背景
nebula支持excel文件数据迁入,因此xxx系统可以上传从MySQL或其他工具导出的excel文件然后执行映射节点、关系导入。为了解耦和提升用户体验,过程使用kafka异步完成。
对于小数据量的情景是完全没问题的,但是一旦数据量大于100w+,由于excel单页也仅仅支持100w+数据,如6000w+甚至更多则需要拆分60多个excel显然繁琐且不太现实,因此需要实现一种快速方便的方式来完成这个小需求。
场景分析
整个迁移过程大致分为三个阶段
1、怎么尽可能快的将数据查出来?多线程数据合并问题?
2、数据查出来之后格式转化?nebula不支持的特殊字符怎么处理?
3、格式化后的数据如何保存到nebula?插入分组数量多少合适?插入失败如何处理?
1、多线程分段查数据
单表6000w+数据查询,单线程和多线程拿到数据效率哪个高呢?直觉是多线程,但是查询数据库是IO密集型的,而多线程主要是压栈CPU提升CPU密集型任务的效果明显。
实践出真知,本机代码跑一下。为了防止OOM,先用单表数据量6538587测试查询+转化nGQL格式。
单线程查询的思路代码就不说了,主要说多线程思路。代码就不再贴出来了。
// 就是开个线程池,核心线程数量根据业务场景以及服务器cpu个数设置,我这里直接设置的是20个。// 之后逻辑处理借助[CompleteableFuture异步编排工具API](https://www.liaoxuefeng.com/wiki/1252599548343744/1306581182447650)完成多线程任务的提交supplyAsyc()// 然后可以链式的处理异常、nGQL格式处理、结果集合并。// main线程将多个task放入一个list然后遍历get()阻塞等待全部线程任务处理完成即可。1.1limit分段查询
因为线程数写死20个,因此可以先查询单表数据量的总数count。
然后count % 20 是否有余数来决定每组数量count % 20 == 0? count / 20 : count / 20 + 1;
后根据id分段即可,如果表id是主键而且连续,直接使用where id <= maxPartId and id >= minPartId即可,我这里为了防止出现键值不连续的表,使用limit+offset来完成,贴下sql
<select id="selectProductBrandByInterval" resultType="xxx" parameterType="java.lang.Integer">select
idas id,
sku_idas sku_id,
brand_idas brand_idfrom xxxlimit#{offset},#{limit}</select>测试 6538587数据多线程查询+转化为nGQL处理 耗时间
- // 单个线程查询 130s
- // 10个线程查询 110s
- // 20个线程查询 110 s
效率提升还是有的,而且如果放在多cpu的服务器上效果应该会更明显。回头看看sql写的还是可以在优化的
知道limit和offst原理是先全部取,然后丢到offset前面的部分,这样随着offset的过大,丢弃的也会越多,理论效率也会更低。
为什么 offset 偏大之后 limit 查找会变慢?这需要了解 limit 操作是如何运作的,以下面这句查询为例:select * from table_name limit10000,10
这句 SQL 的执行逻辑是1.从数据表中读取第N条数据添加到数据集中2.重复第一步直到 N=10000 +103.根据 offset 抛弃前面10000 条数4.返回剩余的10 条数据
显然,导致这句 SQL 速度慢的问题出现在第二步!这前面的10000 条数据完全对本次查询没有意义,但是却占据了绝大部分的查询时间!如何解决?首先我们得了解为什么数据库为什么会这样查询。
作者:jaren
链接:https://www.jianshu.com/p/efecd0b66c55
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。1.2优化limit分段查询
当偏移量offset过大的时候,使用limit的效率就不是那么高了,可以进行优化。
(1)如果id键无序,可以使用父查询将in替换成连接查询inner join
(2)如果id键有序,可以使用id>= 、limit
先查找出需要数据的索引列(假设为 id,子查询因为只需要id字段,val会走覆盖索引。不用子查询的索引还需要回表。)再通过索引列查找出需要的数据。
贴下sql
# 父查询使用连接查询inner join ,110s<select id="selectProductBrandByIntervalImprove" resultType="xxx" parameterType="java.lang.Integer">select
idas id,
sku_idas sku_id,
brand_idas brand_idfrom xxxinnerjoin(select idfrom xxxlimit#{offset},#{limit}) b using (id)</select># 父查询id>=子查询<select id="selectProductBrandByIntervalImprove" resultType="xxx" parameterType="java.lang.Integer">select
idas id,
sku_idas sku_id,
brand_idas brand_idfrom xxxwhere id>=(select idfrom xxxlimit#{offset},1) limit #{limit}</select>效率,在Navicat禁用cache效率提升不少,但是java来跑效果相差不大。
- // 20个线程优化limit(父查询使用inner join)查询 —》110s
- // 20个线程优化limit(父亲查询id有序,直接>=子查询)—》113 s
2、合并结果完成迁移
每个线程任务查询出来数据,然后转化为List<String> ,需要注意的就是nebula不支持特殊字符的替换(如单引号、逗号、转义斜杠、中英文括号等都要替换,而且建议nGQL语句插入字符串使用单引号而不是双引号,防止转义插入失败)
每个item就是一个1000条记录的nGQL插入组。多线程合并,需要用线程安全的CopyOnWriteList集合。当然在600w+数据的时候整个查询、转化、插入都没问题,在后续单表6000w+数据的时候出现问题。
只有部分线程能查询成功,大概1000w+数据,而且转化nGQL过程直接抛出 heap OOM异常。
使用jps、jmap、jconsole分析内存,修改默认的最大堆内存从4G改为-Xmx6044m,发现能到2000w左右的查询就又OOM了,因此在本机内存条件有限的情况下只能另外想办法了。
结合业务可以推断出,新生代频繁GC,老年代内存过高,导致OOM,而老年代内存不断波动结合业务分析应该是CopyOnWriteList的原因,每个线程查询结果都要汇总到CopyOnWriteList。
根据数据初步分析,一个Java Object占的内存大小应该为16Bytes,加上对象中的String 成员属性5个,共占4Bytes * 5 + 16Bytes = 36Bytes。6000w+个对象需要:6000w+ * 36bytes / 1024 / 1024 = 2059M,大致也就是2G多,而且还有List<String>集合和CopyOnWriteList的备份复制等需要大量内存。
而默认的-Xmx1024参数指定的堆内存只有1G,显然不够用,频繁的发生400多次young gc 对象都堆积到了老年代。
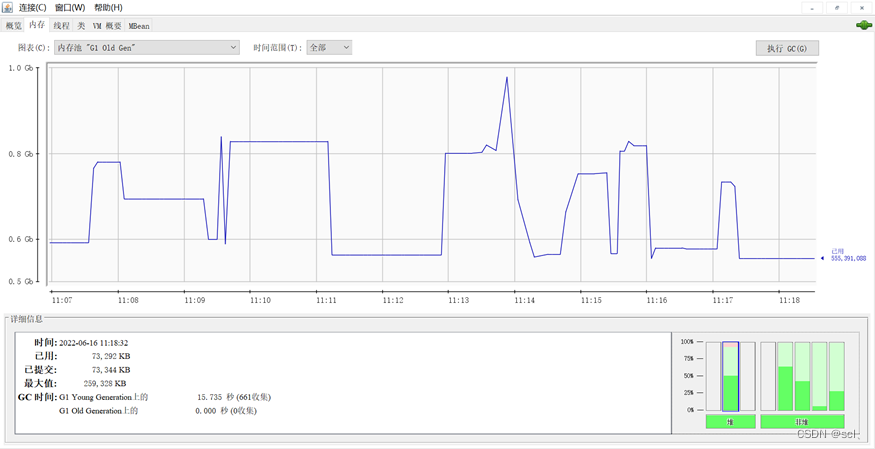
最后靠着根据id分组,每次处理1000w+数据,共跑了6次串行才解决。
下面是使用JVM内存分析工具进行分析的一些命令步骤。
累计导入数量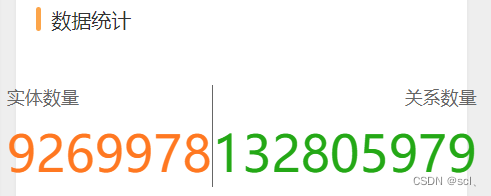
3、JVM内存分析
一、工具
1、jps:查看java进程号pid2、jconsole:可视化界面,查看内存,线程数等。3、jmap:生成dump文件# 或者可以手动的直接生成dump文件,使用mat分析或者在线网站# 拿到dump文件下一步就是分析,由于电脑上没有JDK环境,下载的MAT工具也报错。# 所以可以使用在线的一个dump分析网站:https://heaphero.io/index.jsp或者是https://gceasy.io/index.jsp
jmap -dump:format=b,file=heap.dump8544
Dumping heap to D:\myidea_projects\data-conversion\data-conversion\heap.bin...
Heap dumpfile created[1141143851 bytesin10.996 secs]二、参数
# 1、使其发生OOM时候生成dump文件# 让JVM在遇到OOM(OutOfMemoryError)时生成Dump文件
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/heap/dump# 2、打印GC日志
-XX:+PrintGCDetails