Influxdb简介
InfluxDB是用Go语言编写的高性能、高可用的分布式时序数据存储数据库,无其他依赖,安装简单快速。
该数据库现在主要用于存储涉及大量的时间戳数据,如DevOps监控数据,APP metrics, loT传感器数据和实时分析数据。
与传统数据库中的名词比较
| influxDB中的名词 | 传统数据库的概念 |
| database | 数据库 |
| measurement | 数据库中的表 |
| points | 表里面的一行数据 |
InfluxDB下载安装
下载地址:
https://portal.influxdata.com/downloads
influxDB,Nightly是每日的意思,每日构建,属于测试版本,要选择V1.7.10,点击后无反应,我是查看源码,找的下载地址,下载的(选择windows版本)。
修改influxDB配置文件
InfluxDB 的数据存储主要有三个目录。默认情况下是 meta, wal 以及 data 三个目录,服务器运行后会自动生成。
meta 用于存储数据库的一些元数据,meta 目录下有一个 meta.db 文件。
wal 目录存放预写日志文件,以 .wal 结尾。
data 目录存放实际存储的数据文件,以 .tsm 结尾。
在配置文件中找到graphite配置项,去掉前面的“#”号
[[graphite]]
# Determines whether the graphite endpoint is enabled.
enabled = true
database = "jmeter" # 数据库名称
retention-policy = ""
bind-address = ":2003" # 端口
protocol = "tcp"
consistency-level = "one"
修改以下信息
[meta]
#dir="/usr/local/influxdb/meta"
dir="D:\\ChromeDownLoad\\influxdb-1.7.10_windows_amd64\\influxdb-1.7.10-1\\meta" #存放最终存储的数据,文件以.tsm结尾
[data]
#dir = "/usr/local/influxdb/data"
dir = "D:\\ChromeDownLoad\\influxdb-1.7.10_windows_amd64\\influxdb-1.7.10-1\\data" #存放数据库元数据 wal
#wal-dir = "/usr/local/influxdb/wal"
wal-dir = "D:\\ChromeDownLoad\\influxdb-1.7.10_windows_amd64\\influxdb-1.7.10-1\\wal" #存放预写日志文件
修改HTTP端口信息
[http]
# Determines whether HTTP endpoint is enabled.
enabled = true
# The bind address used by the HTTP service.
bind-address = ":8086"为何路径会有2个反斜杠,是因为windows路径反斜杠需要转义,所以路径就需要这么写:D:\\ChromeDownLoad\\influxdb-1.7.10_windows_amd64\\influxdb-1.7.10-1\\meta
运行influxDB数据库服务器
进入安装目录,influxd -config influxdb.conf,运行后,不要关闭
运行influxDB数据库客户端
再运行influx.exe即可。
influxDB数据库操作
> show databases # 查看数据库
name: databases
name
----
_internal
jmeter
> create database "jmeter" # 创建数据库
> use jmeter #切换数据库(使用某个数据库)
Using database jmeter
>show measurements #显示所有表(无表显示空)
>show users #显示所有用户
>create user "user" with password 'user' #新增普通用户
> create user "admin" with password 'admin' with all privileges # 创建管理员权限的用户
> drop user "user" # 删除用户Grafana配置
什么是Grafana
Grafana是一款可视化工具,大多使用在时序数据的监控方面,如同Kibana类似。Grafana的UI更加灵活,有丰富的插件,功能强大,数据源可以使用zabbix、influxdb等。经常和jmeter、influxdb配合使用。
grafana的下载和安装
官网:https://grafana.com/grafana/download
下载地址:https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-5.2.1-1.x86_64.rpm
启动
进入grafana的解压路径,进入bin,直接运行grafana-server.exe即可。
浏览器访问:http://localhost:3000
grafana的默认用户名密码都是admin,第一次登录会要求更改密码。进入后首先创建数据库。

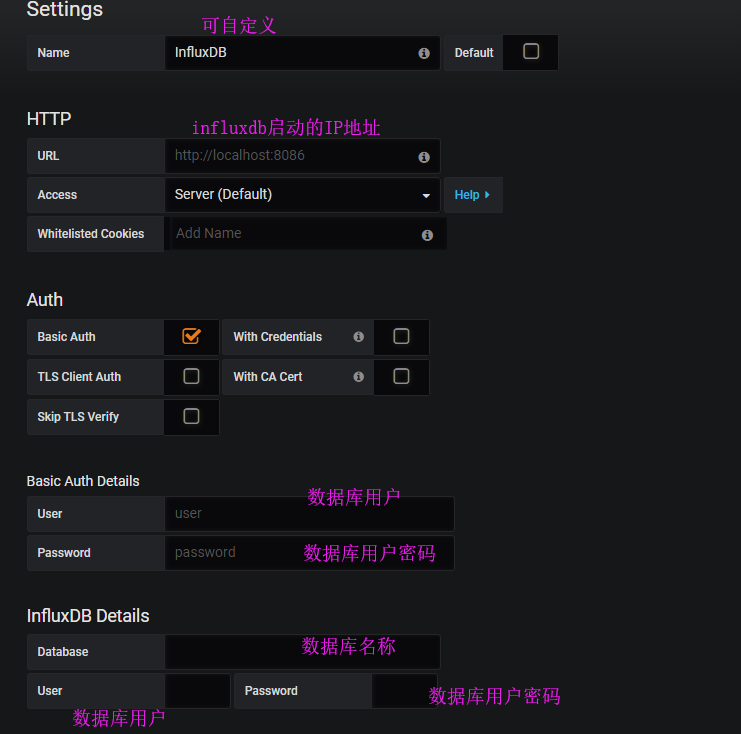
配置成功后,点击左下角的Save&Test就可以测试数据库是否连接成功。
Grafana模板
Grafana 能配出非常漂亮的监控仪表板,就是配的过程非常痛苦,反正目前我还不太会。于是采用别人设定好了的模板。
点击Import。导入模板有两种方式。
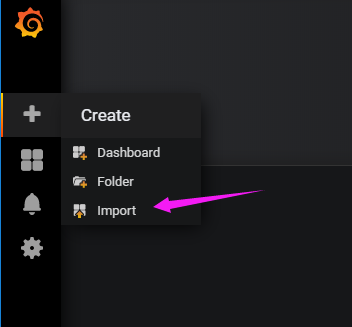
1.输入模板ID
官网模版库:https://grafana.com/dashboards
找到想要导入模板,进入详情,查看Get this dashboard:
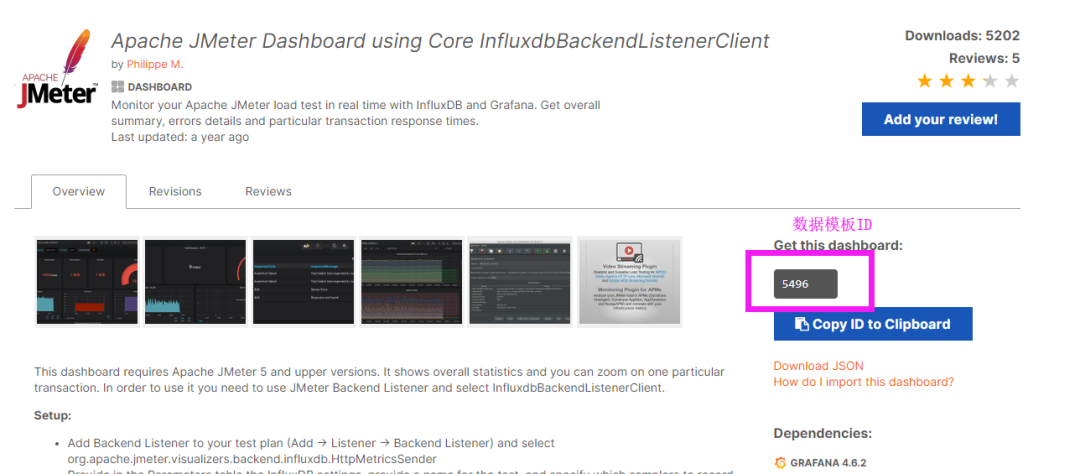
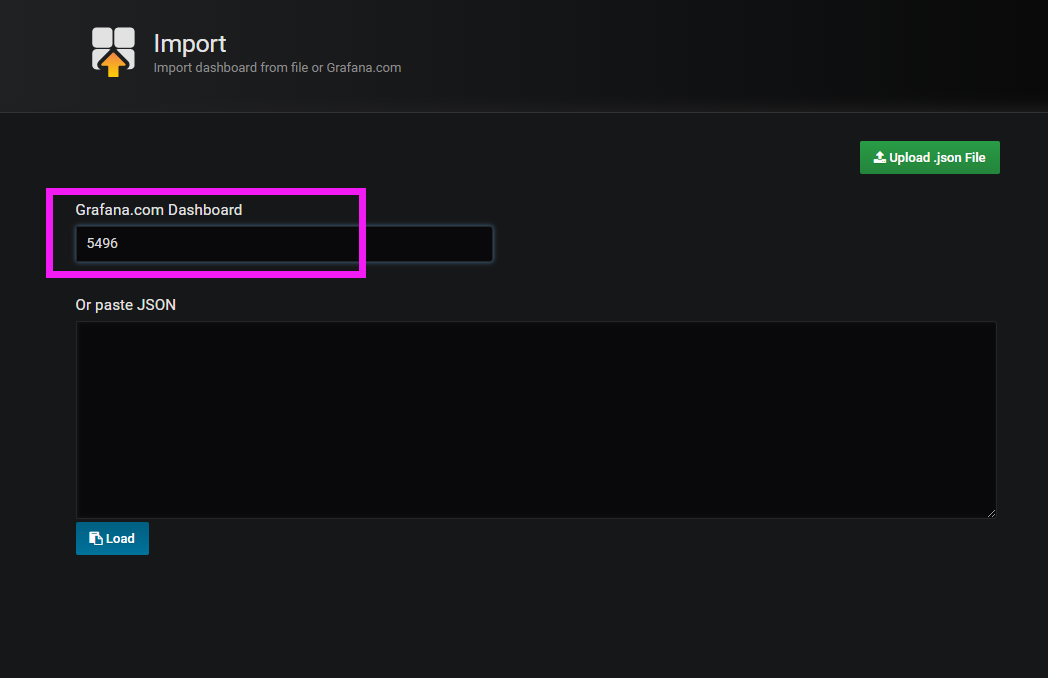
输入ID后会自动导入进入配置页面:

配置完后,点击Import即可。
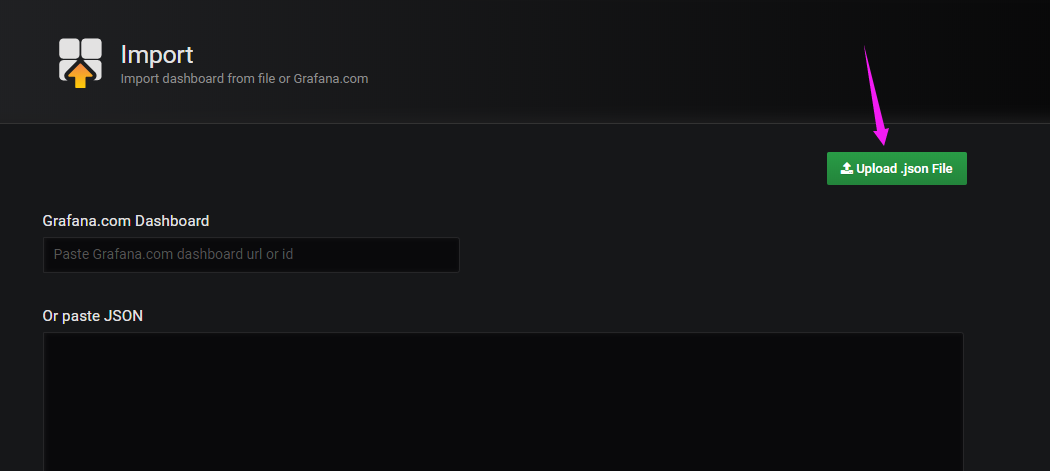
2.导入模板的json文件
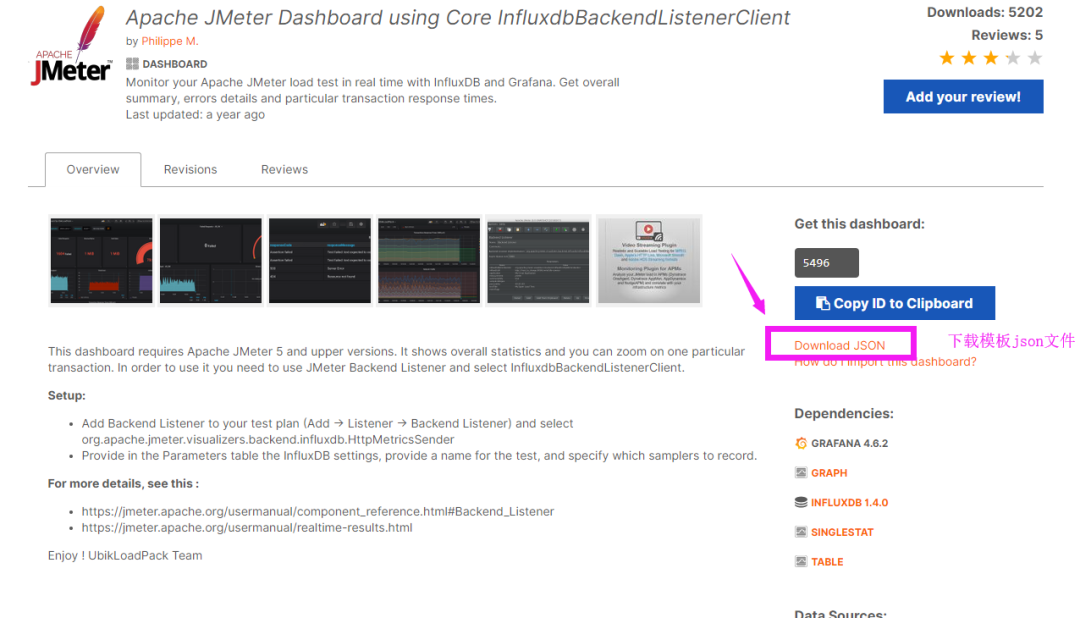
官网模版库:https://grafana.com/dashboards
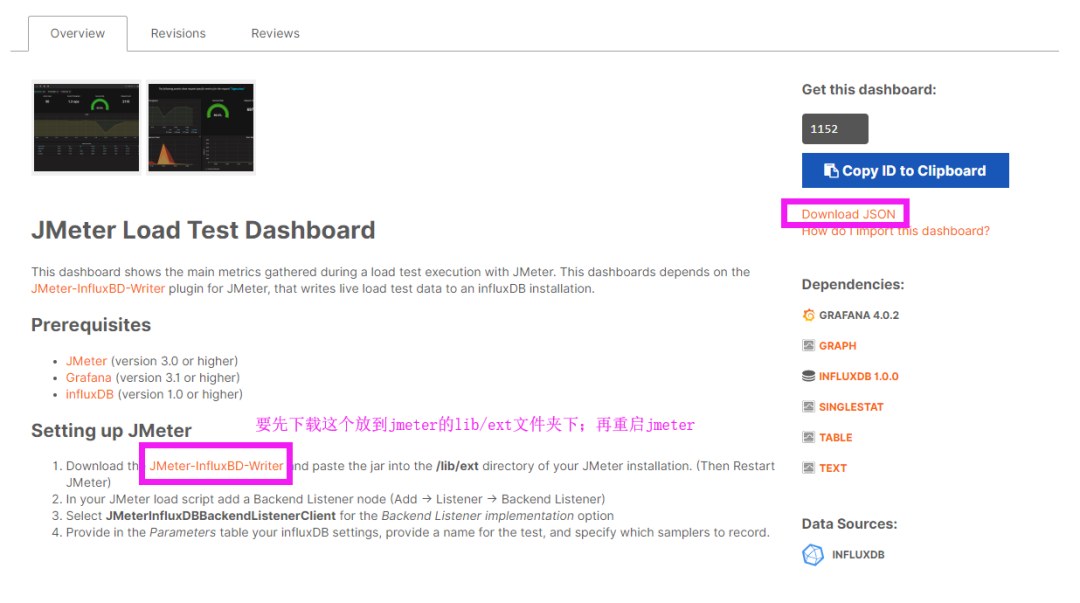
找到想要导入模板,进入详情,点击右侧的Download JSON。
下载后,进入Grafana的Import的页面,点击右上角的Upload .json File即可。导入后还是需要配置数据源,和上面通过模板ID导入配置数据源一致。
Jmeter配置(Apache JMeter Dashboard using Core InfluxdbBackendListenerClient模板,模板ID5496)
创建一个测试计划,并添加Backend Listenter(后端监听器),Backend Listener implementation 选择org.apache.jmeter.visualizers.backend.graphite.GraphiteBackendListenerClient
设置influxDB IP及端口
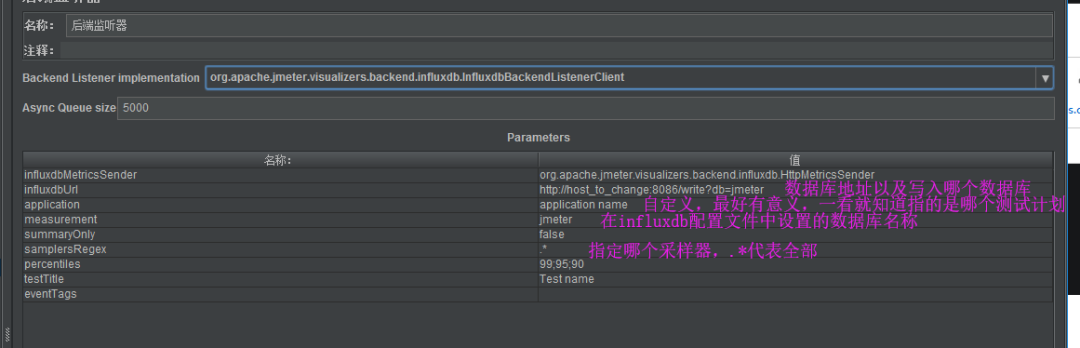
运行测试计划,在Grafana中选择对应的数据源和application就可以查看结果。
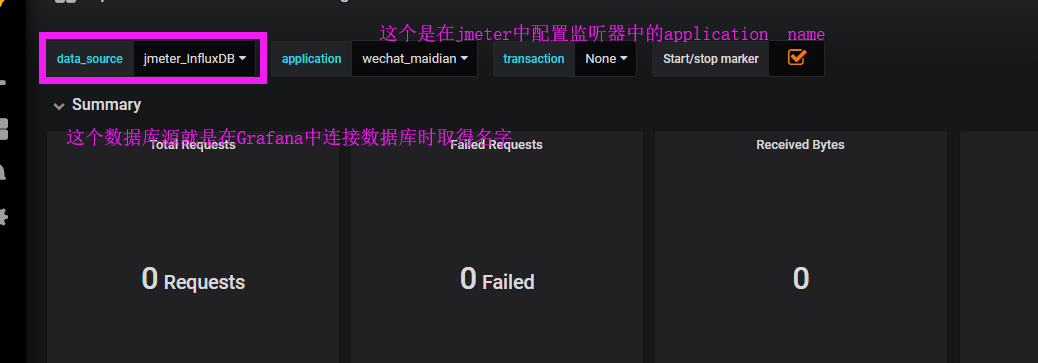
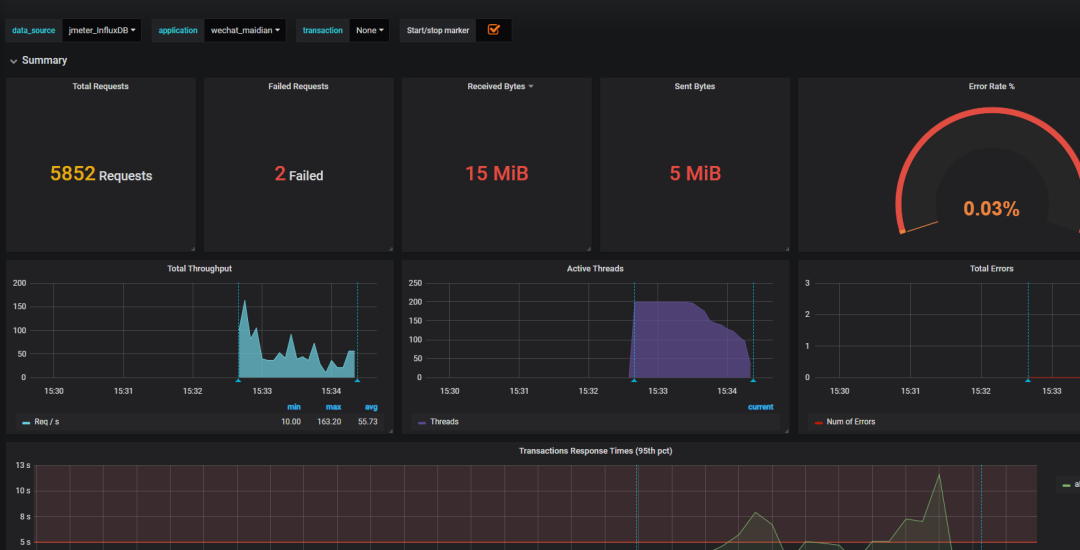
Jmeter配置( JMeter Load Test模板,模板ID1152)
不管使用什么模板,都需要先导入这个模板,按照官方说明配置即可就不多说明了。
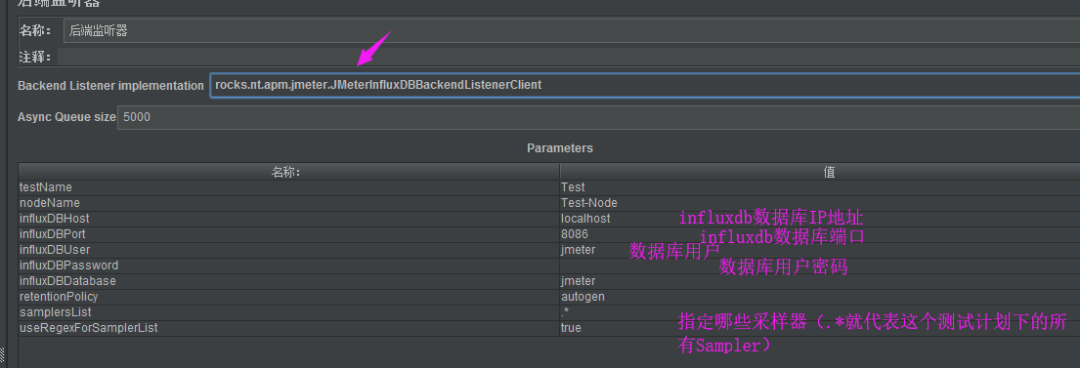
保存配置后启动测试计划;在Grafana中查看运行结果。
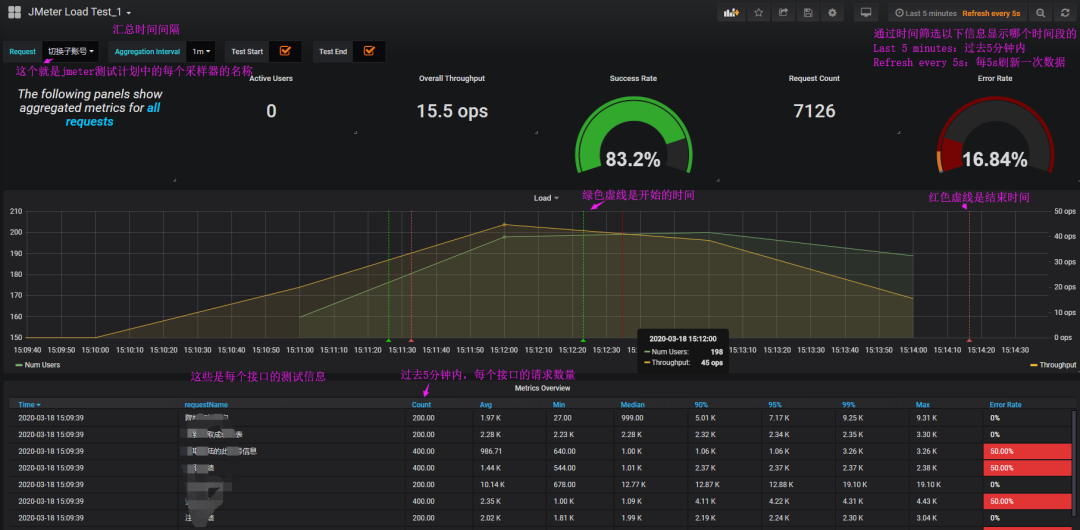
端口说明
2003端口:Jmeter往数据库发数据的端口
8086端口,Grafana从数据库取数据的端口注意:吞吐率和响应时间图表只计算成功的请求(失败的通常没意义,超时失败的能在表格里看到数量),结果可能会跟Jmeter里看到的有出入。
查看Jmeter数据库的表信息
> show databases
name: databases
name
----
_internal
jmeter
> use jmeter
Using database jmeter
> show measurements
name: measurements
name
----
jmeter.all.a.avg
jmeter.all.a.count
jmeter.all.a.max
jmeter.all.a.min
jmeter.all.a.pct90
jmeter.all.a.pct95
jmeter.all.a.pct99
jmeter.all.h.count
jmeter.all.ko.avg
jmeter.all.ko.count
jmeter.all.ko.max
jmeter.all.ko.min
jmeter.all.ko.pct90
jmeter.all.ko.pct95
jmeter.all.ko.pct99
jmeter.all.ok.avg
jmeter.all.ok.count
jmeter.all.ok.max
jmeter.all.ok.min
jmeter.all.ok.pct90
jmeter.all.ok.pct95
jmeter.all.ok.pct99
jmeter.all.rb.bytes
jmeter.all.sb.bytes
jmeter.test.endedT
jmeter.test.maxAT
jmeter.test.meanAT
jmeter.test.minAT
jmeter.test.startedT线程数/用户相关指标
test.minAT-Min active threads:最小活跃线程数
test.maxAT-Max active threads:最大活跃线程数
test.meanAT-Mean active threads:活跃线程数
test.startedT-Started threads:启动线程数
test.endedT-Finished threads:结束线程数
响应时间指标
.ok.count:采样器的成功响应数
.h.count:每秒点击数
.ok.min:采样器成功最短响应时间
.ok.max:采样器成功最长响应时间
.ok.avg:采样器成功平均响应时间
.ok.pct:采样器成功响应百分比
.ko.count:采样器失败响应数
.ko.min:采样器失败的响应最短时间
.ko.max:采样称失败最长响应时间
.ko.avg:采样器失败平均响应时间
.ko.pct:采样器失败响应百分比
.a.count:采样器响应数(ok.count和ko.count的总和)
.a.min:采样器最小响应时间(ok.count和ko.count的最小值)
.a.max:采样器最大响应时间(ok.count和ko.count的最大值)
.a.avg:采样器平均响应时间(ok.count和ko.count的平均值)
.a.pct:采样器响应百分比(根据和失败样本的总数计算)
Backend Listener的默认百分位设置为“90;95;99”,即百分位数为90%,95%和99%。
Graphite使用点(“.”)去拆分的元素,这可能与十进制百分位值混淆。JMeter转换任何此类值,用下划线(“ - ”)替换点(“.”)。例如,“99.9 ”变为“99_9 ”
默认情况下,JMeter发送在samplerName“all”下累计的所有采样器的指标。如果配置了 BackendListenerSamplersList,那么JMeter还会发送匹配样本名称的指标,前提是配置 summaryOnly=true多说无益,最好是自己操作。以上都是我自己在本地试验过再记录下来的。有很多不足希望能一起交流。
文章迁移自 www.youyoubai.com