大家好,今天给大家分享一下个知识点:
二叉查找树
1.背景介绍
二叉树 (binary tree)
二叉树就是一个节点分出两个节点,称其为左右子节点;每个子节点又可以分出两个子节点,这样递归分叉,其形状很像一颗倒着的树。二叉树限制了每个节点最多有两个子节点,没有子节点的节点称为叶子。

平衡二叉树
它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等。
2.知识剖析
二叉树遍历
遍历是二叉树上最重要的运算之一,是二叉树上进行其它运算之基础。
遍历方案
从二叉树的递归定义可知,一棵非空的二叉树由根结点及左、右子树这三个基本部分组成。因此,在任一给定结点上,可以按某种次序执行三个操作:
⑴访问结点本身(N),
⑵遍历该结点的左子树(L),
⑶遍历该结点的右子树(R)。
遍历顺序
①前序遍历:NLR,访问根结点的操作发生在遍历其左右子树之前。
② 中序遍历:LNR,访问根结点的操作发生在遍历其左右子树之中(间)。
③ 后序遍历:LRN,访问根结点的操作发生在遍历其左右子树之后。
二叉查找树 BST (Binary Search Tree)
之所以称为二叉搜索树,是因为这种二叉树能大幅度提高搜索效率。
二叉查找树(BST)具备什么特性呢?
1.左子树上所有结点的值均小于它的根结点的值。
2.右子树上所有结点的值均大于它的根结点的值。
3.左、右子树也分别为二叉排序树。
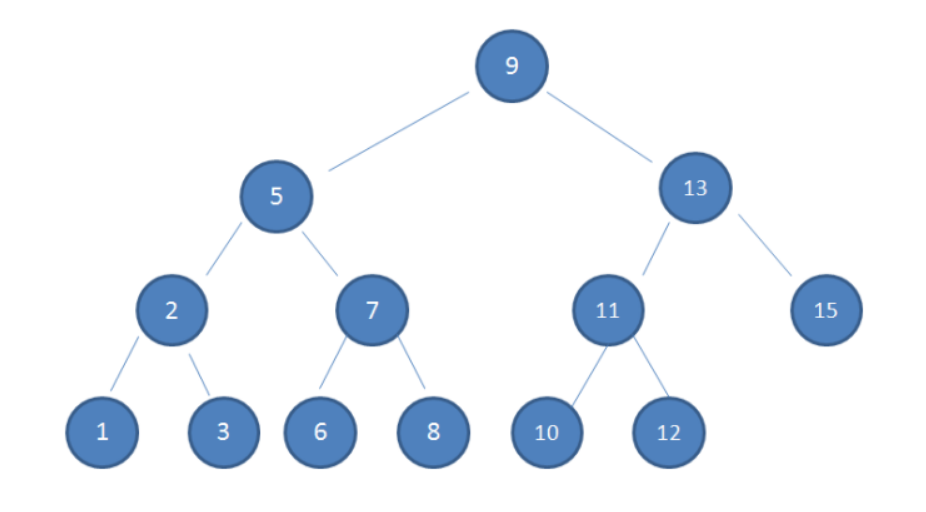
如果按照中序遍历,其遍历结果是一个有序序列。因此,二叉搜索树又称为二叉排序树。

如图,A按照中序遍历(LNR)为2、3、6、7、8、9,属于有序序列,所以是二叉查找树;
图B不符合,不是二叉查找树。
编码实战用:
3.常见问题
顺序插入数据到二叉树是会不平衡
4.解决方案
采用平衡二叉树,如红黑树
红黑树(Red Black Tree)
时间复杂度:可以在O(log n)时间内做查找,插入和删除,这里的n 是树中元素的数目。
红黑树是平衡二叉树的一种实现,何谓平衡? 何谓不平衡?
现有如下二叉查找树
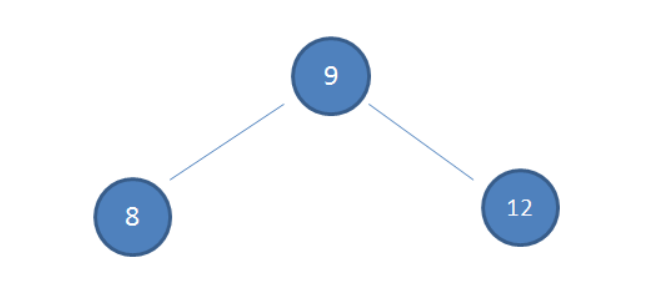
要求在该树中依次插入7 、6、5、4、3,依照二叉查找树的特性,结果如下:
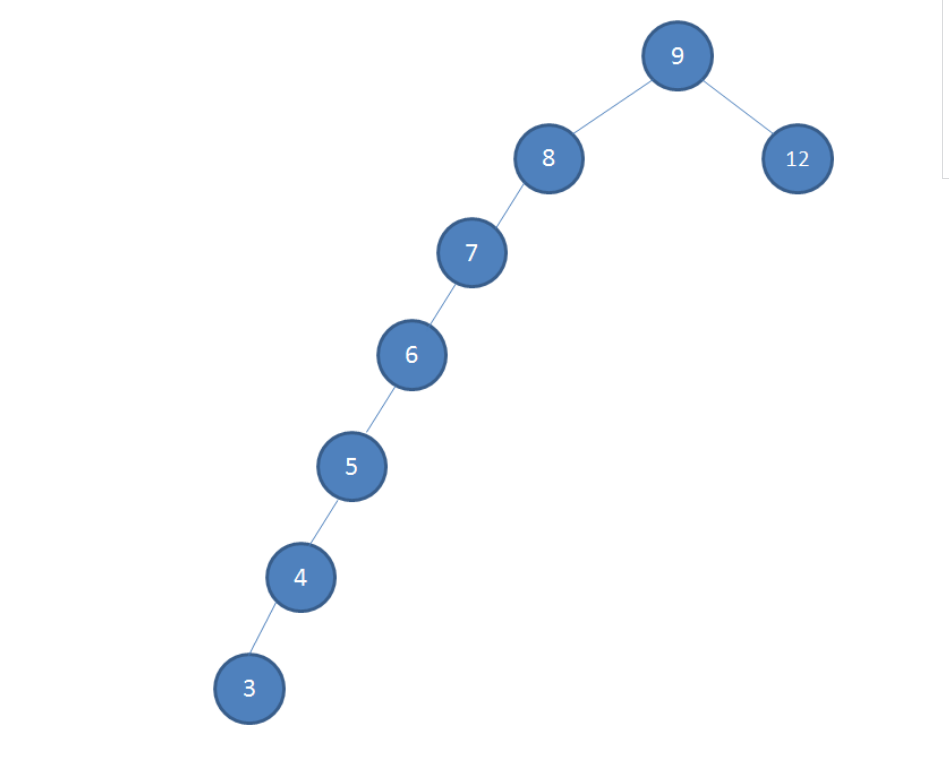
这样的形态虽然也符合二叉查找树的特性,但是查找性能大打折扣,几乎变成了线性。为了解决二叉查找树多次插入新节点导致的不平衡, 平衡二叉树应运而生,平衡二叉树的实现包括很多种,而红黑树即是较常用的一种。
红黑树是一种自平衡的二叉树,除了符合二叉树的基本特性之外,还具有下列附加属性:
1.节点是红色或黑色。
2.根节点是黑色。
3.每个叶子节点都是黑色的空节点(NIL节点)。
4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
5.从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
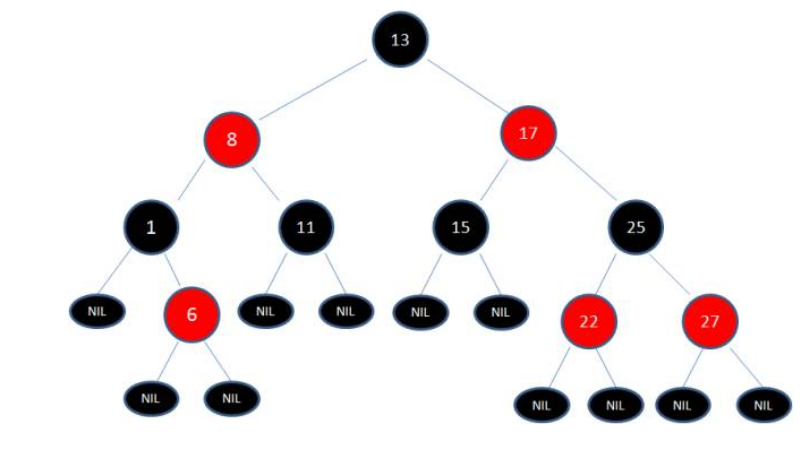
正是因为上述规则的限制,才保证了红黑树的自平衡,红黑树从根到叶子的最长路径不会超过最短路径的两倍。
当插入或删除节点时,红黑树的规则有可能被打破,这时就要做出一些调整,来维护我们的规则。
红黑树的插入:
1.插入新节点总是红色节点
2.如果插入节点的父节点是黑色, 能维持性质
3.如果插入节点的父节点是红色, 破坏了性质. 故插入算法就是通过重新着色或旋转, 来维持性质
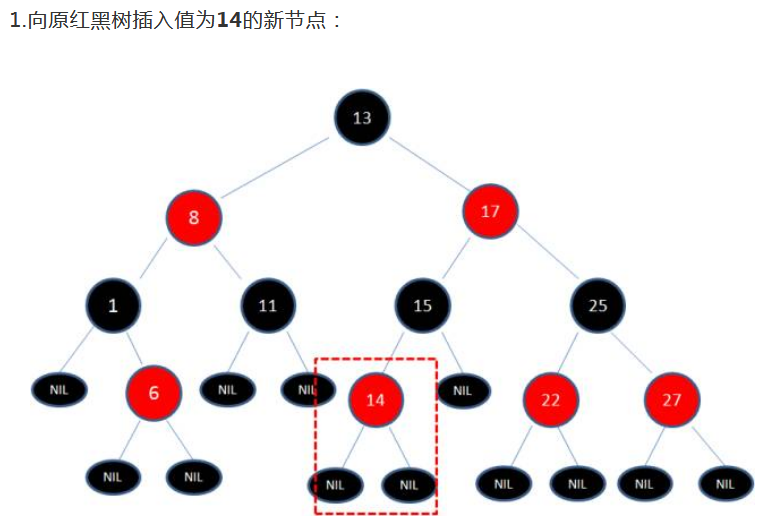
举个栗子,比如我们要往上面的红黑树里插入14,那么它会被插在节点15的左边,这没有任何问题:
但如果你想插入的是21
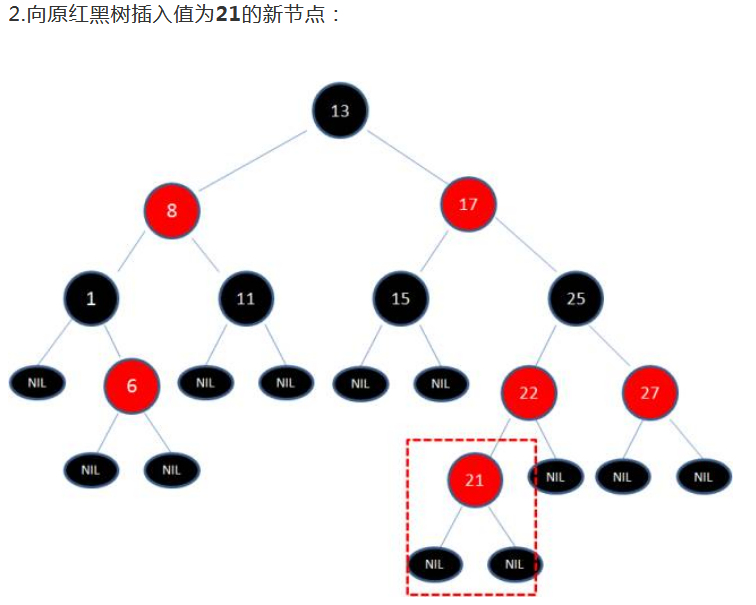
此时,规则就被破环了,需要些调整来维持我们的规则
一般包括如下步骤
变色 -> 左旋转 -> 变色 -> 右旋转 -> 变色。
具体变化过程较为复杂,参考这个链接:https://mp.weixin.qq.com/s/jz1ajDUygZ7sXLQFHyfjWA
红黑树应用实例:
JDK的集合类TreeMap和TreeSet底层就是红黑树实现的
5.编码实战
public class Node {
public int key; // key -- 它是关键字,是用来对二叉查找树的节点进行排序的。
public int value;
public Node leftChild;
public Node rightChild;(略)
6.扩展思考
B-树
B-树(Balance Tree),一个m阶的B树具有如下几个特征:
1.根结点至少有两个子女。
2.每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m
3.每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m
4.所有的叶子结点都位于同一层。
5.每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划。
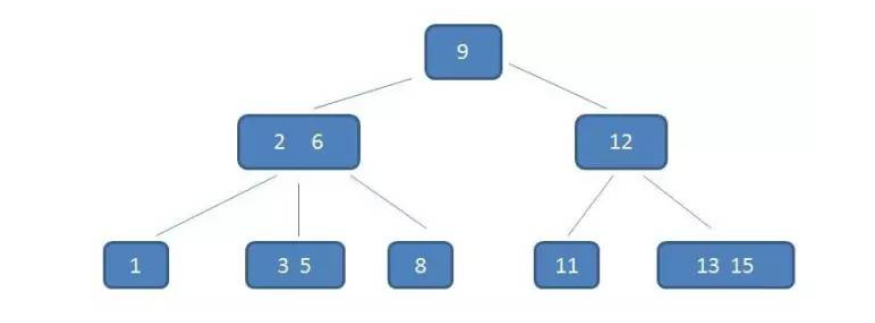
名称中间的横线不是减号,读作B树。
B树常用于数据库的索引

首先,从算法逻辑上来讲,二叉查找树的查找速度和比较次数都是最小的,但是索引上广泛使用的是B树而不是二叉查找树,因为我们不得不考虑一个现实的问题——磁盘IO;
数据库索引是存储在磁盘上的,当数据量比较大的时候,索引的大小可能有几个G甚至更多,当我们用索引查询的时候,不可能把整个索引加载到内存,只能逐一加载每个磁盘页,这里的磁盘页对应这索引树的节点
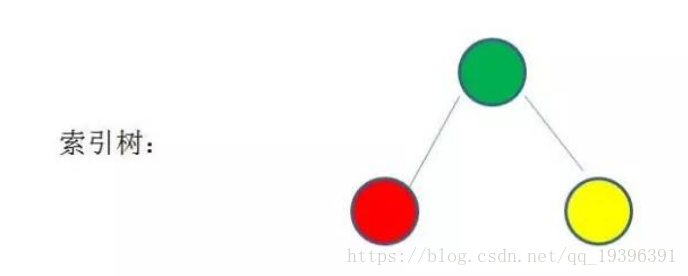
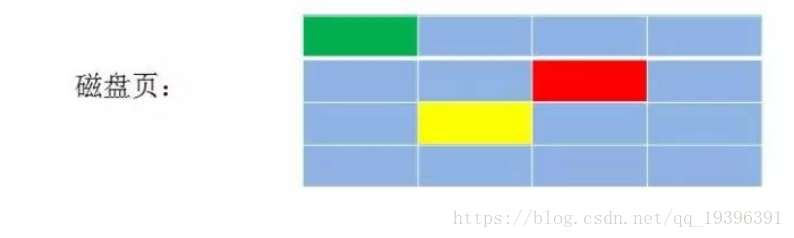
如果我们利用二叉树作为索引结构,假设树的高度是4,查找值为10:
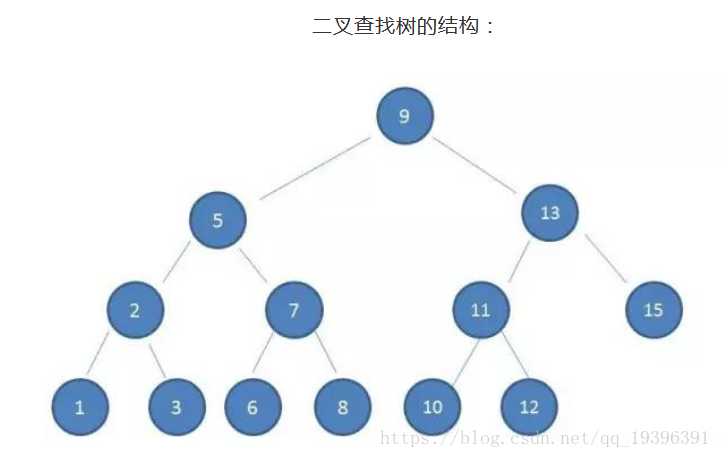
结论:最坏的情况下,磁盘IO次数等于索引树的高度。
为了减少磁盘IO次数,我们需要把原本瘦高的树结构变得矮胖。这就是B树的特征之一。
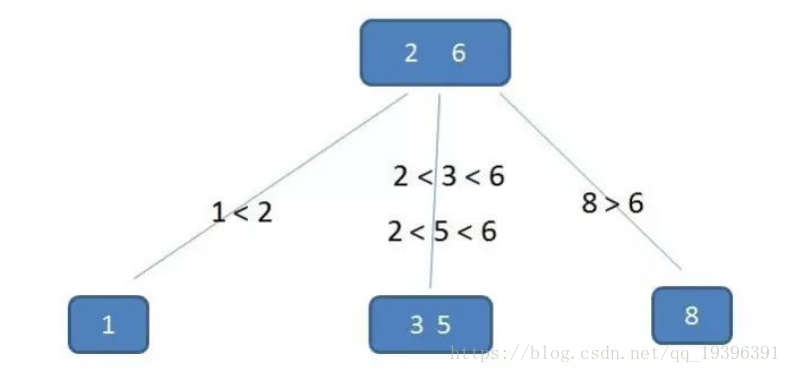
假设我们要查找5
第一次磁盘IO:得到根节点,和9比较;
第二次磁盘IO:得到2、6所在节点,并在内存中定位(和2,6比较)
第三次磁盘IO:得到3、5所在节点,并在内存中定位(和3,5比较);
整个流程可以看出,B树查询的比较次数并不比二叉树少,尤其当单一节点元素数量很多的时候,可以相比与磁盘IO, 内存中的比较耗时几乎可以忽略,所以只要树的高度足够低,就可以提示查找性能。相比之下节点内的元素多一点没关系,仅仅是多了几次内存交互,只要不超过磁盘页大小即可,这就是B树的优势之一
B树插入:(举例)
假设我们要插入4,自顶向下查找4的节点位置,发现4应当插入到节点元素3,5之间。
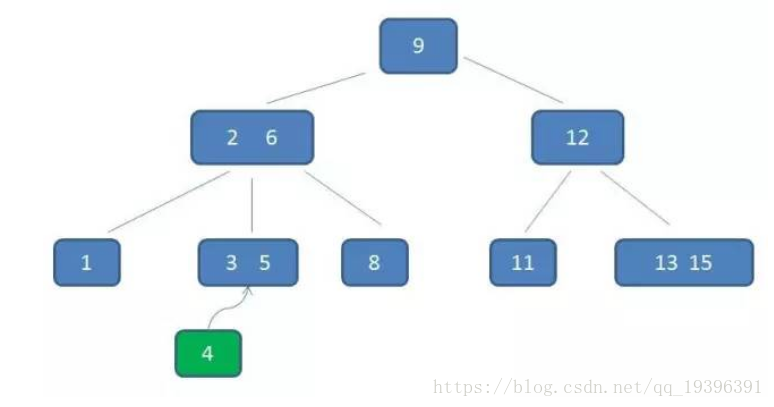
节点3,5已经是两元素节点,无法再增加。父亲节点 2, 6 也是两元素节点,也无法再增加。根节点9是单元素节点,可以升级为两元素节点。于是拆分节点3,5与节点2,6,让根节点9升级为两元素节点4,9。节点6独立为根节点的第二个孩子。
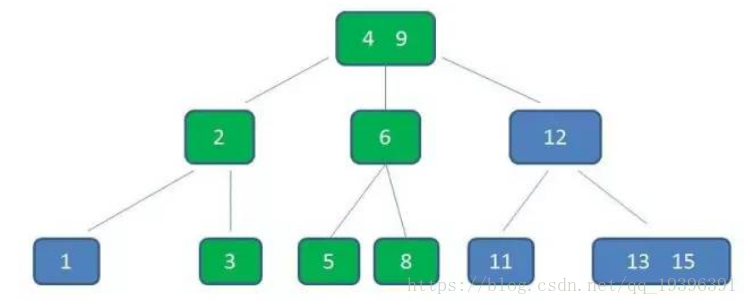
保持自平衡。
B树删除:(举例)
删除11,自顶向下查找元素11的节点位置。
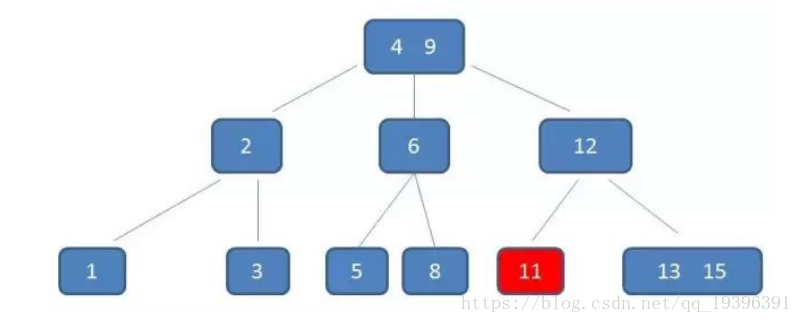
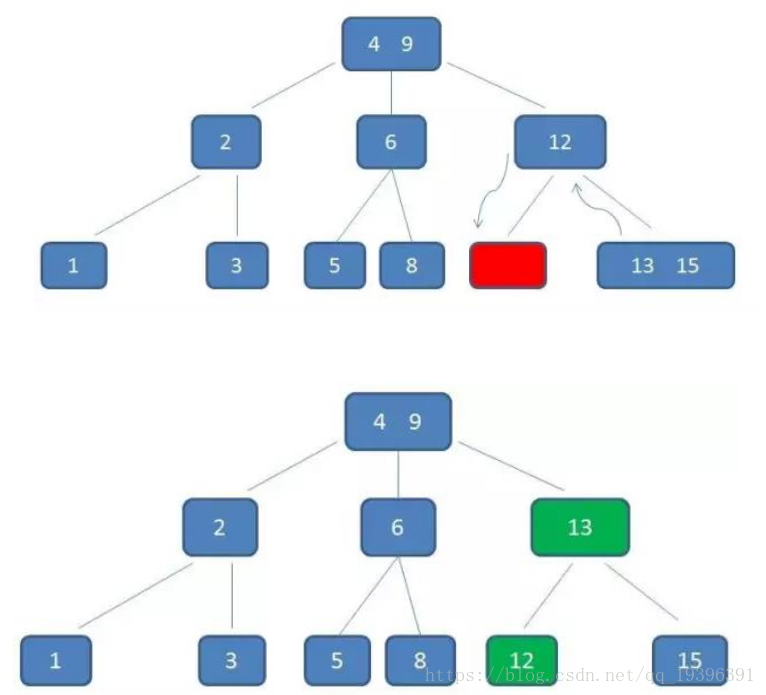
删除11后,节点12只有一个孩子,不符合B树规范。因此找出12,13,15三个节点的中位数13,取代节点12,而节点12自身下移成为第一个孩子。(这个过程称为左旋)
7.参考文献
https://mp.weixin.qq.com/s/jz1ajDUygZ7sXLQFHyfjWA
8.更多讨论
1.二叉树与二叉查找树区别?
答:二叉查找树是基于二叉树的,二叉查找树左面所有子树节点均小于或等于自己,右面的反之。
2.二叉树中序遍历代码实例?
@Override
public void postOrder(Node rootNode) {
// TODO Auto-generated method stub
if (rootNode != null) {
this.postOrder(rootNode.leftChild);
this.postOrder(rootNode.rightChild);
System.out.println(rootNode.key + " " + rootNode.value);
}
}3.为什么索引不用二叉查找树用B树?
刚已讲过,虽然二叉树从逻辑算法上看,比较次数是最少的,但是还要考虑磁盘IO问题,B树的比较多发生在内存,而且减少了IO,反而更能提升查找效率。
感谢观看,如有出错,恳请指正
BY : LittleSong