__()
c_= c1//2# hidden channels
self.cv1= Conv(c1, c_,1,1)# 卷积调整通道数
self.cv2= Conv(c_*(len(k)+1), c2,1,1)# 四个部分堆叠然后卷积进行通道数调整# 卷积调整通道数之后利用不同池化核的最大池化核(5 9 13 )来进行特征提取 除了5 9 13 还有一个没有处理的# 四个部分组合然后卷积标准化加激活函数进行通道数的调整
self.m= nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x//2)for xin k])defforward(self, x):
x= self.cv1(x)return self.cv2(torch.cat([x]+[m(x)for min self.m],1))# 四个部分堆叠主干代码CSPDarknet.py:
import torchimport torch.nnas nn# 使用了SiLU激活函数,SiLU是Sigmoid和ReLU的改进版。SiLU具备无上界有下界、平滑、非单调的特性。# SiLU在深层模型上的效果优于 ReLU。可以看做是平滑的ReLU激活函数。classSiLU(nn.Module):@staticmethoddefforward(x):return x* torch.sigmoid(x)defautopad(k, p=None):if pisNone:
p= k//2ifisinstance(k,int)else[x//2for xin k]return p# focus网络构建 具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,# 此时宽高信息就集中到了通道信息,输入通道扩充了四倍。拼接起来的特征层相对于原先的三通道变成了十二个通道(高宽压缩通道扩张)classFocus(nn.Module):def__init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):# ch_in, ch_out, kernel, stride, padding, groupssuper(Focus, self).__init__()# 卷积标准化加激活函数
self.conv= Conv(c1*4, c2, k, s, p, g, act)defforward(self, x):# 320, 320, 12 (卷积 标准化加激活函数变成)=> 320, 320, 64(设置的输出通道数是64)return self.conv(# 640, 640, 3 => 320, 320, 12# 每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,
torch.cat([
x[...,::2,::2],
x[...,1::2,::2],
x[...,::2,1::2],
x[...,1::2,1::2]],1))classConv(nn.Module):def__init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):super(Conv, self).__init__()
self.conv= nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn= nn.BatchNorm2d(c2, eps=0.001, momentum=0.03)
self.act= SiLU()if actisTrueelse(actifisinstance(act, nn.Module)else nn.Identity())defforward(self, x):return self.act(self.bn(self.conv(x)))deffuseforward(self, x):return self.act(self.conv(x))# 使用了残差网络Residual,CSPDarknet中的残差卷积可以分为两个部分,主干部分是一次1X1的卷积和一次3X3的卷积;# 残差边部分不做任何处理,直接将主干的输入与输出结合。整个YoloV5的主干部分都由残差卷积构成:# 残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,# 缓解了在深度神经网络中增加深度带来的梯度消失问题。classBottleneck(nn.Module):# Standard bottleneckdef__init__(self, c1, c2, shortcut=True, g=1, e=0.5):# ch_in, ch_out, shortcut, groups, expansionsuper(Bottleneck, self).__init__()
c_=int(c2* e)# hidden channels
self.cv1= Conv(c1, c_,1,1)
self.cv2= Conv(c_, c2,3,1, g=g)
self.add= shortcutand c1== c2defforward(self, x):return x+ self.cv2(self.cv1(x))if self.addelse self.cv2(self.cv1(x))#卷积完成之后直接将主干的输入与输出结合# 使用CSPnet网络结构,CSPnet结构并不算复杂,就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:主干部分继续进行原来的残差块的堆叠;# 另一部分则像一个残差边一样,经过少量处理直接连接到最后。因此可以认为CSP中存在一个大的残差边。classC3(nn.Module):# CSP Bottleneck with 3 convolutionsdef__init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):# ch_in, ch_out, number, shortcut, groups, expansionsuper(C3, self).__init__()
c_=int(c2* e)# hidden channels# 卷积1
self.cv1= Conv(c1, c_,1,1)
self.cv2= Conv(c1, c_,1,1)
self.cv3= Conv(2* c_, c2,1)# act=FReLU(c2)
self.m= nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0)for _inrange(n)])# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])defforward(self, x):return self.cv3(torch.cat((
self.m(self.cv1(x)),#CSPlayer的主干部分,利用卷积1进行简单的通道数调整后,不断利用残差结构进行特征提取
self.cv2(x)), dim=1))# 使用了SPP结构,通过不同池化核大小的最大池化进行特征提取,提高网络的感受野。# 在YoloV4中,SPP是用在FPN里面的,在YoloV5中,SPP模块被用在了主干特征提取网络中。classSPP(nn.Module):# Spatial pyramid pooling layer used in YOLOv3-SPPdef__init__(self, c1, c2, k=(5,9,13)):super(SPP, self).__init__()
c_= c1//2# hidden channels
self.cv1= Conv(c1, c_,1,1)# 卷积调整通道数
self.cv2= Conv(c_*(len(k)+1), c2,1,1)# 四个部分堆叠然后卷积进行通道数调整# 卷积调整通道数之后利用不同池化核的最大池化核(5 9 13 )来进行特征提取 除了5 9 13 还有一个没有处理的# 四个部分组合然后卷积标准化加激活函数进行通道数的调整
self.m= nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x//2)for xin k])defforward(self, x):
x= self.cv1(x)return self.cv2(torch.cat([x]+[m(x)for min self.m],1))# 四个部分堆叠# 该类完成YoloV5主干构建