众所周知,GPU本身的计算能力是越来越强大,特别是新一代的NVIDIA AMPERE架构发布之后,又一次刷新了大家对AI算力的认知。目前,确实有不少大规模分布式训练对更大算力的渴求是极其强烈的,比如语音、自然语言处理等。
但是,我们也不可否认还有非常多的应用场景对算力的需求不大,比如:
- AI推理场景,基本都是在线实时计算,要求延时低,batchsize小,计算量不大。
- AI开发机场景,团队内部共享GPU,对算力要求低。
这些场景的分布非常广泛,在这些场景下,AI应用是无法把GPU强大的计算能力全部发挥出来的。所以,长期以来,很多用户的GPU利用率都不高,基本都只有10%-30%。
一、什么是GPU利用率
GPU利用率是反馈GPU上各种资源繁忙程度的指标。GPU上的资源包括:
- GPU core:CUDA core, Tensor Core ,integer, FP32 core,INT32 core等。
- frame buffer:capacity, bandwidth。
- 其他:PCIe RX / TX, NVLink RX / TX, encoder和decoder等。
通常,我们说GPU利用率泛指GPU core的利用率。
二、监控GPU利用率的方式
①一般采用nvidia-smi或NVML。这两个工具在GPU驱动里面自带,使用方便,因此应用最为广泛。
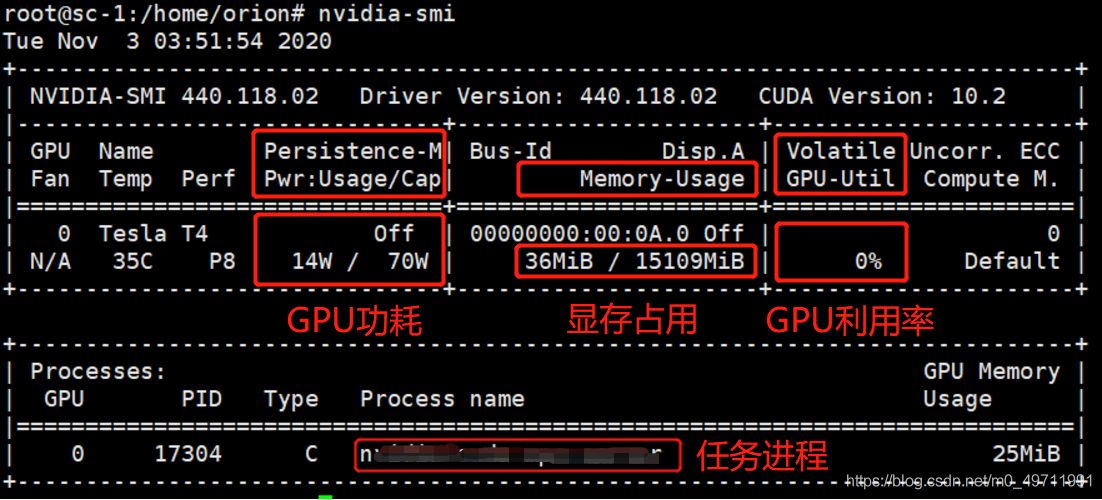
如图所示,可以一目了然监控到GPU的功耗,显存占用,GPU利用率等关键指标。
在这当中,GPU利用率指标可以反馈出GPU内核在过去的采样周期中一个或多个内核在 GPU 上执行的时间百分比。应该说这个指标还是比较粗放的,举个极端的例子:在过去的采样周期中,即使只有一个线程在一个GPU core上跑,哪怕像V100有5120个core,采样结果也会显示100%。从这个角度可以倒推得到一个结论,真实的GPU利用率恐怕会更低一些。
②更细化的监控工具:DCGM(Data Center GPU Manager )。这个是一个独立的软件包,是基于NVML的高级监控工具。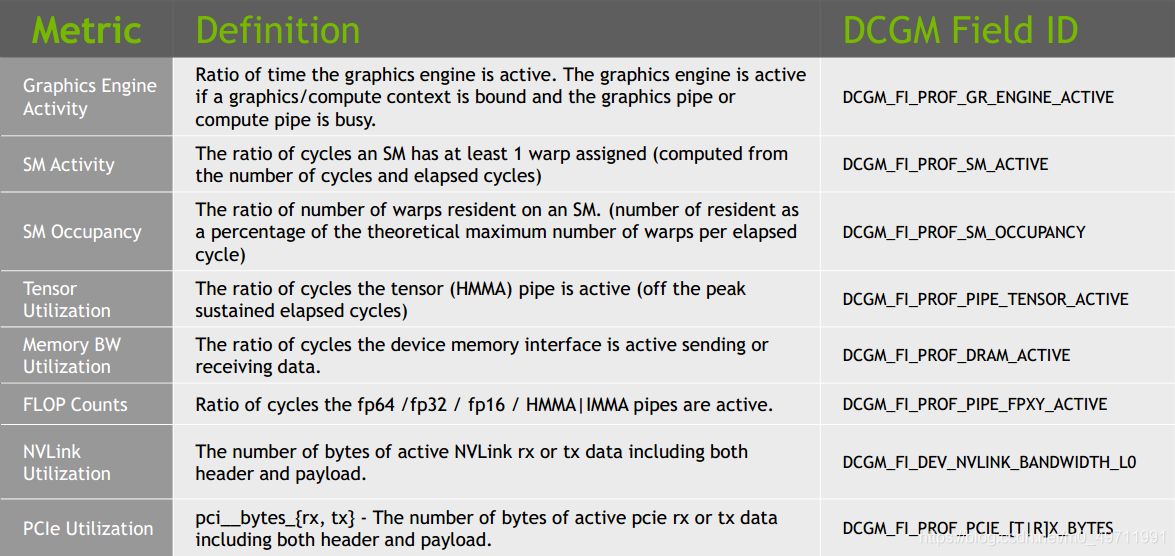
如图所示,DCGM可以监控的精度更细,维度更广,可以更真实的反馈出GPU资源的真实使用情况。DCGM可以同时支持命令行方式和C语言/Python语言的调用。目前有不少企业根据自身业务特点,基于DCGM结合K8S的Prometheus,对GPU进行实时采样和全方位监控。
三、如何提高GPU利用率
算力昂贵,不容浪费。因此,如何提高 GPU 利用率、充分释放 GPU 计算能力成为眼下备受瞩目的话题之一。下面,我们从业界广为流传的方案中,梳理几个比较有代表性的方案进行讨论。
①MIG(MULTI-INSTANCE GPU)
随着AMPERE架构的发布,NVIDIA推出了划时代的产品–A100,性能达到前所未有的高度。从性能压榨的角度讲,普通的一个AI应用要想把全部A100性能发挥出来是很难的。反过来说,大量资源没用上,闲置就是浪费。
因此,MIG(multi-Instance GPU)就这样应运而生了。
MIG 打破了原有 GPU 资源的分配方式,能够基于 A100 从硬件层面把一个GPU切分成最多 7 个 GPU 实例,并且可以使每一个 GPU 实例都能够拥有各自的 SMs 和内存系统。简单理解就是现在可以并发的同时跑7个不同的AI应用,最大程度把强大的GPU资源全部用上。
由于是基于硬件切分的方式,MIG可以让每个GPU实例之间的内存空间访问互不干扰,保障每一个使用者的工作时延和吞吐量都是可预期的。
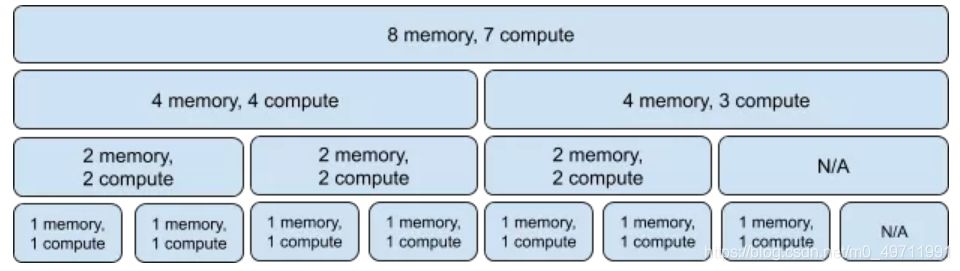
由于采用的是硬切分的方式,GPU实例之间的隔离度很好,但是灵活度就比较受限了。MIG的切分方式,每个GPU实例的大小只能按照固定的profile来切分:
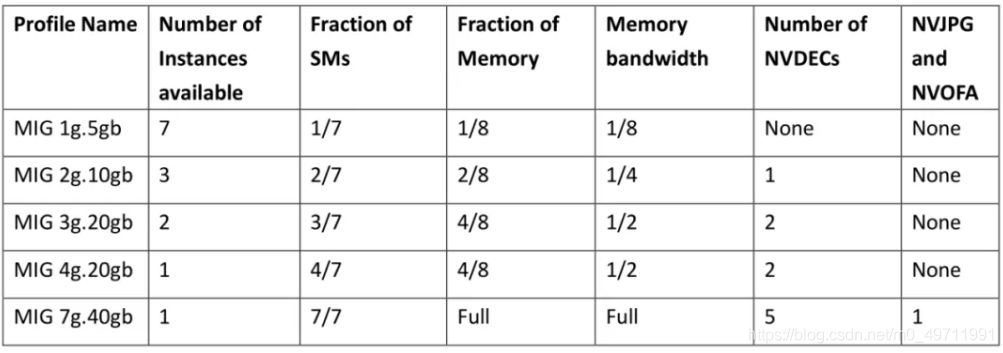
这个表格清晰的展示了各种不同大小的 GPU 实例他们具备的流处理器比例、内存比例、以及可以分配的数量。
各种profile的组合方式也是非常有限的,如下图所示:
②MPS(MULTI-PROCESS SERVICE )
MPS,包含在CUDA工具包中的多进程服务。它是一组可以替换的,二进制兼容的CUDA API实现,包括3个模块:
- 守护进程,用于启动或停止MPS服务进程, 同时也负责为用户进程和服务进程之间建立连接关系
- 服务进程, 多个用户在单个GPU上面的共享连接,为多个用户之间执行并发的服务
- 用户运行时,集成在CUDA driver库中,对于CUDA应用程序来说,调用过程透明
当用户希望在多进程条件下发挥GPU的并发能力,就可以使用MPS。MPS允许多个进程共享同一个GPU context。这样可以避免上下文切换造成的额外的开销,以及串行化执行带来的时间线拉长。同时,MPS还允许不同进程的kernel和memcpy操作在同一GPU上并发执行,以实现最大化GPU利用率 。
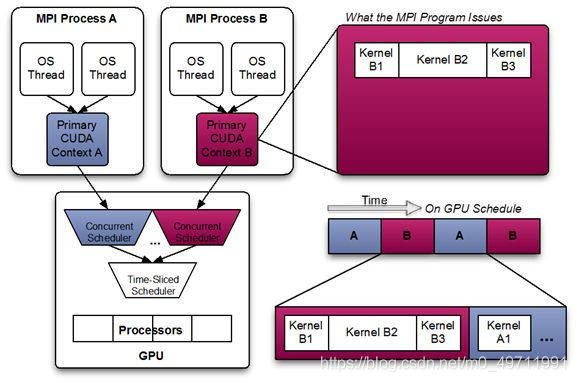
具体可以用下面2个图片对比来说明MPS的特点。
首先,在没有开启MPS的情况下,有两个进程A(蓝色)和B(红色),每个进程都有自己的CUDA context。从图中可以看到,两个进程虽然同时被发送,但是在实际执行中是被串行执行的,两个进程会被GPU中的时间片轮转调度机制轮流调度进GPU进行执行。这就是执行的时间线被拉长的原因。
继续往下看,如果我们开启了MPS,同样是启动两个进程A(蓝色)和B(红色),MPS服务进程会将它们两个CUDA context融合到一个CUDA context里面。这就是最大的不同。两个context融合到一个之后,GPU上不存在context轮转切换,减少额外开销;而且从时间片上来看的话,进程A和B的函数是真正的实现了并发执行的。这就是MPS带来的好处。
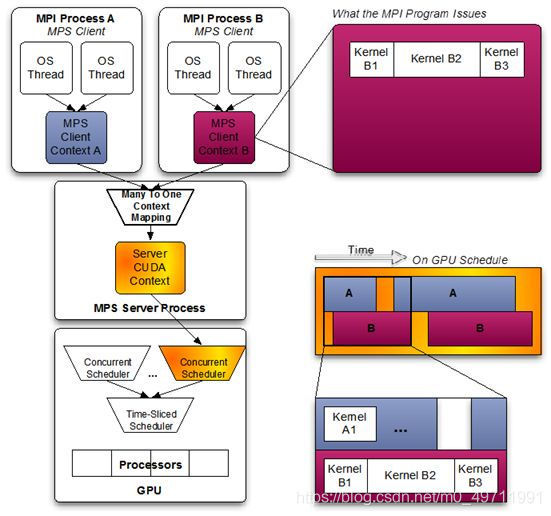
MPS的好处是显而易见的,可以提升GPU利用率,减少GPU上下文切换时间、减少GPU上下文存储空间。总的来说,就是可以充分利用GPU资源。那么,这么好的技术,为什么在业界用的很少呢?
因为MPS的context融合方式会带来一个严重的问题:错误会互相影响。一个进程错误退出(包括被kill),如果该进程正在执行kernel,那么和该进程共同share IPC和UVM的其他进程也会一同出错退出。因此无法在生产场景上大规模使用。
③OrionX(趋动科技 猎户座产品)
在提升利用率这个话题上,趋动科技的OrionX(猎户座)产品将GPU利用率提升到了极致,而且同时兼具灵活性(大小任意切分)与安全性(错误隔离)。
通过软件定义,OrionX颠覆了原有的AI应用直接调用物理GPU的架构。OrionX通过增加软件层,将AI应用与物理GPU解耦合:AI应用调用逻辑的虚拟GPU,再由OrionX将虚拟GPU需求匹配到具体的物理GPU。
灵活性:**OrionX可以将一块物理GPU细粒度切分成多块虚拟GPU,然后分配给多个虚拟机或者容器。**每一块虚拟GPU的算力和显存都能被独立设置和限制,算力切分的最小颗粒度为原物理GPU算力的1%;显存切分的最小颗粒度为1MB。算力和显存不需要等比例,没有固定profile限制。
通过这个功能,多个用户可以高效地共享GPU资源,多个应用并行运行,极大提高物理GPU利用率。
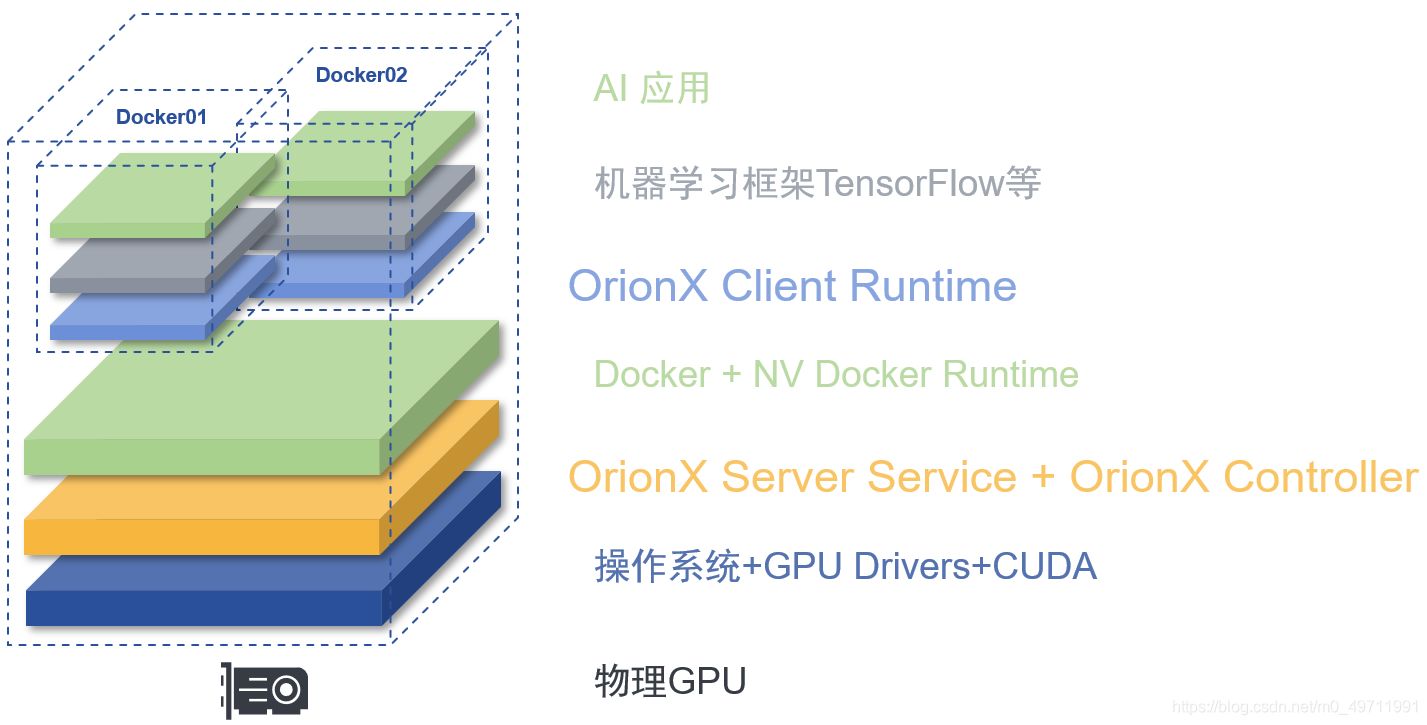
安全性:OrionX 软件包含了OrionX Controller、OrionX Server Service、OrionX Client Runtime等基本组件。
OrionX Client Runtime是一套兼容Nvidia CUDA编程环境的运行环境,用户的AI应用可以基于该环境透明无感的运行。OrionX Client Runtime部署在每一个应用环境下,支持容器、虚拟机、物理机。若干个OrionX Client Runtime之间是相互隔离,互不干扰。
OrionX Server Service发现并管理物理节点上的GPU资源,同时把物理GPU的计算能力通过OrionX的高性能私有协议提供给OrionX Client Runtime。
同样是两个进程并行计算,其中一个进程错误退出了,对另一个进程没有影响。错误进程的影响范围仅限于自己所在的OrionX Client Runtime,OrionX Server Service通过心跳检测到client异常后,会将这个client以友好的方式退出,不会影响其他进程。
正是由于OrionX采用了client/server分离的架构,因此在安全性、稳定性、隔离性以及QoS保障方面做到了企业级标准。