关于如何判断一个文件的类型,在如何判断一个文件的类型_jimmyleeee的博客-CSDN博客已经介绍了,但是在实际运用于真正的文件上传时,还是有些注意事项需要注意的。
在进入主题之前,首先需要简单介绍一下MultipartFile这个类,通过getOriginalFilename()获取文件的名字,但是这个名字只是上传文件的名字,通过这个名字是无法访问到这个文件的。以下是测试时的debug信息:
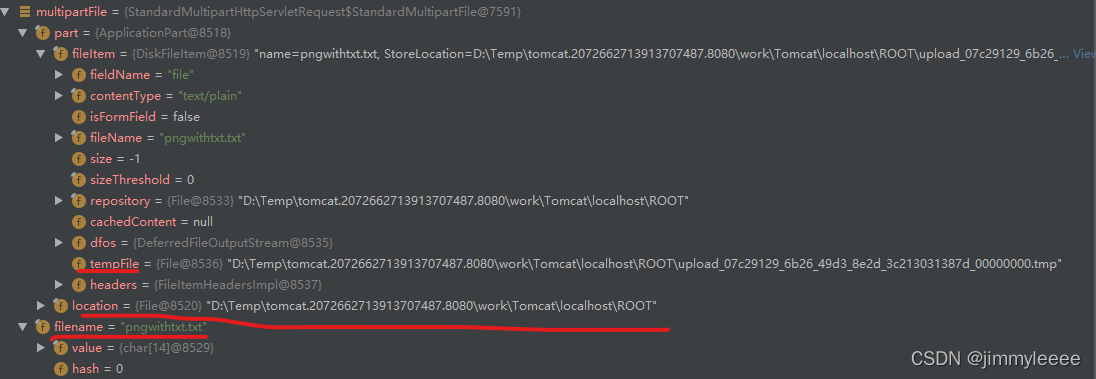
可以看到 MultipartFile类中,有filename,有filelocation,甚至还有临时文件的绝对路劲和名字,但是,却没有接口可以获取这些信息。也就是说,通过类MultipartFile只能获得文件名和文件流。
再说,使用Files.probeContentType检测上传的MultipartFile时,为什么可以正常工作。在Files.probeContentType中设置一个断点,可以发现进入函数之后,会直接调转到1624行,调用
FileTypeDetectors.defaultFileTypeDetector的probeContentType
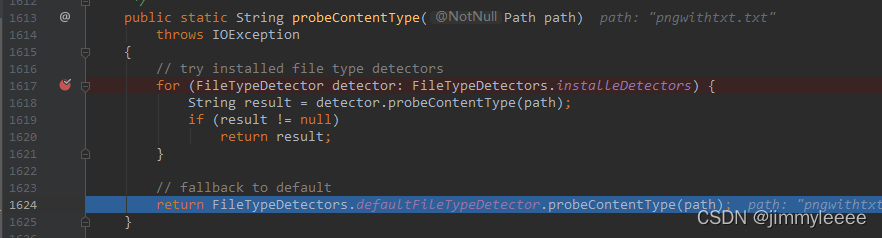
通过进一步定义跟踪,默认的defaultFileTypeDetector是RegistryFileTypeDetector,根据基类AbstractFileTypeDetector中probeContentType的实现如下:
public final String probeContentType(Path var1) throws IOException {
if (var1 == null) {
throw new NullPointerException("'file' is null");
} else {
String var2 = this.implProbeContentType(var1);
if (var2 == null) {
Path var3 = var1.getFileName();
if (var3 != null) {
FileNameMap var4 = URLConnection.getFileNameMap();
var2 = var4.getContentTypeFor(var3.toString());
}
}
return var2 == null ? null : parse(var2);
}
}其中,主要是implProbeContentType中实现对内容类型的分析。回到RegistryFileTypeDetector的implProbeContentType函数:
public String implProbeContentType(Path var1) throws IOException {
if (!(var1 instanceof Path)) {
return null;
} else {
Path var2 = var1.getFileName();
if (var2 == null) {
return null;
} else {
String var3 = var2.toString();
int var4 = var3.lastIndexOf(46);
if (var4 >= 0 && var4 != var3.length() - 1) {
String var5 = var3.substring(var4);
NativeBuffer var6 = null;
NativeBuffer var7 = null;
Object var9;
try {
var6 = WindowsNativeDispatcher.asNativeBuffer(var5);
var7 = WindowsNativeDispatcher.asNativeBuffer("Content Type");
String var8 = queryStringValue(var6.address(), var7.address());
return var8;
} catch (WindowsException var13) {
var13.rethrowAsIOException(var1.toString());
var9 = null;
} finally {
var7.release();
var6.release();
}
return (String)var9;
} else {
return null;
}
}
}
}在这里可以看到文件名var2之后,就在文件名上进行进一步分析和判断,没有读取文件。所以,默认的detector,即使没有实际的文件,只要根据文件名,就可以判断一个文件的内容类型,虽然,有时不准确,例如,将一个png文件改成txt的扩展名,分析出来的结果就是:text/plain。根据类的实现,也可以通过加载自己实现的类型检测类,然后,再调用Files.probeContentType就可以使用自己的类型探测类了。
而使用Tika调用String detect(File file)接口时,如果文件不存在,就会跑出IO异常:
Tika defaultTika = new Tika();
String fileType;
try
{
final File file = new File(fileName);
fileType = defaultTika.detect(file);
}
catch (IOException ioEx)
{
fileType = "Unknown";
}因此,在处理上传的文件时,使用MultipartFile.getOriginalFilename获取的文件名生成一个File对象来获取文件内容类型,会出IOException 异常。而且将file转成File对象时,还可能会产生临时文件。
不过,还好的是Tika还提供了一个针对stream流的接口:String detect(String name)
Tika defaultTika = new Tika();
MultipartFile multipartFile = multipartHttpServletRequest.getFile(key);
String fileType;
try
{
InputStream stream = multipartFile.getInputStream();
fileType = defaultTika.detect(stream);
}
catch (IOException ioEx)
{
fileType = "Unknown";
}Tika还提供了Parser,可以通过Parser对InputStream分析得到文件的内容类型与Tika.detect(InputStream)的结果是一样的,示例代码如下:
public static String getMimeTypeByParser(InputStream stream) {
AutoDetectParser parser = new AutoDetectParser();
Metadata metadata = new Metadata();
BodyContentHandler handler = new BodyContentHandler();
try {
parser.parse(stream, handler, metadata);
} catch (IOException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (TikaException e) {
e.printStackTrace();
}
return metadata.get(HttpHeaders.CONTENT_TYPE);
}