多GPU并行
torch.nn.DataParallel
使用非常简单,基本只需添加一行代码就可扩展到多GPU。
如果想限制GPU使用,可以设置os.environ['CUDA_VISIBLE_DEVICES'] = "0, 2, 4",注意程序执行时会对显卡进行重新编号,不一定跟实际完全对应。
device= torch.device("cuda:0"if torch.cuda.is_available()else"cpu")if torch.cuda.device_count()>1:print("Let's use ", torch.cuda.device_count(),"GPUs.")
model= nn.DataParallel(model)
model.to(device)# 等价于 model = model.to(device)
data= data.to(device)# 注意:数据必须要有赋值,不能写成 data.to(device)显存不平衡问题:模型是保存在第0卡上的,计算loss的梯度也默认在0卡上。所以第0卡会比其他的卡占用更多显存,尤其是当模型比较大的时候。这样会限制整体batch_size的大小,同时其余卡的显存也没有完全利用。解决方案是BalancedDataParallel和DistributedDataParallel。
原理:首先把模型放在第0块卡上,然后通过nn.DataParallel找到所有可用的显卡并将模型进行复制。运行时将每个batch的数据平均分到不同GPU进行forward计算,将loss汇总到第0卡反向传播,最后将更新后的模型参数再复制到其他GPU中。所以要求batch_size >= GPU数量。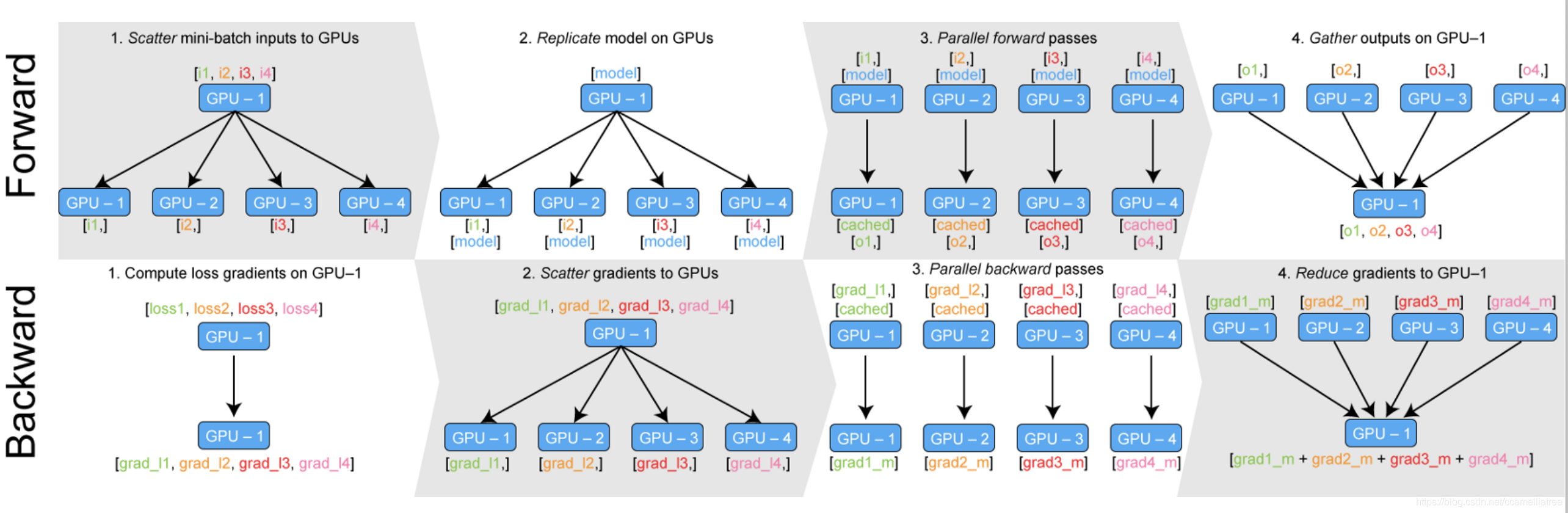
BalancedDataParallel
代码:有大佬改进了transformer-XL的源码(GitHub)
做法是自己实现一个继承自DataParallel的BalancedDataParallel类,手动调整每个batch数据在多GPU的分配,然后就可以指定第0卡少处理一些数据,从而充分利用每块卡的显存。
用法与DataParallel完全一样,只需要换成下面这行即可,需要指定第0卡处理的数据量。
model= BalancedDataParallel(gpu0_bsz// acc_grad, model, dim=0)这里包含三个参数, 第一个参数是第一个GPU要分配多大的batch_size, 但是要注意, 如果你使用了梯度累积, 那么这里传入的是每次进行运算的实际batch_size大小.
举个例子, 比如你在3个GPU上面跑代码, 但是一个GPU最大只能跑3条数据, 但是因为0号GPU还要做一些数据的整合操作, 于是0号GPU只能跑2条数据, 这样一算, 你可以跑的大小是2+3+3=8, 于是你可以设置下面的这样的参数:
batch_szie = 8,gpu0_bsz = 2,acc_grad = 1
这个时候突然想跑个batch size是16的怎么办呢, 那就是4+6+6=16了, 这样设置累积梯度为2就行了:
batch_szie = 16,gpu0_bsz = 4,acc_grad = 2
torch.nn.parallel.DistributedDataParallel
支持单机多卡和多机多卡,支持模型的分布式训练。
这里只研究了单机多卡,其余有待学习。单机多卡的参考代码如下:
# 初始化
torch.distributed.init_process_group(backend="nccl")
local_rank= torch.distributed.get_rank()
torch.cuda.set_device(local_rank)
device= torch.device("cuda", local_rank)# dataset增加sampler参数
videoloader= DataLoader(dataset=dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn, sampler=DistributedSampler(dataset))# 注意:先加载模型到GPU,再并行化
model.to(device)if torch.cuda.device_count()>1:print("we can use ", torch.cuda.device_count(),"GPUs.")
model= torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)注意:运行的时候要指定参数
python -m torch.distributed.launch --nproc_per_node=8 gen_embedding_gpu.pytorch.distributed.launch会触发多个GPU进程,相当于多个.py文件并行运行。
也就是说,上述单机多卡的代码在模型和数据上都并行了,即每张卡都会加载一个模型,各处理一个batch_size的数据。
显存管理
除了显存使用不平衡之外,还是会经常遇到RuntimeError: CUDA out of memory.
显存占用
模型自身的参数:不是太多,一般几十M
模型的中间变量:主要占用。
每一次操作都会计算得到一个中间变量,这些变量都会存储下来。反向传播时,由于要保存梯度,所以大概会是前向的2倍。
下图是VGG16的显存占用计算:(图中默认数据格式8bit,实际float32是32bit)
占用显存的层:卷积层,全连接层,BN层,Embedding层(有参数)
不占用显存的层:激活层,池化层,dropout层(没参数)
优化器:权重更新时,需要保存梯度变量,所以优化时,模型参数占用的显存会翻倍。
显存抢救
1、如果只forward无需反向传播(例如测试或提特征),就不用保存梯度信息,一定要用torch.no_grad
with torch.no_grad():for ii,(data, targets)in tqdm(enumerate(test_loader), desc='predict'):
loss, outputs= model(data, targets)2、及时清理不用的变量del var
3、模型运行一段时间后爆显存,可能是无用的临时变量积累太多,可以手动清理。
注意,清理之后从nvidia-smi可以看到显存占用释放了,但是pytorch可用的显存并不会增加。
try:
loss, outputs= model(data, targets)except RuntimeErroras e:if'out of memory'instr(e):print('| WARNING: ran out of memory')ifhasattr(torch.cuda,'empty_cache'):
torch.cuda.empty_cache()else:raise e如果是训练数据集中偶尔有复杂数据导致,可以跳过:
try:
loss, outputs= model(data, targets)except RuntimeErroras e:if'out of memory'instr(e):print('| WARNING: ran out of memory, skipping batch')
ooms+=1
self.zero_grad()else:raise e4、一个典型的例子,只传值,不要累积梯度
total_loss+=float(loss)5、Relu激活函数的默认参数可以设置inplace=True,计算时得到的新值不会占用新空间而是直接覆盖,可以节省一部分内存。
6、torch.utils.checkpoint拆分网络模型。
7、使用CuDNN Backend
当网络输入的size固定的时候,CuDNN能提供很多优化。
torch.backends.cudnn.benchmark=True
torch.backends.cudnn.enabled=True8、用16比特的float
model= model.half()# convert a model to 16-bitinput=input.half()# convert a model to 16-bit可能导致的问题:
1)BN层可能会不收敛,可以把BN层单独设置为float32
model.half()# convert to half precisionfor layerin model.modules():ifisinstance(layer, nn.BatchNorm2d):
layer.float()2)存储时候可能会有溢出问题,需要限制一下边界。
NVIDIA提供了一个扩展Apex帮助混合精度的训练,可以参考。