前言:
过拟合是由于模型过于精确的匹配了特定的训练数据集,导致模型不能良好的拟合其他数据或预测未来的结果,我们可以通过一些手段来防止过拟合。
一、过拟合的概念:
深度学习的过拟合通常是知针对设计好的深度学习网络,在使用训练数据集训练的时候可以获得很高的识别精度或很低的误差,但是在对测试集进行预测时,预测效果不理想。
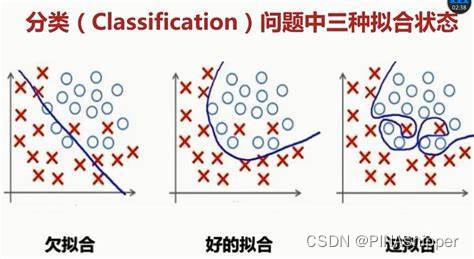
正如上图所示,虽然过拟合模型对于训练集可以做到极其准确,但是在预测全新的测试数据会有很高的错误率。
二、防止过拟合的方法
1.增加数据量:
更多的训练样本通常会使模型更加的稳定,所以训练样本的增加不仅可以得到更有效的训练结果,也能在一定程度上防止模型过拟合,增强网络的泛化能力。
如果训练样本有限,可以通过数据增强技术来扩充现有的数据集,比如在图像分类任务中使用平移、旋转、缩放等手段对数据进行扩充。
2.合理的数据切分:
在训练深度学习网络时,可以将数据集切分为数据集、验证集、测试集,使用训练集来训练网络模型;使用验证集来监督网络的学习过程,可以在网络过拟合之前终止网络的训练;使用测试集在模型训练结束后检测模型的泛化能力。
3.正则化方法:
正则化方法通常是在损失函数上添加对训练参数的惩罚范数,通过添加的范数惩罚对需要训练的参数进行约束,从而防止模型过拟合。
常用的正则化范数有: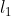 范数和
范数和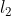 范数,其中范数的作用是:将参数的绝对值最小化,会倾向于使用更少的参数,而其他的参数都是0,从而增加网络稀疏性防止过拟合; 范数的作用是:将参数的平方和最小化,会倾向与使用更多的参数,但都趋近于0,防止模型过拟合。
范数,其中范数的作用是:将参数的绝对值最小化,会倾向于使用更少的参数,而其他的参数都是0,从而增加网络稀疏性防止过拟合; 范数的作用是:将参数的平方和最小化,会倾向与使用更多的参数,但都趋近于0,防止模型过拟合。
在实际应用中,一般使用范数进行正则化约束。在经典的线性回归模型中,使用范数的叫做Lasso回归,使用范数的叫做Ridge回归。
4.引入Dropout层:
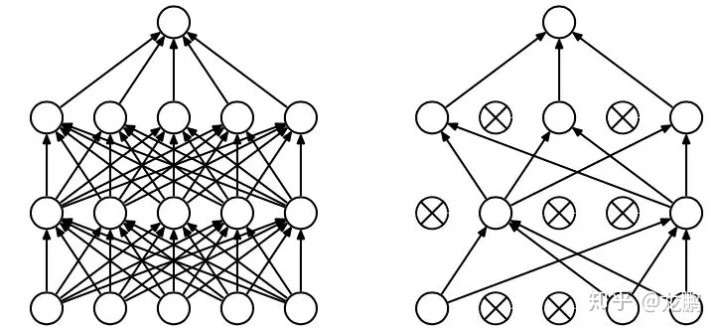
在深度学习网络中最常用的正则化技术是引入Dropout层,即在每个训练批次中通过忽略一定百分比的神经元数量,减轻网络的过拟合现象。就是说,在网络进行前向传播1过程中,某个神经元的激活值以概率p停止工作,这样可以是模型泛化性更强,鲁棒性更强。
如图所示,通过dropout操作,会随机减少网络中神经元和连接权重的数量。
5.提前结束训练:
防止过拟合最直观的方式就是提前结束训练,通常我们将数据集切分为训练集、验证集、测试集。例如当网络在验证集的损失不再减小或精度不再增加时,我们就认为网络已经训练充分,提前终止网络的训练。
但是,提前训练操作可能会得到没有训练充分的参数。