回顾模型保存:torch.save(model.state_dict()),其中model.state_dict()是一个字典,里边存着我们模型各个部分的参数。在model中,我们需要更新其中的参数,训练结束将参数保存下来。但在某些时候,我们可能希望模型中的某些参数参数不更新(从开始到结束均保持不变),但又希望参数保存下来(model.state_dict() ),这是我们就会用到 register_buffer()
即
模型中需要保存下来的参数包括两种:
- 一种是反向传播需要被optimizer更新的,称之为 parameter
- 一种是反向传播不需要被optimizer更新,称之为 buffer
第一种参数我们可以通过
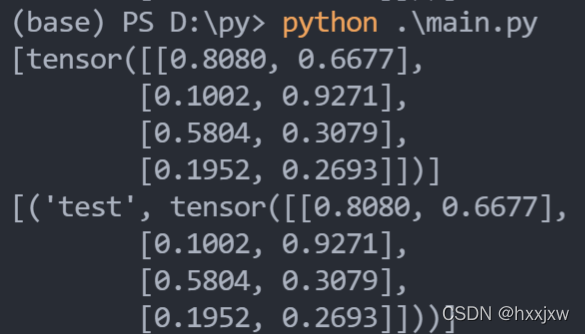
model.parameters()返回;第二种参数我们可以通过model.buffers()返回。因为我们的模型保存的是state_dict返回的OrderDict,所以这两种参数不仅要满足是否需要被更新的要求,还需要被保存到OrderDict。import torch from torch import nn class MyModule(nn.Module): def __init__(self, input_size, output_size): super(MyModule, self).__init__() self.register_buffer('test',torch.rand(input_size, output_size)) self.linear = nn.Linear(input_size, output_size) def forward(self, x): return self.linear(x) model = MyModule(4, 2) print(list(model.buffers())) print(list(model.named_buffers()))
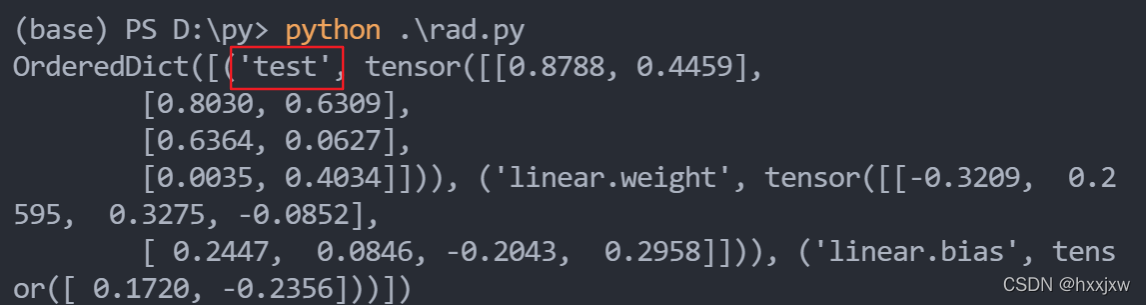
输出model.state_dict()会包含buffer的
import torch from torch import nn class MyModule(nn.Module): def __init__(self, input_size, output_size): super(MyModule, self).__init__() self.register_buffer('test',torch.rand(input_size, output_size)) self.linear = nn.Linear(input_size, output_size) def forward(self, x): return self.linear(x) model = MyModule(4, 2) print(model.state_dict())