目录
前言
一般从数据库或者是从日志文件读出的数据均带有时间序列,做时序数据处理或者实时分析都需要对其时间序列进行归类归档。而Pandas是处理这些数据很好用的工具包。此篇博客基于Jupyter之上进行演示,本篇博客的愿景是希望我或者读者通过阅读这篇博客能够学会方法并能实际运用。希望读者看完能够提出问题或者看法,博主会长期维护博客做及时更新。纯分享,希望大家喜欢。
一、获取时间
python自带datetime库,通过调用此库可以获取本地时间
from datetime import datetime
datetime.now()![]()
同时也可以独立获取年月日:
datetime.now().day
datetime.now().year
datetime.now().mothisoweekday()获取符合ISO标准的指定日期所在的星期数:
datetime.now().isoweekday()![]() 为星期二。
为星期二。
但也有weekeday()方法但是是从0开始,也就是说0也就是周一,需要加一转为周数:
datetime.now().weekday()+1![]()
datetime可以将日期(date)和时间(time)分隔开:
datetime.now().date()![]()
datetime.now().time()![]()
也可以用timetuple()函数将整个时间拆分为结构体:
datetime.now().timetuple()![]()
要转换为自定义熟悉的时间表达可以使用strftime()函数,其输出代码格式有以下几种:
| 输出代码 | 说明 |
| %H | 24小时制[00-23] |
| %I | 12小时制[01-12] |
| %M | 60分钟[00-59] |
| %S | 61秒钟[00,61](60和61用于闰秒) |
| %w | 星期一到星期日,但从0开始[0-6] |
| %U | 每年的第几周,周日指定为每周第一天 |
| %W | 每年的第几周,周一指定为每周第一天 |
| %F | %Y-%m-%d的简写形式,例如2022-05-17 |
| %D | %m%d%y的简写形式,例如05/17/2022 |
datetime.now().strftime('%Y-%m-%d')![]()
datetime.now().strftime('%m/%d/%Y %H:%M:%S')![]()
二、时间索引
时间索引是根据数据的时间来处理时序数据进行归档筛选的一种索引方式。
展示数据: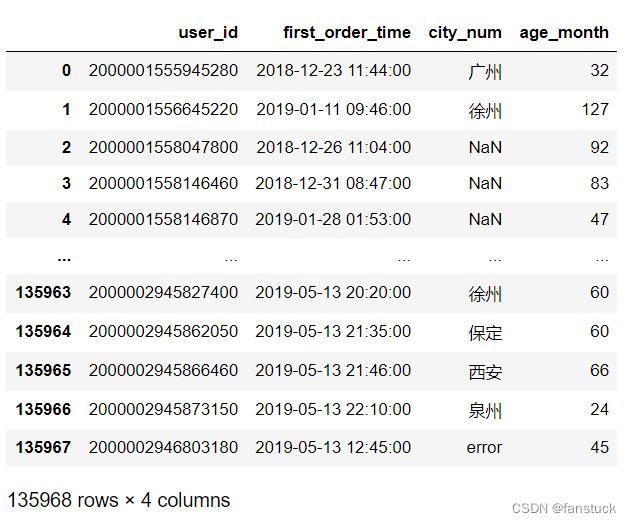
首先查看类型是否为 datetime类型,是该类型再重新设定索引,否则需要先把索引时间列转换为datetime类型再进行设定。
df1.set_index('first_order_time')若要查找2019年的数据,只需要在 后面加上日期即可:
df1['2019']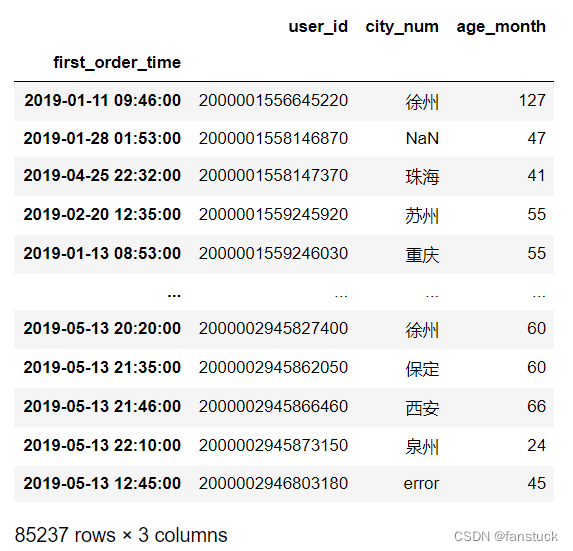
想要获取详细的日期的数据只需要在[]里面输入对应的日期即可:
df1['2019-05-13']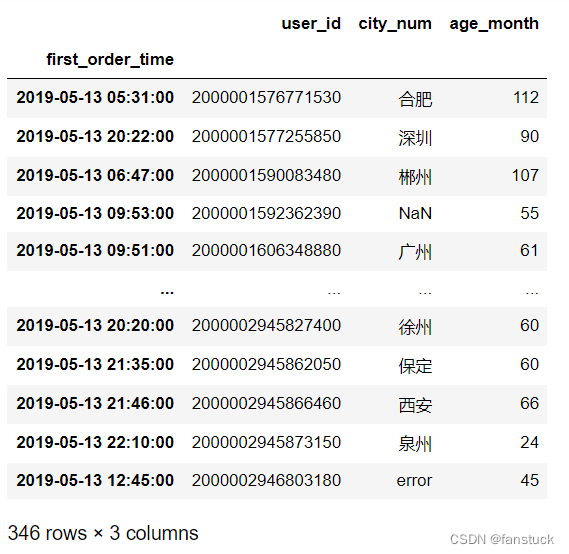
获取区间日期数据:
df1['2019-05-01':'2019-05-13']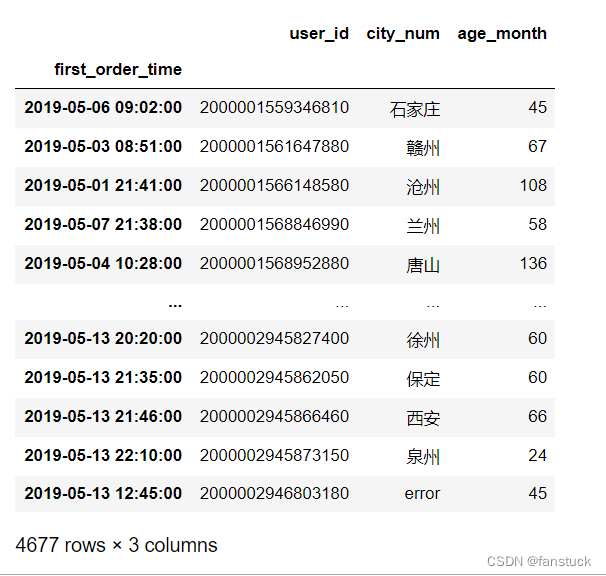
三、时间推移
如果时序数据提取出来时间并不符合对应时间戳,则可以使用timedelta进行推移时间:
timedelta类表示为时间差,可直接实例化也可以由两个datetime进行相减操作得到。

可表示的时间差依次为:
days,seconds,microseconds,minutes,hours,weeks
如我们要推移一天时间:
date = datetime(2019,5,10)
date+timedelta(days = 1)![]()
往后推移只需要减去对应天数就好了。
比起timedelta,有date offset可以直接进行时间推移,并不需要换算,效率比timedelta要快很多。
引入库:
from pandas.tseries.offsets import Day,Hour,Minute
date+Day(1)计算结果为timestamp:
![]()