混淆矩阵与PR曲线、ROC曲线的理解与使用
1.混淆矩阵
对于分类器而言,一个比较好的评估指标是混淆矩阵。下面通过一个表格具体展示在二分类器中的应用。
| Neg(非A) | Pos(A) | |
|---|---|---|
| Neg(非A样本) | 90(TN) | 10(FP) |
| Pos(A样本) | 30(FN) | 70(TP) |
其中Neg表示非A类,pos表示A类。从表格中可以得知,此分类器更能有效地识别非A样本,而对于A样本的识别能力不足。
据此我们还可以引出如下概念:
Precision和Recall都是针对某个类而言的,比如正类别的Recall,负类别的Recall等。如果你是10分类,那么可以有1这个类别的Precision,2这个类别的Precision,3这个类别的Recall等。
准确率
p
r
e
c
e
s
i
o
n
=
T
P
T
P
+
F
P
.
\mathcal{precesion}=\frac{TP}{TP+FP}.precesion=TP+FPTP.表示你预测为正的样本中有多少预测对了。
从这个公式可看出要想使准确率提高,得把FP尽可能的降低,就是降低对非A类的错误识别率,也就是说提高对反例的识别率。
召回率
r
e
c
a
l
l
=
T
P
T
P
+
F
N
.
\mathcal{recall}=\frac{TP}{TP+FN}.recall=TP+FNTP.表示真实标签为正的样本有多少被你预测对了。
反之,从这个公式可看出,要想使用召回率提高,得把FN尽可能的降低,就是降低对A类的错误识别率,也就是说尽可能的提高正例的识别率。
F1值
F
1
=
T
P
T
P
+
F
N
+
F
P
2
.
\mathcal{F1}=\frac{TP}{TP+\frac{FN+FP}{2}}.F1=TP+2FN+FPTP.
F1 值是准确率和召回率的调和平均。普通的平均值平等地看待所有的值,而调和平均会给小的值更大的权重。所以,要想分类器得到一个高的 F1 值,需要召回率和准确率同时高。
F1 支持那些有着相近准确率和召回率的分类器。这不会总是你想要的。有的场景你会绝大程度地关心准确率,而另外一些场景你会更关心召回率。
举例子,如果你训练一个分类器去检测视频是否适合儿童观看,你会倾向选择那种即便拒绝了很多好视频、但保证所保留的视频都是好(高准确率)的分类器,而不是那种高召回率、但让坏视频混入的分类器(这种情况下你或许想增加人工去检测分类器选择出来的视频)。
另一方面,加入你训练一个分类器去检测监控图像当中的窃贼,有着30% 准确率、99% 召回率的分类器或许是合适的(当然,警卫会得到一些错误的报警,但是几乎所有的窃贼都会被抓到)。
不幸的是,你不能同时拥有两者。增加准确率会降低召回率,因为在提高准确率的过程中势必会增大对反例的识别能力,会把很多似是而非的正例也识别为反例,这样做必然导致正例的识别率降低,所以召回率也就随之降低了;反之亦然。这叫做准确率与召回率之间的折衷。
因此针对不同类型的问题,你要有所取舍,在实际编码过程中,可以通过设定一个分类相似程度的得分阈值来进行准确率和召回率的调整。
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import cross_val_predict
threshold = 0 #得分阈值
#使用 cross_val_predict() 得到每一个样例的分数值,根据这个分数值和阈值进行对比,便可得出每个样例的分类情况,从而算出其准确率和召回率
#其中method会根据使用的分类算法不同发生变化,并不是所有的算法得出的都是分数,要根据实际情况进行调整
#比如随机森林算法的method就是一个概率函数predict_proba,返回的结果是一个正反例的概率值
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv= 3 , method= "decision_function" )
#得出分数值后,对于任何可能的阈值,使用 precision_recall_curve() ,可以计算出准确率和召回率
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)然后通过matplot画出最终的阈值与曲线的关系图
from matplotlib import pyplot as plt
def plot_precision_recall_vs_threshold (precisions, recalls, thresholds) :
#precision_recall_curve函数的源码中,precision : array, shape = [n_thresholds + 1],the last element is 1
#之所以要通过precisions[: -1 ]使准确率数组中的最后一个值删掉,是因为,随着阈值的不断提高,对反例的识别率不断提高,最终的准确率趋近于1
#但此时的阈值可能太大导致阈值数组的范围太大不好表示,所以干脆就省略了这个阈值,直接令准确率数组的最后一个值等于1
plt.plot(thresholds, precisions[: -1 ], "b--" , label= "Precision" )
#recalls[: -1 ]意义同上
plt.plot(thresholds, recalls[: -1 ], "g-" , label= "Recall" )
plt.xlabel( "Threshold" )
plt.legend(loc= "upper left" )
plt.ylim([ 0 , 1 ])2.PR曲线
最后我们也可以画出准确率对召回率的曲线(PR曲线),更能准确直观地反映出在召回率多少时准确率急剧下降。
from matplotlib import pyplot as plt
def plot_precision_vs_recall (precisions, recalls) :
plt.plot(recalls, precisions, "b--" , label= "Precision vs Recall" )
plt.legend(loc= "upper left" )
plt.ylim([ 0 , 1 ])如下图所示,该曲线在80%的召回率时其准确率急剧下降,所以我们应该根据实际情况作出抉择。最理想的结果是该PR曲线越靠近右上方越好。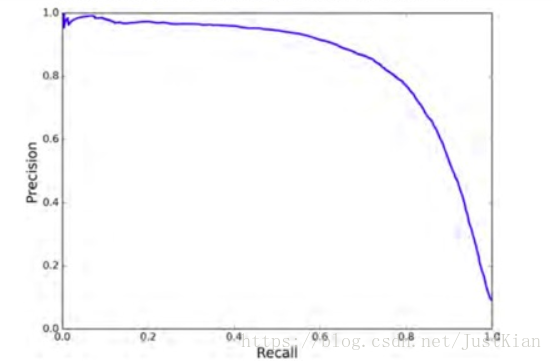
3.ROC曲线
受试者工作特征(ROC)曲线是另一个二分类器常用的工具,他其实就是召回率(也叫TPR、Recall)对假正例率FPR的关系曲线,FPR 是反例被错误分成正例的比率。可以通过roc_curve()函数进行计算。
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
#绘制图像
def plot_roc_curve (fpr, tpr, label=None) :
plt.plot(fpr, tpr, linewidth= 2 , label=label)
plt.plot([ 0 , 1 ], [ 0 , 1 ], 'k--' )
plt.axis([ 0 , 1 , 0 , 1 ])
plt.xlabel( 'False Positive Rate' )
plt.ylabel( 'True Positive Rate' )
plot_roc_curve(fpr, tpr)如下图所示,召回率(TPR)越高,分类器就会产生越多的假正例(FPR越高,即分类器的准确率降低),这也存在一个折衷的问题。最理想的情况是ROC曲线越靠近左上方越好,其ROC AUG即ROC曲线下面积越大。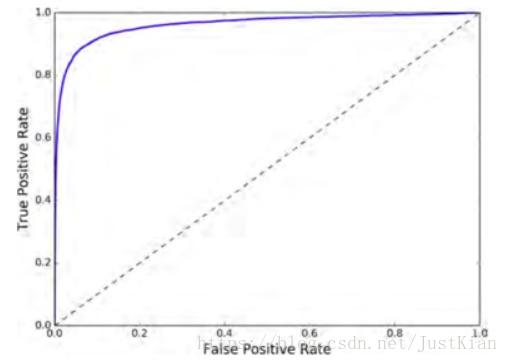
4.总结
在平时的二分类评价处理过程中,通常是通过PR曲线与ROC曲线来进行指标评价。
ROC 曲线跟准确率/召回率曲线(或者叫 PR)很类似,我们有必要对其做一个归纳总结。
当正例很少或者当你关注假正例多于假反例的时候,优先使用 PR 曲线,其他情况使用 ROC 曲线。