微信搜索:“二十同学” 公众号,欢迎关注一条不一样的成长之路
什么是Hbase
Hbase是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,利用Hbase技术可在廉价的PC Server上搭建大规模结构化存储集群。
利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理 Hbase中的海量数据,利用Zookeeper作为其分布式协同服务
主要用来存储非结构化和半结构化的松散数据(列存NoSQL数据库)
Hbase是Google BigTable的开源实现,与Google BigTable利用GFS作为其文件存储系统类似,Hbase利用Hadoop HDFS作为其文件存储系统;
Google运行MapReduce来处理BigTable中的海量数据,Hbase同样利用Hadoop MapReduce来处理Hbase中的海量数据;
Google BigTable利用Chubby作为协同服务,Hbase利用Zookeeper作为协同服务。
Hbase是一个分布式的、面向列的开源数据库,它不同于一般的关系数据库,是一个适合于非结构化数据存储的数据库。另一个不同的是Hbase基于列的而不是基于行的模式。Hbase使用和 BigTable非常相同的数据模型。用户存储数据行在一个表里。一个数据行拥有一个可选择的键和任意数量的列,一个或多个列组成一个ColumnFamily,一个Fmaily下的列位于一个HFile中,易于缓存数据。表是疏松的存储的,因此用户可以给行定义各种不同的列。在Hbase中数据按主键排序,同时表按主键划分为多个Region。
在分布式的生产环境中,Hbase 需要运行在 HDFS 之上,以 HDFS 作为其基础的存储设施。Hbase 上层提供了访问的数据的 Java API 层,供应用访问存储在 Hbase 的数据。在 Hbase 的集群中主要由 Master 和 Region Server 组成,以及 Zookeeper。
Hbase模块
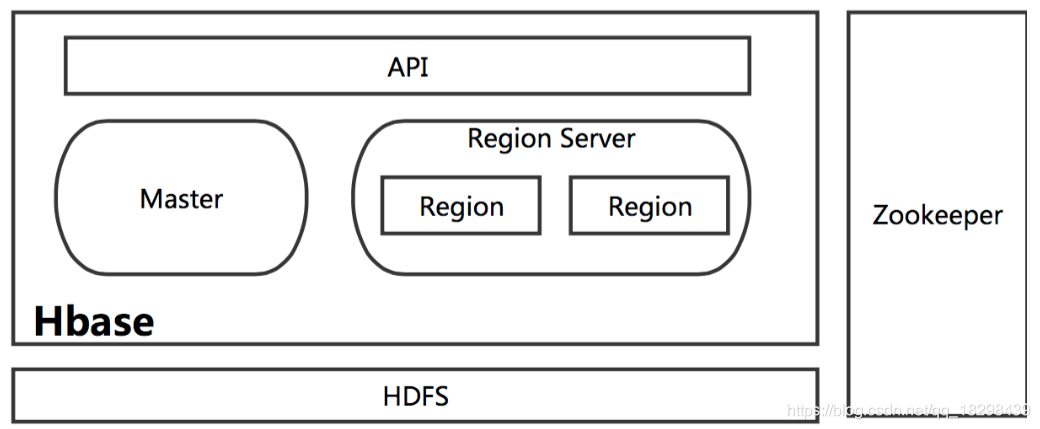
简单介绍一下 Hbase 中相关模块的作用:
- Master
Hbase Master用于协调多个Region Server,侦测各个RegionServer之间的状态,并平衡RegionServer之间的负载。HbaseMaster还有一个职责就是负责分配Region给RegionServer。Hbase允许多个Master节点共存,但是这需要Zookeeper的帮助。不过当多个Master节点共存时,只有一个Master是提供服务的,其他的Master节点处于待命的状态。当正在工作的Master节点宕机时,其他的Master则会接管Hbase的集群。 - Region Server
对于一个RegionServer而言,其包括了多个Region。RegionServer的作用只是管理表格,以及实现读写操作。Client直接连接RegionServer,并通信获取Hbase中的数据。对于Region而言,则是真实存放Hbase数据的地方,也就说Region是Hbase可用性和分布式的基本单位。如果当一个表格很大,并由多个CF组成时,那么表的数据将存放在多个Region之间,并且在每个Region中会关联多个存储的单元(Store)。 - Zookeeper
对于 Hbase 而言,Zookeeper的作用是至关重要的。首先Zookeeper是作为Hbase Master的HA解决方案。也就是说,是Zookeeper保证了至少有一个Hbase Master 处于运行状态。并且Zookeeper负责Region和Region Server的注册。其实Zookeeper发展到目前为止,已经成为了分布式大数据框架中容错性的标准框架。不光是Hbase,几乎所有的分布式大数据相关的开源框架,都依赖于Zookeeper实现HA。
Hbase的特点
Hbase 中的表一般有以下特点。
1)大:一个表可以有上亿行,上百万列。
2)面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
3)稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
Hbase数据模型
逻辑视图
- RowKey:是Byte array,是表中每条记录的“主键”,方便快速查找,Rowkey的设计非常重要;
- Column Family:列族,拥有一个名称(string),包含一个或者多个相关列;
- Column:属于某一个columnfamily,familyName:columnName,每条记录可动态添加;
- Version Number:类型为Long,默认值是系统时间戳,可由用户自定义;
- Value(Cell):Byte array。
物理模型:
- 每个column family存储在HDFS上的一个单独文件中,空值不会被保存。
- Key 和 Version number在每个column family中均有一份;
- Hbase为每个值维护了多级索引,即:<key, columnfamily, columnname, timestamp>;
- 表在行的方向上分割为多个Region;
- Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上。
- Region按大小分割的,随着数据增多,Region不断增大,当增大到一个阀值的时候,Region就会分成两个新的Region;
- Region虽然是分布式存储的最小单元,但并不是存储的最小单元。每个Region包含着多个Store对象。每个Store包含一个MemStore或若干StoreFile,StoreFile包含一个或多个HFile。MemStore存放在内存中,StoreFile存储在HDFS上。
Hbase存储架构
从Hbase的架构图上可以看出,Hbase中的存储包括HMaster、HRegionSever、HRegion、HLog、Store、MemStore、StoreFile、HFile等,以下是Hbase存储架构图:
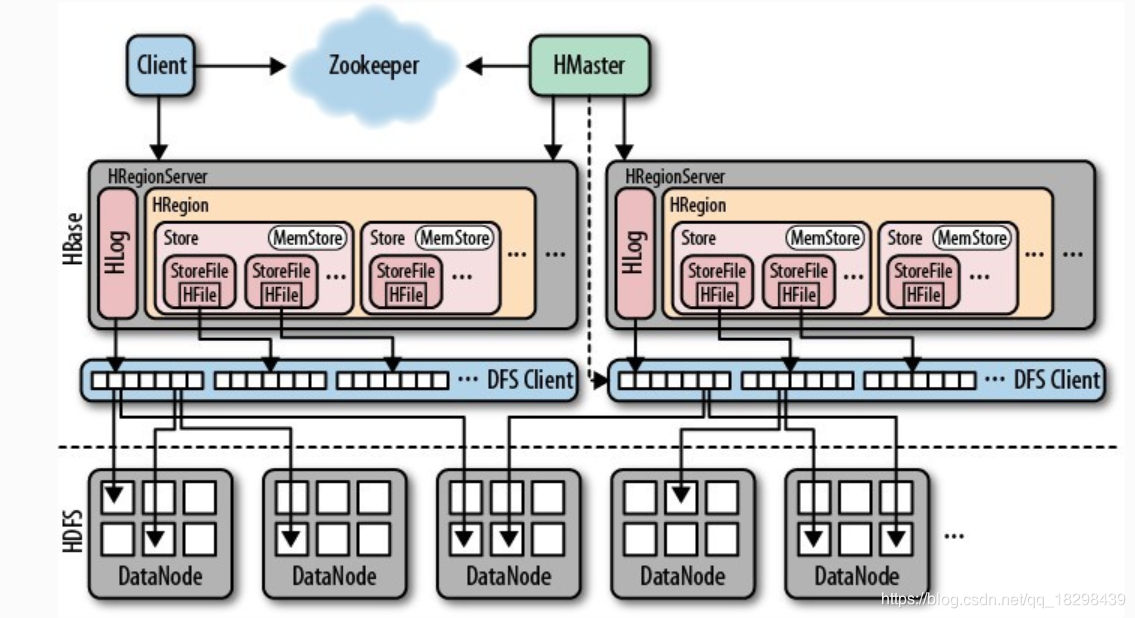
Hbase中的每张表都通过键按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过256M就要被分割成两个,这个过程由HRegionServer管理,而HRegion的分配由HMaster管理。
HMaster的作用:
- 为HRegionServer分配HRegion
- 负责HRegionServer的负载均衡
- 发现失效的HRegionServer并重新分配
- HDFS上的垃圾文件回收
- 处理Schema更新请求
HRegionServer的作用:
- 维护HMaster分配给它的HRegion,处理对这些HRegion的IO请求
- 负责切分正在运行过程中变得过大的HRegion
可以看到,Client访问Hbase上的数据并不需要HMaster参与,寻址访问ZooKeeper和HRegionServer,数据读写访问HRegionServer,HMaster仅仅维护Table和Region的元数据信息,Table的元数据信息保存在ZooKeeper上,负载很低。HRegionServer存取一个子表时,会创建一个HRegion对象,然后对表的每个列簇创建一个Store对象,每个Store都会有一个MemStore和0或多个StoreFile与之对应,每个StoreFile都会对应一个HFile,HFile就是实际的存储文件。因此,一个HRegion有多少列簇就有多少个Store。
一个HRegionServer会有多个HRegion和一个HLog。
HRegion
Table在行的方向上分割为多个HRegion,HRegion是Hbase中分布式存储和负载均衡的最小单元,即不同的HRegion可以分别在不同的HRegionServer上,但同一个HRegion是不会拆分到多个HRegionServer上的。HRegion按大小分割,每个表一般只有一个HRegion,随着数据不断插入表,HRegion不断增大,当HRegion的某个列簇达到一个阀值(默认256M)时就会分成两个新的HRegion。
1、<表名,StartRowKey, 创建时间>
2、由目录表(-ROOT-和.META.)记录该Region的EndRowKey
HRegion定位
HRegion被分配给哪个HRegionServer是完全动态的,所以需要机制来定位HRegion具体在哪个HRegionServer,Hbase使用三层结构来定位HRegion:
1、通过zk里的文件/Hbase/rs得到-ROOT-表的位置。-ROOT-表只有一个region。
2、通过-ROOT-表查找.META.表的第一个表中相应的HRegion位置。其实-ROOT-表是.META.表的第一个region;.META.表中的每一个Region在-ROOT-表中都是一行记录。
3、通过.META.表找到所要的用户表HRegion的位置。用户表的每个HRegion在.META.表中都是一行记录。-ROOT-表永远不会被分隔为多个HRegion,保证了最多需要三次跳转,就能定位到任意的region。Client会将查询的位置信息保存缓存起来,缓存不会主动失效,因此如果Client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的HRegion,其中三次用来发现缓存失效,另外三次用来获取位置信息。
Store
每一个HRegion由一个或多个Store组成,至少是一个Store,Hbase会把一起访问的数据放在一个Store里面,即为每个ColumnFamily建一个Store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个MemStore和0或者多个StoreFile组成。 Hbase以Store的大小来判断是否需要切分HRegion。
MemStore
MemStore 是放在内存里的,保存修改的数据即keyValues。当MemStore的大小达到一个阀值(默认64MB)时,MemStore会被Flush到文件,即生成一个快照。目前Hbase会有一个线程来负责MemStore的Flush操作。
StoreFile
MemStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。
HFile
Hbase中KeyValue数据的存储格式,是Hadoop的二进制格式文件。 首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。
Trailer中有指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息。Data Block是Hbase IO的基本单元,为了提高效率,
HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定(默认块大小64KB),大号的Block有利于顺序Scan,小号的Block利于随机查询。每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成,Magic内容就是一些随机数字,目的是防止数据损坏,结构如下。

HFile结构图如下:
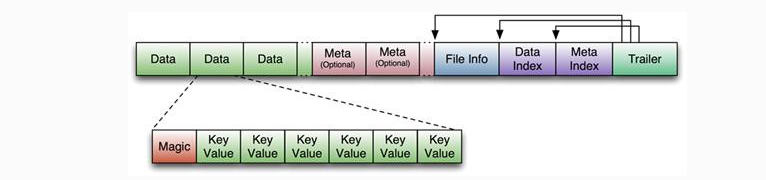
Data Block段用来保存表中的数据,这部分可以被压缩。 Meta Block段(可选的)用来保存用户自定义的kv段,可以被压缩。 FileInfo段用来保存HFile的元信息,不能被压缩,用户也可以在这一部分添加自己的元信息。 Data Block Index段(可选的)用来保存Meta Blcok的索引。 Trailer这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会首先读取Trailer,Trailer保存了每个段的起始位置(段的Magic Number用来做安全check),然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个 block读取到内存中,再找到需要的key。DataBlock Index采用LRU机制淘汰。 HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。(备注: DataBlock Index的缺陷。 a) 占用过多内存 b) 启动加载时间缓慢)
HLog
HLog(WAL log):WAL意为write ahead log,用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server 宕机,就可以从log中进行恢复。
LogFlusher
定期的将缓存中信息写入到日志文件中
LogRoller
对日志文件进行管理维护
WAL(Write-Ahead Logging)是数据库系统中保障原子性和持久性的技术,通过使用WAL可以将数据的随机写入变为顺序写入,可以提高数据写入的性能。在Hbase中写入数据时,会将数据写入内存同时写wal日志,为防止日志丢失,日志是写在hdfs上的。
默认是每个RegionServer有1个WAL,在Hbase1.0开始支持多个WALHBASE-5699,这样可以提高写入的吞吐量。配置参数为Hbase.wal.provider=multiwal,支持的值还有defaultProvider和filesystem(这2个是同样的实现)。
WAL的持久化的级别有如下几种:
- SKIP_WAL:不写wal日志,这种可以较大提高写入的性能,但是会存在数据丢失的危险,只有在大批量写入的时候才使用(出错了可以重新运行),其他情况不建议使用。
- ASYNC_WAL:异步写入
- SYNC_WAL:同步写入wal日志文件,保证数据写入了DataNode节点。
- FSYNC_WAL: 目前不支持了,表现是与SYNC_WAL是一致的
- USE_DEFAULT: 如果没有指定持久化级别,则默认为USE_DEFAULT, 这个为使用Hbase全局默认级别(SYNC_WAL)
先看看wal写入中的几个主要的类
1. WALKey:wal日志的key,包括regionName:日志所属的region
tablename:日志所属的表,writeTime:日志写入时间,clusterIds:cluster的id,在数据复制的时候会用到。
2.WALEdit:在Hbase的事务日志中记录一系列的修改的一条事务日志。另外WALEdit实现了Writable接口,可用于序列化处理。
3. FSHLog: WAL的实现类,负责将数据写入文件系统
在每个wal的写入这里使用的是多生产者单消费者的模式,这里使用到了disruptor框架,将WALKey和WALEdit信息封装为FSWALEntry,然后通过RingBufferTruck放入RingBuffer中。接下来看hlog的写入流程,分为以下3步:
- 日志写入缓存:由rpcHandler将日志信息写入缓存ringBuffer.
- 缓存数据写入文件系统:每个FSHLog有一个线程负责将数据写入文件系统(HDFS)
- 数据同步:如果操作的持久化级别为(SYNC_WAL或者USE_DEFAULT 则需进行数据同步处理
下面来详细说明一下各类线程是如何配合来实现这几步操作的,
- rpcHandler线程负责将日志信息(FSWALEntry)写入缓存RingBbuffer,在操作日志写完后,rpcHandler会调用wal的sync方法,进行数据同步,其实际处理为写入一个SyncFuture到RingBuffer,然后blocking一直到syncFuture处理完成。
- wal线程从缓存RingBuffer中取数据,如果为日志(FSWALEntry)就调用Writer将数据写入文件系统,如果为SyncFuture,则由专门的同步线程来进行同步处理。
整体处理流程图如下: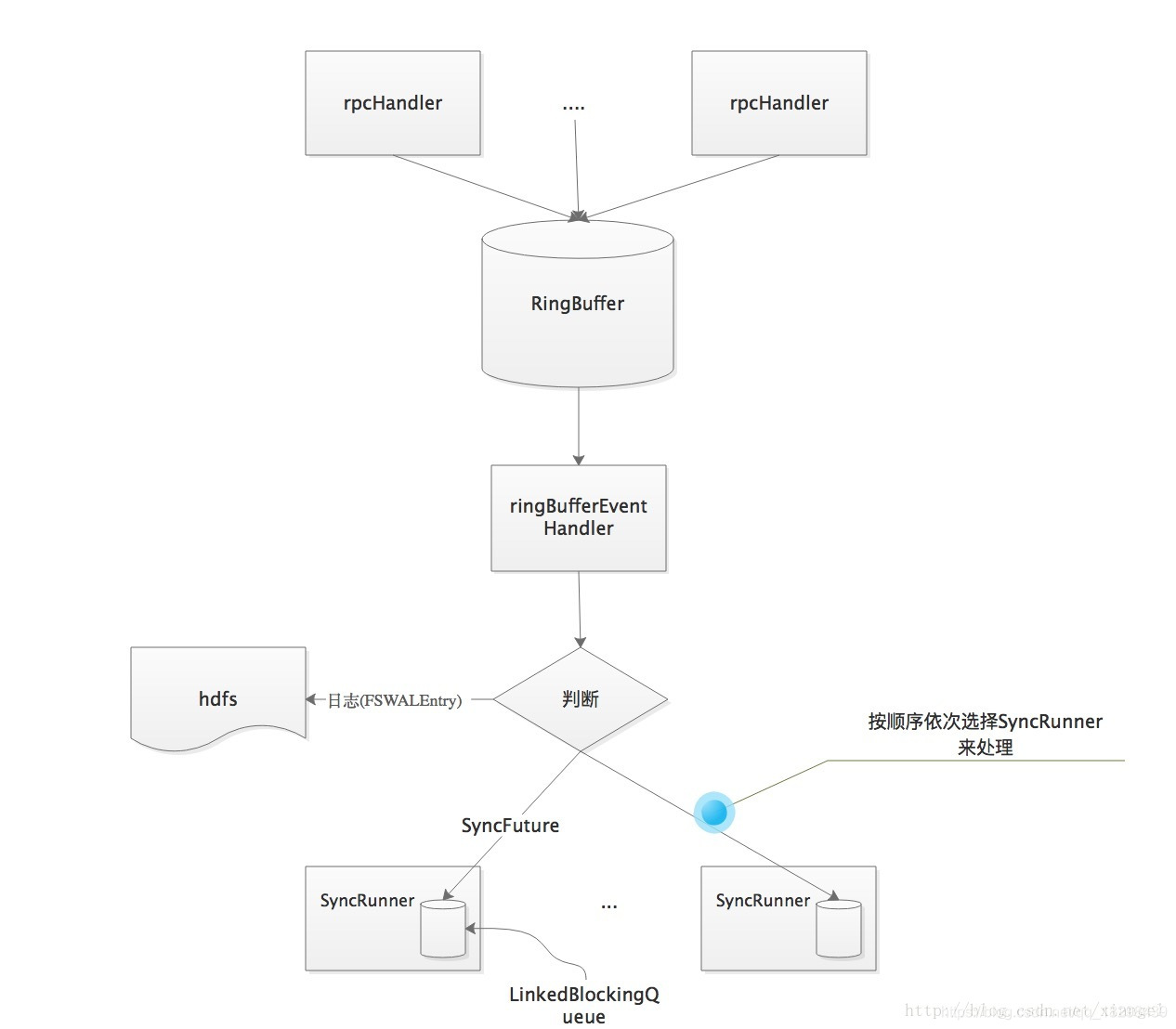
HLog的写入
wal写入文件系统是通过Writer来写入的,其实际类为ProtobufLogWriter,使用的是Protobuf的格式持久化处理。使用Protobuf格式有如下优势:
- 性能较高
- 结构更加紧凑,节省空间
- 方便扩展以及支持其他语言,通过其他语言来解析日志。
写入的日志中是按WALKey和WALEdit来依次存储的(具体内容见前面WALKey和WALEdit类的说明),另外还将WALKey和WALEdit分别进行了压缩处理。
wal同步过程
每个wal中有一个RingBufferEventHandler对象,其中用数组管理着多个SyncRunner线程(由参数Hbase.regionserver.hlog.syncer.count配置,默认5)来进行同步处理,每个SyncRunner对象里面有一个LinkedBlockingQueue(syncFutures,大小为参数{Hbase.regionserver.handler.count默认值200}*3
另外这里的SyncFuture是每个rpcHandler线程拥有一个,由wal中的private final Map
class RingBufferEventHandler implements EventHandler<RingBufferTruck>, LifecycleAware {
private final SyncRunner [] syncRunners;
private final SyncFuture [] syncFutures;
...
}
private class SyncRunner extends HasThread {
private volatile long sequence;
// Keep around last exception thrown. Clear on successful sync.
private final BlockingQueue<SyncFuture> syncFutures;
...
}这里在处理ringBuffer中的syncFuture时,不是每有一个就提交到syncRunner处理,而是按批来处理的,这里的批分2种情况:
- 从ringBuffer中取到的一批数据(为提高效率,在disruptor框架中是按批从ringBuffer中取数据的,具体的请看disruptor的相关文档),如果这批数据中的syncFuture个数<{Hbase.regionserver.handler.count默认值200},则按一批处理
- 如果这一批数据中的syncFuture个数>={Hbase.regionserver.handler.count默认值200}个数,则按{Hbase.regionserver.handler.count默认值200}分批处理。
如果达到了批大小,就从syncRunner数组中顺序选择下一个SyncRunner,将这批数据插入该SyncRunner的BlockingQueue中。最后由SyncRunner线程进行hdfs文件同步处理。为保证数据的不丢失,rpc请求需要保证wal日志写入成功后才能返回,这里Hbase做了一系列的优化处理的操作。
通过wal日志切换,这样可以避免产生单独的过大的wal日志文件,这样可以方便后续的日志清理(可以将过期日志文件直接删除)另外如果需要使用日志进行恢复时,也可以同时解析多个小的日志文件,缩短恢复所需时间。
wal触发切换的场景有如下几种:
- SyncRunner线程在处理日志同步后,如果有异常发生,就会调用requestLogRoll发起日志滚动请求
- SyncRunner线程在处理日志同步后, 检查当前在写的wal的日志大小是否超过配置{Hbase.regionserver.hlog.blocksize默认为hdfs目录块大小}*{Hbase.regionserver.logroll.multiplier默认0.95},超过后同样调用requestLogRoll发起日志滚动请求
- 每个RegionServer有一个LogRoller线程会定期滚动日志,滚动周期由参数{Hbase.regionserver.logroll.period默认值1个小时}控制
这里前面2种场景调用requestLogRoll发起日志滚动请求,最终也是通过LogRoller来执行日志滚动的操作。
当memstore中的数据刷新到hdfs后,那对应的wal日志就不需要了,FSHLog中有记录当前memstore中各region对应的最老的sequenceId,如果一个日志中的各个region的操作的最新的sequenceId均小于wal中记录的各个需刷新的region的最老sequenceId,说明该日志文件就不需要了,于是就会将该日志文件从./WALs目录移动到./oldWALs目录。这块是在前面日志滚动完成后调用cleanOldLogs来处理的。
由于wal日志还会用于跨集群的同步处理,所以wal日志失效后并不会立即删除,而是移动到oldWALs目录。由HMaster中的LogCleaner这个Chore线程来负责wal日志的删除,在LogCleaner内部通过参数{Hbase.master.logcleaner.plugins}以插件的方式来筛选出可以删除的日志文件。目前配置的插件有ReplicationLogCleaner、SnapshotLogCleaner和TimeToLiveLogCleaner
- TimeToLiveLogCleaner: 日志文件最后修改时间在配置参数{Hbase.master.logcleaner.ttl默认600秒}之前的可以删除
- ReplicationLogCleaner:如果有跨集群数据同步的需求,通过该Cleaner来保证那些在同步中的日志不被删除
- SnapshotLogCleaner: 被表的snapshot使用到了的wal不被删除
高可用
Write-Ahead-Log(WAL)保障数据高可用
我们理解下HLog的作用。Hbase中的HLog机制是WAL的一种实现,而WAL(一般翻译为预写日志)是事务机制中常见的一致性的实现方式。每个RegionServer中都会有一个HLog的实例,RegionServer会将更新操作(如 Put,Delete)先记录到 WAL(也就是HLo)中,然后将其写入到Store的MemStore,最终MemStore会将数据写入到持久化的HFile中(MemStore 到达配置的内存阀值)。这样就保证了Hbase的写的可靠性。如果没有 WAL,当RegionServer宕掉的时候,MemStore 还没有写入到HFile,或者StoreFile还没有保存,数据就会丢失。或许有的读者会担心HFile本身会不会丢失,这是由 HDFS 来保证的。在HDFS中的数据默认会有3份。因此这里并不考虑 HFile 本身的可靠性。
HFile由很多个数据块(Block)组成,并且有一个固定的结尾块。其中的数据块是由一个Header和多个Key-Value的键值对组成。在结尾的数据块中包含了数据相关的索引信息,系统也是通过结尾的索引信息找到HFile中的数据。
组件高可用
- Master容错:Zookeeper重新选择一个新的Master。如果无Master过程中,数据读取仍照常进行,但是,region切分、负载均衡等无法进行;
- RegionServer容错:定时向Zookeeper汇报心跳,如果一旦时间内未出现心跳,Master将该RegionServer上的Region重新分配到其他RegionServer上,失效服务器上“预写”日志由主服务器进行分割并派送给新的RegionServer;
- Zookeeper容错:Zookeeper是一个可靠地服务,一般配置3或5个Zookeeper实例。
Hbase读写流程
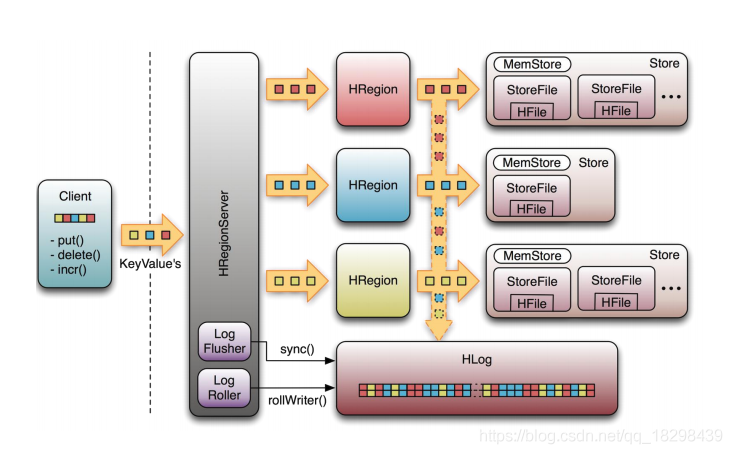
上图是RegionServer数据存储关系图。上文提到,Hbase使用MemStore和StoreFile存储对表的更新。数据在更新时首先写入HLog和MemStore。MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到Flush队列,由单独的线程Flush到磁盘上,成为一个StoreFile。与此同时,系统会在Zookeeper中记录一个CheckPoint,表示这个时刻之前的数据变更已经持久化了。当系统出现意外时,可能导致MemStore中的数据丢失,此时使用HLog来恢复CheckPoint之后的数据。
StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定阈值后,就会进行一次合并操作,将对同一个key的修改合并到一起,形成一个大的StoreFile。当StoreFile的大小达到一定阈值后,又会对 StoreFile进行切分操作,等分为两个StoreFile。
写操作流程
(1) Client通过Zookeeper的调度,向RegionServer发出写数据请求,在Region中写数据。
(2) 数据被写入Region的MemStore,直到MemStore达到预设阈值。
(3) MemStore中的数据被Flush成一个StoreFile。
(4) 随着StoreFile文件的不断增多,当其数量增长到一定阈值后,触发Compact合并操作,将多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除。
(5) StoreFiles通过不断的Compact合并操作,逐步形成越来越大的StoreFile。
(6) 单个StoreFile大小超过一定阈值后,触发Split操作,把当前Region Split成2个新的Region。父Region会下线,新Split出的2个子Region会被HMaster分配到相应的RegionServer上,使得原先1个Region的压力得以分流到2个Region上。
可以看出Hbase只有增添数据,所有的更新和删除操作都是在后续的Compact历程中举行的,使得用户的写操作只要进入内存就可以立刻返回,实现了Hbase I/O的高机能。
下面我们从Hbase源码里探究客户端put数据的流程。
1)客户端
put在客户端的操作主要分为三个步骤,下面分别从三个步骤展开解释:
(一)、客户端缓存用户提交的put请求
get/delete/put/append/increment等等等等客户可用的函数都在客户端的HTable.java文件中。
在HTable.java文件中有如下的两个变量:
private RpcRetryingCallerFactory rpcCallerFactory;
private RpcControllerFactory rpcControllerFactory;
protected AsyncProcess multiAp;
如上的几个变量分别定义了rpc调用的工厂和一个异步处理的进程
客户端的put请求调用getBufferedMutator().mutate(put),进入mutate这个函数可以看到它会把用户提交的此次put操作放入到列表writeAsyncBuffer中,当buffer中的数据超过规定值时,由后台进程进行提交。
(二)、将writeBuffer中的put操作根据region的不同进行分组,分别放入不同的Map集合
进程提交由函数backgroudFlushCommits完成,提交动作包含同步提交和异步提交两种情况,由传入的参数boolean控制。进入上述函数分析。
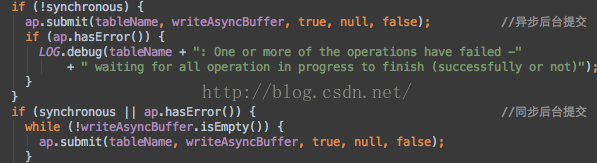
可见当传入backgroudFlushCommits的参数为false时执行的是异步提交,参数为true时执行的是同步提交。
与此同时,可以发现无论异步提交还是同步提交,实际的提交动作是由AsyncProcess ap执行的,调用的语句如下:
ap.submit(tableName,writeAsyncBuffer,true,null,false)
需要注意的是多数情况下执行的是异步提交,只有在异步提交出错的情况下执行同步提交。
进入submit函数,可以看到它循环遍历参数writeAsyncBuffer中的每一行,通过connection.locateRegion函数找到其在集群的位置loc,将该位置与操作action一起绑定在变量actionByServer中。
这里的region定位是由ClusterConnection类型的变量connection完成的,进入其locateRegion方法可以看出,如果客户端有缓存,则直接从缓存读取,否则从META表中读出了region所处的位置,并缓存此次的读取结果。返回的结果是RegionLocations类型的变量。
actionByServer是一个Map<ServerName,MulteAction<Row>>类型的变量,从该变量的类型定义可以看出,其将用户的一批写请求中,写入regionserver地址相同的动作归类到一起。
(三)、提交服务端RegionServer处理,在回调函数中与服务端交互。
最后调用sumitMultiActions函数将所有请求提交给服务端,它接受了上面的actionByServer作为参数,内部实例化一个AsyncRequestFutureImpl类执行异步的提交动作。
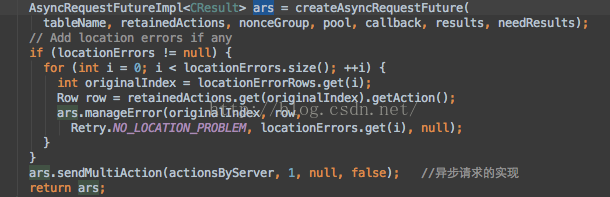
从sendMultiAction函数中一步步向里查看代码,其将用户的action请求通过getNewMultiActionRunnable、SingleServerRequestRunnable层层调用最终落到了Hbase的RPC框架中,每个用户请求包装成包装MultiServerCallable对象,其是一个Runnable对象,在该对象中用户请求与服务端建立起RPC联系。所有的runnable对象最终交到AsyncProcess对象的内部线程池中处理执行。
2)服务端
客户端MultiServerCallable的call方法中调用了服务端的multi函数执行提交动作,进入服务端。
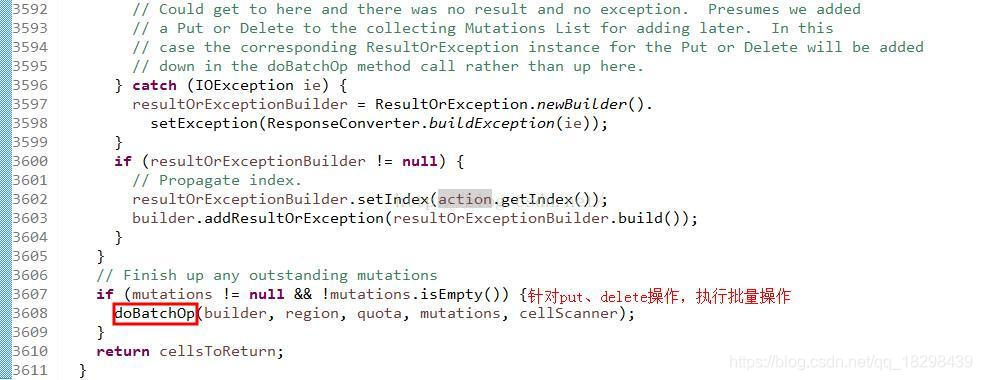
multi方法内部会根据请求是否是原子请求,执行不同的操作语句,这里我们以非原子性提交为例,其执行了doNonAtomicRegionMutation()函数,这个函数中先进行一些rpc请求的编码,将编码后的action相关信息组织到一个List<ClientProtos.Action>类型的变量mutations中,这里的编码采用的proto buffer的编码方案,然后调用doBatchOp()语句,其接受了mutations作为参数。
在doBatchOp函数中,可以看到其最终调用的batchMutate执行的批量操作,这里操作的结果会返回到OperationStatus类型的变量codes[]中,包括了以下几种状态:BAD_FAMILY;SANITY_CHECK_FAILURE;SUCCESS等状态。 这些状态记录了每个action的执行结果,包括成功啦、失败啦等等。
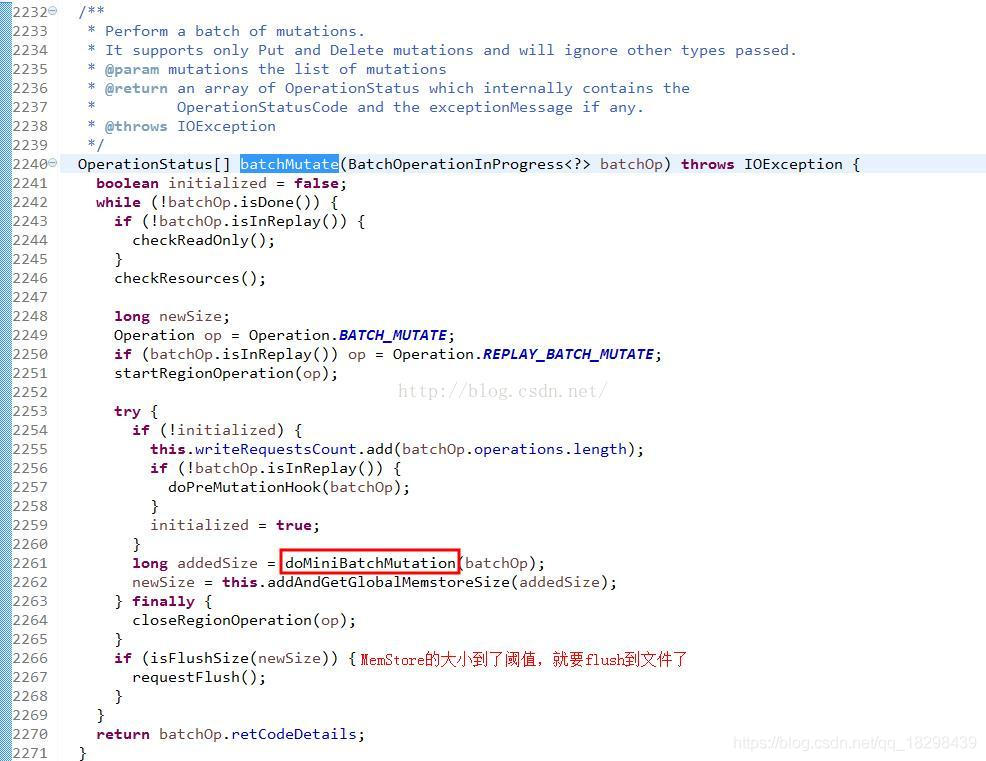
就一步地这些请求被包装成一个MutationBatch类型的对象传入batchMutate,batchMutatue首先判断一下资源的状态,然后调用doMiniBatchMutation()执行最终的put操作,该操作返回的是写入数据的大小addedSize,根据addedSize计算此时memstore的size以决定是否flush,如果达到了flush的要求,执行requestFlush()。doMiniBatchMutation接受了MutationBatch类型的对象继续作为其参数。关键代码如下所示:
while (!batchOp.isDone()) { //操作未完成前一直循环
if (!batchOp.isInReplay()) {
checkReadOnly(); //判断是否是只读状态
}
checkResources(); //检查相关资源
if (!initialized) {
this.writeRequestsCount.add(batchOp.operations.length); //更新写请求计数器
if (!batchOp.isInReplay()) {
doPreMutationHook(batchOp);
}
initialized = true;
}
long addedSize = doMiniBatchMutation(batchOp); //最终的put操作是落在这里的
long newSize = this.addAndGetGlobalMemstoreSize(addedSize); //以原子操作的方式增加Region上的MemStore内存的大小
if (isFlushSize(newSize)) { //判断memstore的大小是否达到阈值,决定是否flush
requestFlush();
}
}服务端的put主要实现在HRegion.java的doMiniBatchMutation(),该函数主要利用了group commit技术,即多次修改一起写。
首先对于所有要修改的行,一次性拿住所有行锁,在2944行实现。
rowLock = getRowLockInternal(mutation.getRow(),shouldBlock) ,注意的是这里的锁是写锁。
put和delete在客户端都是由这个函数实现的,在2960行针对两者的不同第一次出现了不同的处理,分别将put和delete操作归类到putsCfSet和deletesCfSet两个不同的集合中,这两个集合分别代表了put/delete的列族集合,数据类型为Set<byte[]>。
第二步是修正keyvalue的时间戳,把action里面的所有kv时间戳修正为最新的时间。时间戳修正之后,在3009行
lock(this.updatesLock.readLock(),numReadyToWrite) 加入了读锁。
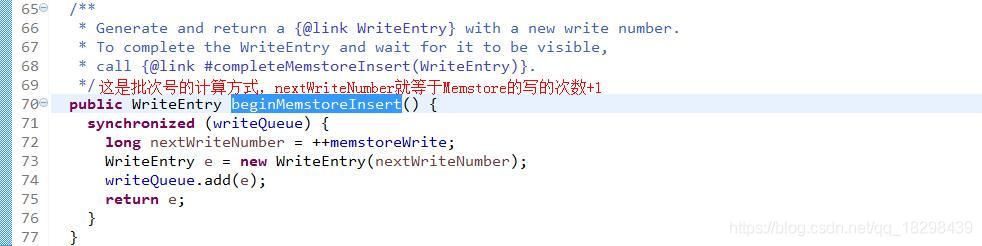
然后获得该批写入memstore数据的批次号mvccNum,mvccNum同时也是此次写事务的版本号,由this.sequenceId加一获得的,然后通过w=mvcc.beginMemstoreInsertWithSeqNum(mvccNum),进入函数beginMemstoreInsertWithSeqNum,可以看见,该函数通过传入的mvccNum new一个新的WriteEntry对象,然后将WriteEntry放入队列writeQueue中,这一步加队列的操作是被锁保护起来的。
writeQueue队列用于保存多个并发写事务的WriteEntry。
然后,就是将batch中的数据写入到各个store的memstore中,并根据batch中的数据构建WAL edit。
构造WAL edit之后,将该条数据对应的table name、region info、cluster id等等包装成一个HLogKey结构的对象,该对象即为walkey,将walKey和WAL edit共同组装成一个entry之后将之append到内存中的ringbuffer数据结构中。
注意的是这次的append操作产生一个HLog范围内的id,记作txid。txid用于标识这次写事务写入的HLog日志。
写入buffer后,即释放所有的行锁,两阶段锁过程结束。然后在3153行 syncOrDefer(txid,durability) ,将这次事务的日志持久化到hfs中,一旦持久化完成便提交此次事务,代码在3170行,其调用了completeMemstoreInsertWithSeqNum(),走进这个函数会发现其在写入mvccnum之后,调用了waitForPreviousTransactoinsComplete()函数,这个函数实际是推进了mvcc memstoreRead,推进的思路如下:
先锁上writeQueue队列,然后一个一个看,找连续的已完成的WriteEntry,最后一个WriteEntry的writeNumber即是最新的点,此时可以赋值给mvcc.memstoreRead,后续读事务一开始就去拿mvcc.memstoreRead,从而能够拿到本次写入的数据。
这里要补充一句,此时写入的数据存储在memstore中,并没有持久化到hdfs中,内存中的key-value是以skip list的数据结构存储的。
总结上面Hbase的写路径可以发现在Hbase的写入过程中应用到了如下的一些技术:
首先,客户端的rpc请求传递到服务端时,函数AsyncRequestFutureImpl()是一个Lazy优化,或者说是一个异步的优化,虽然函数声明了一个对服务端的rpc调用,但是它并没有马上呼叫服务端,而是在需要时才真正呼叫服务端。
第二,数据提交时采用了group commit技术,理解group commit可以用挖煤做比喻,是一铲子一铲子挖比较快,还是一次挖出一车比较省力。
第三,MVCC即多版本并发控制
客户端程序写数据通过HTable和Put进行操作,我们从客户端代码开始分析写数据的流程:
可以看到,客户端写数据最终的调用了HTableInterface的put()方法,因为HTableInterface只是一个接口,所以最终调用的是它的子类HTable的put()方法。进入HTable.put():
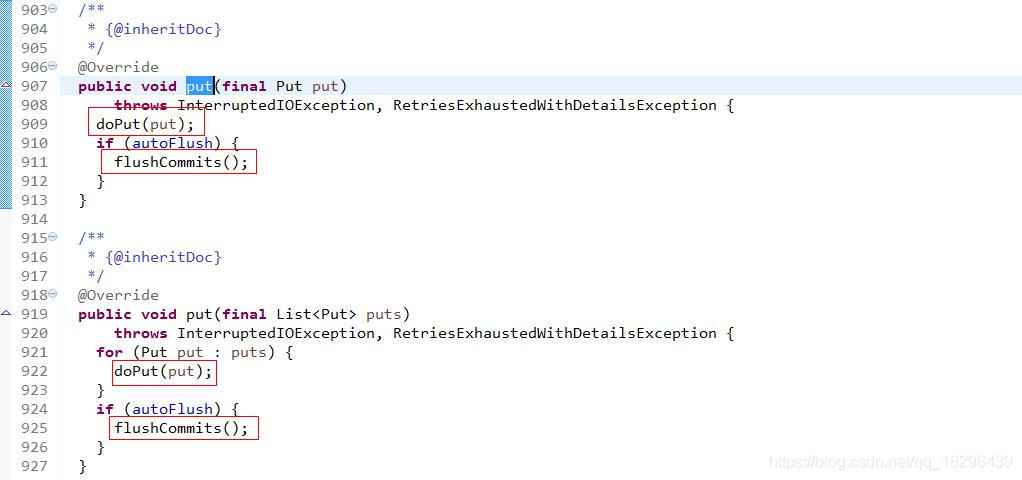
从上面代码可以看出:你既可以一次put一行记录也可以一次put多行记录,两个方法内部都会调用doPut方法,最后再来根据autoFlush(默认为true),即自动提交,判断是否需要flushCommits刷写提交,在autoFlush为false的时候,如果当前容量超过了缓冲区大小(默认值为:2097152=2M),也会调用flushCommits方法。也就是说,在自动提交情况下,你可以手动控制通过一次put多条记录,然后将这些记录flush,以提高写操作吞吐量。
首先看下flushCommits()方法:

只是简单地调用了backgroundFlushCommits()方法,该方法会在后面讲到。
进入doPut()方法:
从上面的代码可以看出,backgroundFlushCommits()这个刷新操作可以是制定异步提交还是同步提交,从doPut方法中来看默认是以异步的方式进行,这里的ap是AsyncProcess类的一个实例,该类使用多线程的来实现异步的请求,也就是说,并非每一次put操作都是直接往Hbase里面写数据的,而是等到缓存区域内的数据多到一定程度(默认设置是2M),再进行一次写操作。当然这次操作在Server端应当还是要排队执行的,具体执行机制这里不作展开。可以确定的是,HConnection在HTable的put操作中,只是起到一个定位RegionServer的作用,在定位到RegionServer之后,操作都是由cilent端通过rpc调用完成的。这个结论在插入/查询/删除中是一致的。
writeAsyncBuffer.add(put)就是向一个异步缓冲区添加该操作,然后当一定条件的时候进行flash,当发生flash操作的时候,才会真正的去执行该操作,这主要是提高系统的吞吐率,接下来我们去看看这个flush的操作内部。

看下waitUntilDone()方法:
 进入waitForMaximumCurrentTasks()方法:
进入waitForMaximumCurrentTasks()方法:

由这个waitForMaximumCurrentTasks()方法,可以清晰了了解到waitUntilDone()方法的操作流程,具体要等待到什么时候呢?等到tasksSent的值减去tasksDone的值等于0,tasksSent表示提交的任务数,tasksDone表示完成的任务数。
现在就可以重新总结一下backgroundFlushCommits()方法,在第965行,submit()方法传入的参数是true,表示需要等待rpc调用结束。第980行,如果有部分数据提交失败,同时没有设置清空失败的数据时,把数据重新添加到writeAsyncBuffer列表中。最后在finally块中,清空当前currentWriteBufferSize的大小,如果有数据没有提交成功,
重新把未提交的数据的大小计算起来添加到currentWriteBufferSize中。
比较doPut()和flushCommits(),如果在doput的过程中,也就是调用htable.put(Put)的时候,如果缓存大小超过了客户端写缓存大小的限制,调用backgroundFlushCommits()方法方法是异步的;而在flushcommit方法中,backgroundFlushCommits()这个方法是同步的。
接下来就是重要的提交过程,submit()方法:
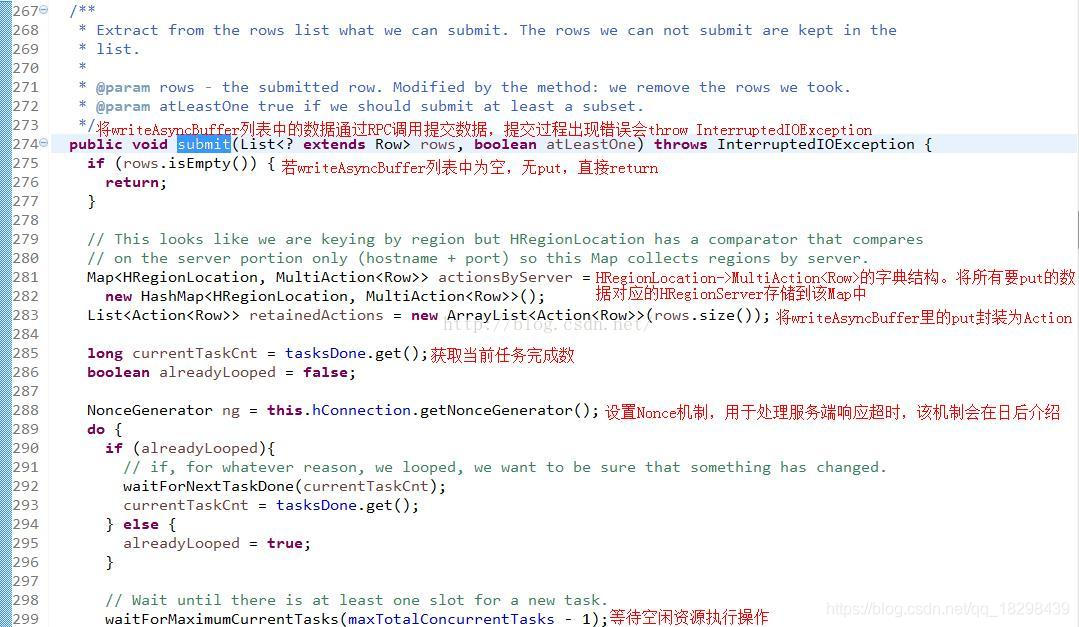

进入sendMultiAction()方法,看它是如何发送put请求的:
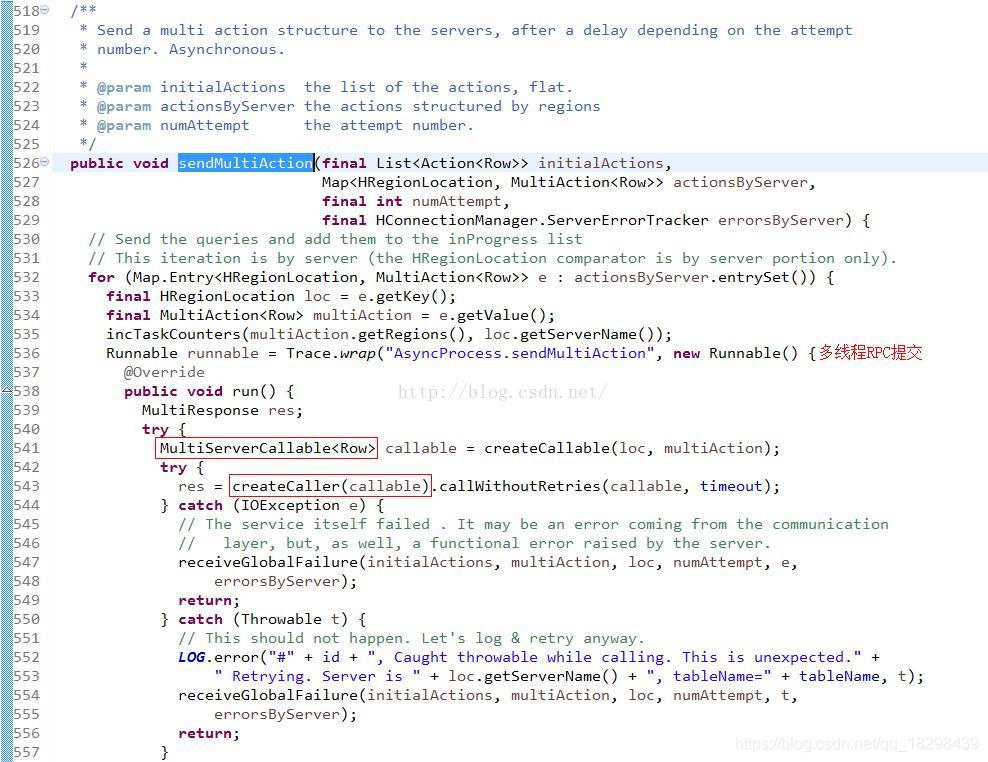

从上面的代码可以看出,每个任务都是通过Hbase的RPC框架与服务器进行通信,并获取返回的结果。其中最重要的两个组件我用红色方框已经圈出,看下他俩的具体实现:
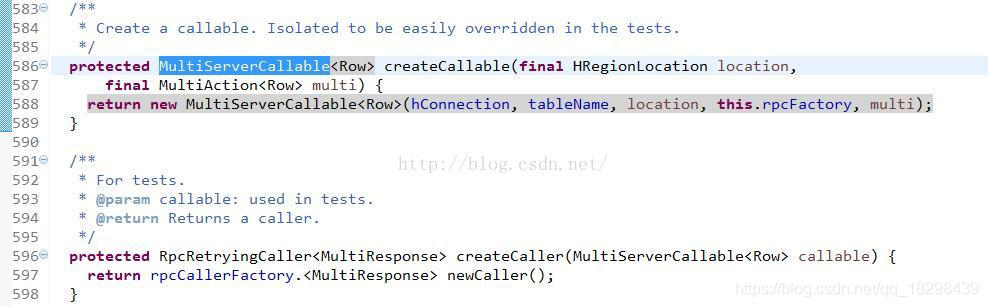
先构造一个MultiServerCallable,然后再通过rpcCallerFactory将其封装为RpcRetryingCaller做最后的call操作。
查看MultiServerCallable:

注释里就说的很明白了,client端通过MultiServerCallable.call()方法调用res的rpc的multi()方法,来实现put提交请求。可以想象,根据讲过的《Hadoop RPC机制-原理篇》,HRegionServer端必定也有一个multi()方法。
总结put操作:
(1)把put操作添加到writeAsyncBuffer队列里面,符合条件(自动flush或者超过了阀值writeBufferSize)就通过AsyncProcess异步批量提交。
(2)在提交之前,我们要根据每个rowkey找到它们归属的region server,这个定位的过程是通过HConnection的locateRegion方法获得的,然后再把这些rowkey按照HRegionLocation分组。在获得具体region位置的时候,会对最近使用的region server做缓存,如果缓存中保存了相应的region server信息,就直接使用这个region信息,连接这个region server,否则会对master进行一次rpc操作,获得region server信息,客户端的操作put、get、delete等操作每次都是封装在一个Action对象中进行提交操作的,都是一系列的的action一起提交,这就是MultiAction。
(3)通过多线程,一个HRegionLocation构造MultiServerCallable<Row>,然后通过rpcCallerFactory.<MultiResponse> newCaller()执行调用,忽略掉失败重新提交和错误处理,客户端的提交操作到此结束。
put操作的流程,最后client端是通过MultiServerCallable.call()调用multi()方法来进行rpc请求的。追踪multi()方法,进入ClientProtos.ClientService.BlockingInterface接口的multi()抽象方法,再次追踪该方法,进入实现该方法的HRegionServer实例,查看multi()方法的具体实现:
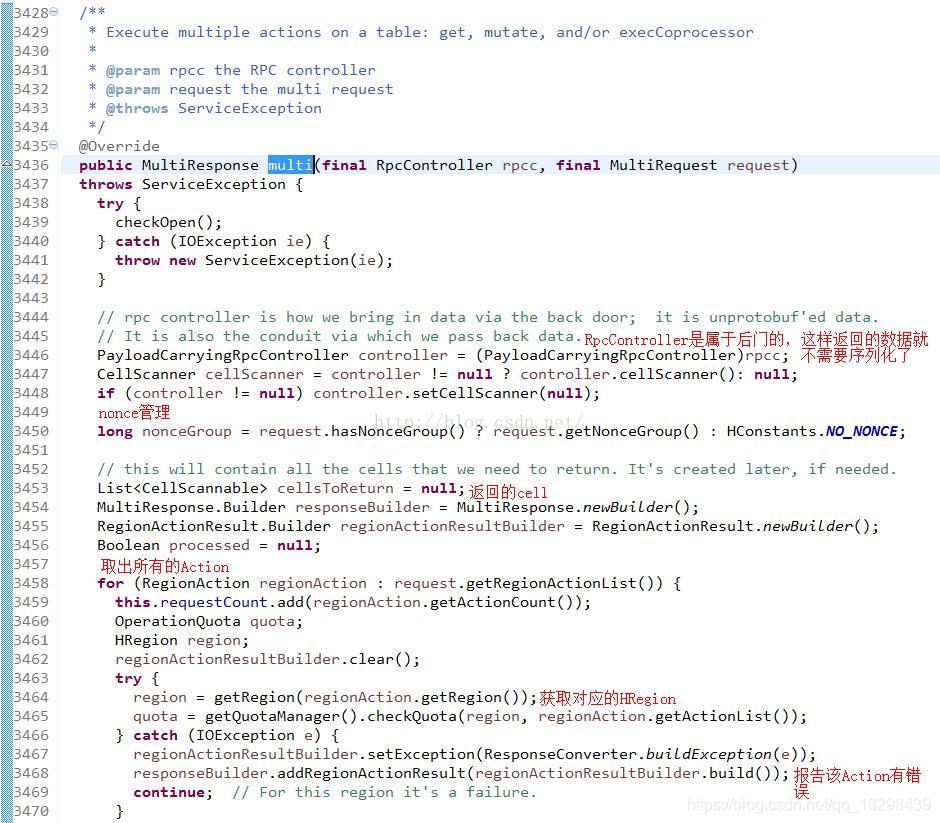

这个方法里面还包括了PayloadCarryingRpcController和CellScanner可以看得出来它不只是被Put来用的,但是这些我们不管我们只看Put如何处理就行了。在该方法的3464行调用了getRegion()方法,来获取对应的HRegion,简单看一下:
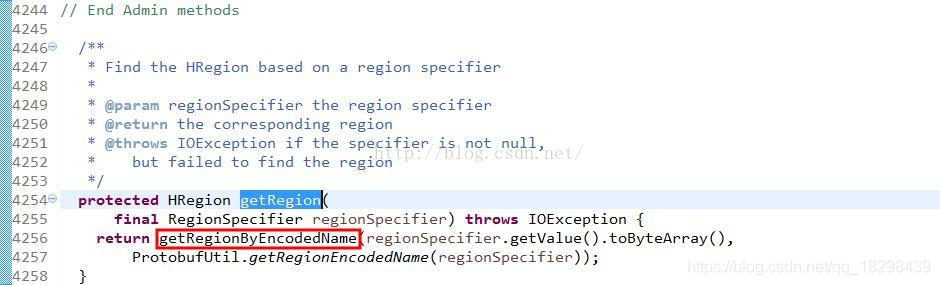
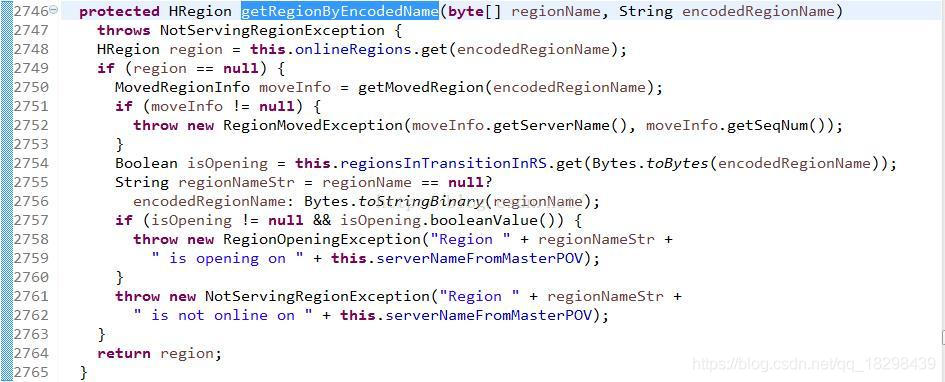
分析下getRegionByEncodedName()方法流程,看它如何从当前regionserver中的onlnieRegions中得到请求的region.:
1.从onlineRegions中取出HRegion实例
2.如果onlineRegions列表中不包含此region,从movedRegions列表中拿到region,region的moved超时是2分钟,如果movedRegions列表中能拿到此region,同时move时间超时,并从movedRegions列表中移出引region返回null,
否则返回正在moved的region,如果movedRegions中返回的region不为null,throwRegionMovedException
3.从regionsInTransitionInRS中获取此region,如果能拿到,同时拿到的值为true,表示region还在做opening操作,Throw RegionOpeningException
4.如果以上得到的值都为null,表示此server中没有此region,throw NotServingRegionException此时基本上只有一个可能,region在做split.或者move到其它server(刚完成move,client请求时不在此server)
总结下multi()方法的操作:
1、取出来所有的action(Put),这里主要是put,因为我们调用客户端就是这么调用的,其实别的类型也可以支持,获取他们对应的region。
2、根据action的原子性来判断走哪个方法,原子性操作走mutateRows,非原子性操作走doNonAtomicRegionMutation方法,我查了一下这个Atomic到底是怎么回事,我搜索了一下代码,发现在调用HTable的mutateRow方法的时候,它设置了Atomic为true,这个是应该是支持一行数据的原子性的,有这个需求的童鞋可以尝试用这个方法,也是可以提交多个,包括Put、Delete操作。
接下来看doNonAtomicRegionMutation()方法,用于处理非原子性的put/delete/get操作,这是我们常用的方式:
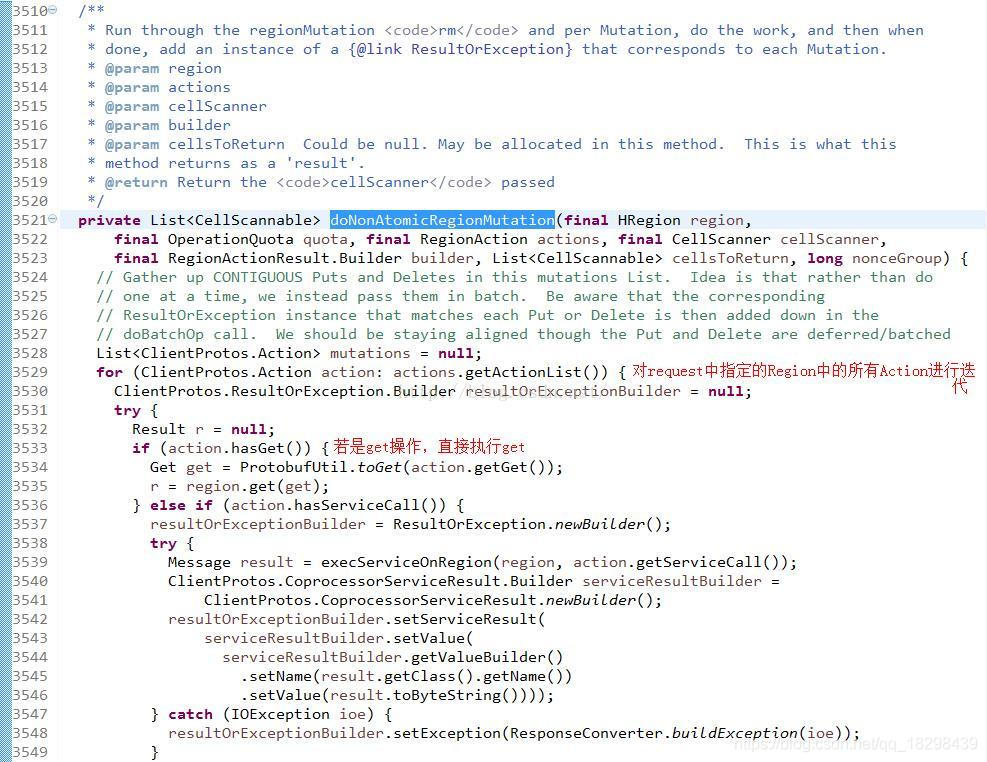

这里面代码很多,也适配了很多种类型,是个大而全的方法,但是我们这里用到的只是把Put、Delete等的类型转换添加到mutations的列表里,然后走最后的圈出的doBatchOp()这个批量操作,然而这个代码也比较长,简单说一下该方法的思路:
1、还是得把Put、Delete给转换类型,这里的批量操作只支持全是Delete或者全是Put。
2、用HRegion.batchMutate方法来执行操作,返回OperationStatus数组,记录每个action的状态,是成功,还是失败,或者是别的状态。在batchMutate()里面首先就是检查是否是只读状态,然后检查是否是Meta Region的,是否执行MemStore检查了。
终于到了最终的Big Boss类,这个类很长很长很长。。。。。。
1、重要的成员变量
![]()
2、检查Put和Delete里面的列族是否和Region持有的列族的定义相同,有时候我们在Delete的时候是不填列族的,这里它给这个缺的列族来一个KeyValue.Type.DeleteFamily,删除列族的类型。
3、给Row加锁,先计算hash值做key,如果该key没上过锁,就上一把锁,然后计算出来要写的action有多少个,记录到numReadyToWrite。
4、更新时间戳,把该action里面的所有的kv的时间戳更新为最新的时间戳,它这里也会把之前的没运行的也一起更新。
5、给该region加锁,这个时间点之后,就不允许读了,等待时间需要根据numReadyToWrite的数量来计算。
![]()

6、上锁之后,就是Put、Delete等的重点。给这些写入memstore的数据创建一个批次号。
![]()
7、把kv们写入到memstore当中,然后计算出来一个添加数据之后的新的MemStore的大小addedSize。

MemStore里面有两个kv的集合,调用applyFamilyMapToMemstore()把kv添加到集合里面去。
8、把kv添加到日志当中,标志状态为成功,如果是用户设置了不写入日志的,它就不写入日志了。
9、先异步添加日志,这里为什么是异步的,因为之前给上锁了,暂时不能读了。
10、释放之前创建的锁。

11、同步日志。
12、结束该批次的操作。
Final、同步日志没成功的,最后根据批次回滚MemStore中的操作。
读操作流程
(1) Client访问Zookeeper,查找-ROOT-表,获取.META.表信息。
(2) 从.META.表查找,获取存放目标数据的Region信息,从而找到对应的RegionServer。
(3) 通过RegionServer获取需要查找的数据。
(4) Regionserver的内存分为MemStore和BlockCache两部分,MemStore主要用于写数据,BlockCache主要用于读数据。读请求先到MemStore中查数据,查不到就到BlockCache中查,再查不到就会到StoreFile上读,并把读的结果放入BlockCache。
寻址过程:client-->Zookeeper-->-ROOT-表-->.META.表-->RegionServer-->Region-->client