0. 前言
上一篇博客对决策树算法的思想作了描述,也详细写了如何构造一棵决策树。现在希望用python代码来实现它。此处先调用机器学习中的算法库来实现。
2. python代码实现决策树(决策树分类器–DecisionTreeClassifier)
Example1
先用一些简单的数据来进行预测。
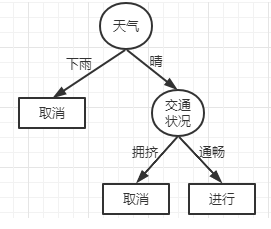
这里的数据是通过天气是否晴朗和交通是否拥堵来决定是否前往旅行;
| 天气 | 交通状况 | 是否前往 |
|---|---|---|
| 是 | 是 | 否 |
| 是 | 否 | 是 |
新的待预测的样本(阴天,)这里需要预测的这个新的样本只有一个属性,另一个属性值为空。
from sklearnimport tree# 1. 数据
X=[[1,0],[1,1]]# 1表示晴天,0表示拥堵
y=[0,1]# 标签# 2. 调用决策树模型
clf= tree.DecisionTreeClassifier()
clf= clf.fit(X, y)# 拟合# 预测
predict_y= clf.predict([[0,-1]])# -1表示这个属性为空print("新样本预测结果:", predict_y)输出结果:
新样本预测结果:[0]根据结果可以看到,根据该样本的特征,预测其标签为0,即不会前往(取消)。与实际的结果也是相符的!
from sklearnimport tree# 1. 数据
X=[[1,0],[1,1]]# 1表示晴天,0表示拥堵
y=[0,1]# 标签# 2. 调用决策树模型
clf= tree.DecisionTreeClassifier()
clf= clf.fit(X, y)# 拟合# 预测每个类的概率# predict_y = clf.predict([[0, -1]])
predict_y= clf.predict_proba([[0,-1]])# -1表示这个属性为空print("新样本预测结果:", predict_y)这段代码与上面的区别是predict_y = clf.predict_proba([[0, -1]]),这里的predict_proba表示预测每个类的概率,输出结果如下:
新样本预测结果:[[1.0.]]Example2
前边是自己创建的简单数据进行预测,这里使用已有鸢尾花数据集进行验证。
from sklearn.datasetsimport load_irisfrom sklearnimport model_selectionfrom sklearn.treeimport DecisionTreeClassifier# 加载鸢尾花数据集
dataSet= load_iris()
X= dataSet.data
y= dataSet.target# print(X)# print(y)# 划分数据集
X_trainer, X_test, Y_trainer, Y_test= model_selection.train_test_split(X, y, test_size=0.2)
clf= DecisionTreeClassifier()
clf= clf.fit(X_trainer, Y_trainer)# 拟合
predict_y= clf.predict(X_test)print("对测试集样本的预测结果:\n", predict_y)
predict_y1= clf.predict_proba(X_test)print("预测样本为某个标签的概率:\n", predict_y1)运行结果:
对测试集样本的预测结果:[211222220221011001101202111010]
预测样本为某个标签的概率:[[0.0.1.][0.1.0.][0.1.0.][0.0.1.][0.0.1.][0.0.1.][0.0.1.][0.0.1.][1.0.0.][0.0.1.][0.0.1.][0.1.0.][1.0.0.][0.1.0.][0.1.0.][1.0.0.][1.0.0.][0.1.0.][0.1.0.][1.0.0.][0.1.0.][0.0.1.][1.0.0.][0.0.1.][0.1.0.][0.1.0.][0.1.0.][1.0.0.][0.1.0.][1.0.0.]]3. python代码实现决策树(决策树回归–DecisionTreeRegressor)
- 准备数据集
# 1. 准备数据
X= np.linspace(1,5, num=300).reshape(300,1)# print(X)
y= np.sin(X)# print(y)numpy.linspace()用法:主要用于创建等差数列,这里对它的参数进行如下说明:np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
- start:表示开始数据点
- stop:表示数据结束点
- num:表示生成样本数据的数量,默认num的值为50
- endpoint:值为True表示包含数据结束点stop,为False不包含
- retstep:若为True,输出会给出公差,即数据间隔量
- dtype:输出数组的类型
这里通过一小段代码进行演示:
import numpyas np
X= np.linspace(1,3, num=5, endpoint=True, retstep=True)print(X)结果输出:
# (array([1. , 1.5, 2. , 2.5, 3. ]), 0.5)根据结果可以看到,是从1-3生成等差数列,公差为0.5,且endpoint=True,所以包含了3;
import numpyas np
X= np.linspace(1,3, num=5, endpoint=False, retstep=True)print(X)结果输出:
# (array([1. , 1.4, 1.8, 2.2, 2.6]), 0.4)根据结果可以看到,是从1-3生成等差数列,公差为0.4,且endpoint=False,所以结束点不包含3;
reshape()函数:主要用于改变数组的形状,但需要注意该函数的参数乘积要等于数组中的数据总数。
此处仍然用一小段代码演示:
import numpyas np
X= np.linspace(1,10, num=6)print("before:", X)
Y= np.linspace(1,10, num=6).reshape(6,1)print("later:\n", Y)输出结果:
before:[1.2.84.66.48.210.]
later:[[1.][2.8][4.6][6.4][8.2][10.]]由结果可以看到,我们将1X6的矩阵重新构造成了6X1的矩阵。
- 调用算法
# 2. 调用决策树模型# max_depth指明树的深度
model= DecisionTreeRegressor(max_depth=5)# 训练
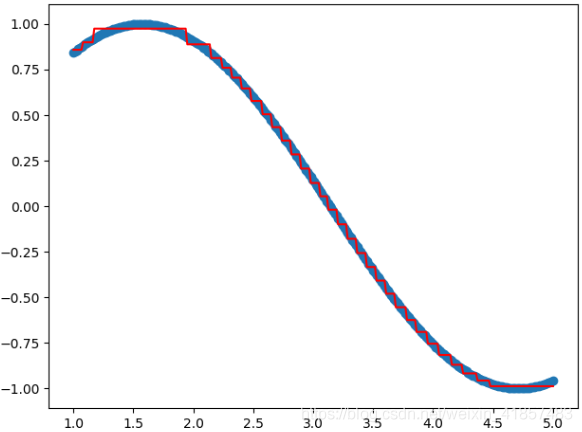
model.fit(X, y)# 3. 数据准确率,即得分print("准确率:", model.score(X, y))- 可视化
# 预测值
h5= model.predict(X)# 可视化
plt.scatter(X, y)
plt.plot(X, h5, c='r')
plt.show()- 完整代码
"""决策树算法"""import numpyas npfrom sklearn.treeimport DecisionTreeRegressorfrom matplotlibimport pyplotas plt# 1. 准备数据
X= np.linspace(1,5, num=300).reshape(300,1)# print(X)
y= np.sin(X)# print(y)# 2. 调用决策树模型# max_depth指明树的深度
model= DecisionTreeRegressor(max_depth=5)# 训练
model.fit(X, y)# 3. 数据准确率,即得分print("准确率:", model.score(X, y))# 预测值
h5= model.predict(X)# 可视化
plt.scatter(X, y)
plt.plot(X, h5, c='r')
plt.show()结果:
准确率:0.9993712866996124