I. 前言
在PyTorch搭建LSTM实现多变量多步长时间序列预测(一):直接多输出中介绍了直接单输出的多步预测,本篇文章主要介绍单步滚动预测实现多步预测。
系列文章:
- 深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)
- PyTorch搭建LSTM实现时间序列预测(负荷预测)
- PyTorch搭建LSTM实现多变量时间序列预测(负荷预测)
- PyTorch搭建双向LSTM实现时间序列预测(负荷预测)
- PyTorch搭建LSTM实现多变量多步长时间序列预测(一):直接多输出
- PyTorch搭建LSTM实现多变量多步长时间序列预测(二):单步滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(三):多模型单步预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(四):多模型滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
- PyTorch中实现LSTM多步长时间序列预测的几种方法总结(负荷预测)
- PyTorch-LSTM时间序列预测中如何预测真正的未来值
- PyTorch搭建LSTM实现多变量输入多变量输出时间序列预测(多任务学习)
- PyTorch搭建ANN实现时间序列预测(风速预测)
- PyTorch搭建CNN实现时间序列预测(风速预测)
- PyTorch搭建CNN-LSTM混合模型实现多变量多步长时间序列预测(负荷预测)
- PyTorch搭建Transformer实现多变量多步长时间序列预测(负荷预测)
- PyTorch时间序列预测系列文章总结(代码使用方法)
- TensorFlow搭建LSTM实现时间序列预测(负荷预测)
- TensorFlow搭建LSTM实现多变量时间序列预测(负荷预测)
- TensorFlow搭建双向LSTM实现时间序列预测(负荷预测)
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(一):直接多输出
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(二):单步滚动预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(三):多模型单步预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(四):多模型滚动预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
- TensorFlow搭建LSTM实现多变量输入多变量输出时间序列预测(多任务学习)
- TensorFlow搭建ANN实现时间序列预测(风速预测)
- TensorFlow搭建CNN实现时间序列预测(风速预测)
- TensorFlow搭建CNN-LSTM混合模型实现多变量多步长时间序列预测(负荷预测)
II. 单步滚动预测
比如前10个预测后3个:我们首先利用[1…10]预测[11’],然后利用[2…10 11’]预测[12’],最后再利用[3…10 11’ 12’]预测[13’],也就是为了得到多个预测输出,我们直接预测多次,并且在每次预测时将之前的预测值带入。这种方法的缺点是显而易见的:由于每一步的预测都有误差,将有误差的预测值带入进行预测后往往会造成更大的误差,让误差传递。利用这种方式预测到后面通常预测值就完全不变了。
III. 代码实现
3.1 数据处理
我们根据前24个时刻的负荷以及该时刻的环境变量来预测接下来12个时刻的负荷(步长pred_step_size可调)。
3.2 模型搭建
模型和之前的文章一致:
classLSTM(nn.Module):def__init__(self, input_size, hidden_size, num_layers, output_size, batch_size):super().__init__()
self.input_size= input_size
self.hidden_size= hidden_size
self.num_layers= num_layers
self.output_size= output_size
self.num_directions=1# 单向LSTM
self.batch_size= batch_size
self.lstm= nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True)
self.linear= nn.Linear(self.hidden_size, self.output_size)defforward(self, input_seq):
batch_size, seq_len= input_seq.shape[0], input_seq.shape[1]
h_0= torch.randn(self.num_directions* self.num_layers, self.batch_size, self.hidden_size).to(device)
c_0= torch.randn(self.num_directions* self.num_layers, self.batch_size, self.hidden_size).to(device)
output, _= self.lstm(input_seq,(h_0, c_0))
pred= self.linear(output)
pred= pred[:,-1,:]return pred3.3 模型训练/测试
模型训练代码和之前一致,模型滚动测试代码如下:
defss_rolling_test(args, Dte, path, m, n):"""
:param args:
:param Dte:
:param path:
:param m:
:param n:
:return:
"""
pred=[]
y=[]print('loading models...')
input_size, hidden_size, num_layers= args.input_size, args.hidden_size, args.num_layers
output_size= args.output_sizeif args.bidirectional:
model= BiLSTM(input_size, hidden_size, num_layers, output_size, batch_size=args.batch_size).to(device)else:
model= LSTM(input_size, hidden_size, num_layers, output_size, batch_size=args.batch_size).to(device)# models = LSTM(input_size, hidden_size, num_layers, output_size, batch_size=args.batch_size).to(device)
model.load_state_dict(torch.load(path)['models'])
model.eval()print('predicting...')
Dte=[xfor xiniter(Dte)]
Dte= list_of_groups(Dte, args.pred_step_size)#for sub_itemin tqdm(Dte):
sub_pred=[]for seq_idx,(seq, label)inenumerate(sub_item,0):
label=list(chain.from_iterable(label.data.tolist()))
y.extend(label)if seq_idx!=0:
seq= seq.cpu().numpy().tolist()[0]iflen(sub_pred)>=len(seq):for tinrange(len(seq)):
seq[t][0]= sub_pred[len(sub_pred)-len(seq)+ t]else:for tinrange(len(sub_pred)):
seq[len(seq)-len(sub_pred)+ t][0]= sub_pred[t]else:
seq= seq.cpu().numpy().tolist()[0]# print(new_seq)
seq=[seq]
seq= torch.FloatTensor(seq)
seq= MyDataset(seq)
seq= DataLoader(dataset=seq, batch_size=1, shuffle=False, num_workers=0)# print(new_seq)
seq=[xfor xiniter(seq)][0]# print(new_seq)with torch.no_grad():
seq= seq.to(device)
y_pred= model(seq)
y_pred=list(chain.from_iterable(y_pred.data.tolist()))# print(y_pred)
sub_pred.extend(y_pred)
pred.extend(sub_pred)
y, pred= np.array(y), np.array(pred)
y=(m- n)* y+ n
pred=(m- n)* pred+ nprint('mape:', get_mape(y, pred))
plot(y, pred)简单解释一下上述滚动测试的代码:由于我们是前24个时刻预测未来12个时刻,数据的batch_size我们可以设置为1,然后每12个batch的数据放到一组:
Dte=[xfor xiniter(Dte)]
Dte= list_of_groups(Dte, args.pred_step_size)其中list_of_groups:
deflist_of_groups(data, sub_len):
groups=zip(*(iter(data),)* sub_len)
end_list=[list(i)for iin groups]
count=len(data)% sub_len
end_list.append(data[-count:])if count!=0else end_listreturn end_listlist_of_groups的作用是将列表data中的数据每seq_len划分为一组,对应到本文中就是每12个batch的数据为一组。
正式预测时分为两种情况:如果预测的是每组(共12个样本)的第一个样本,那么直接预测,并将预测值保存到sub_pred中。如果不是预测第一个样本且之前已经预测了len个样本,那么就将当前样本对应的后len个负荷值替换为sub_pred中的值:
for sub_itemin tqdm(Dte):
sub_pred=[]for seq_idx,(seq, label)inenumerate(sub_item,0):# 每个seq的batch都为1
label=list(chain.from_iterable(label.data.tolist()))
y.extend(label)if seq_idx!=0:
seq= seq.cpu().numpy().tolist()[0]# 如果当前预测长度已经大于seq,直接用sub_pred的后几个将seq中每个数组的第一个数字替换掉iflen(sub_pred)>=len(seq):for tinrange(len(seq)):
seq[t][0]= sub_pred[len(sub_pred)-len(seq)+ t]else:# 否则, seq的后几个用sub_pred代替for tinrange(len(sub_pred)):
seq[len(seq)-len(sub_pred)+ t][0]= sub_pred[t]else:# 第一个直接预测
seq= seq.cpu().numpy().tolist()[0]3.4 实验结果
训练了50轮,前24个时刻预测未来12个负荷值,单步滚动预测,MAPE为10.62%: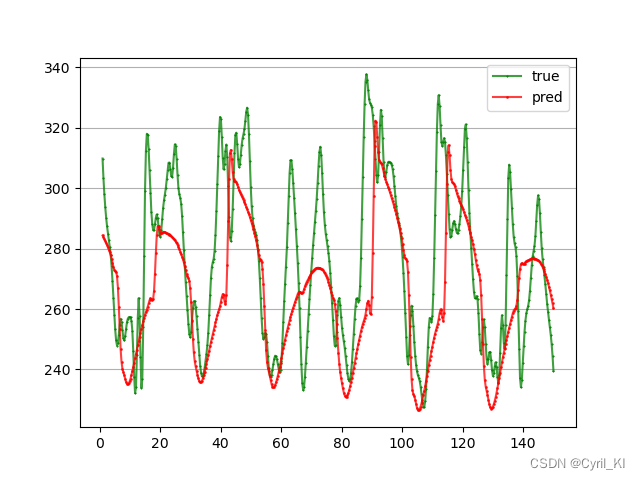
效果还比较差,需要调调参,后续再更新了。
IV. 源码及数据
后面将陆续公开~